Codex com GPT-5.4 vs Claude Code com Opus 4.6 — Por que agora uso os dois
Depois de usar Claude Code com Opus 4.6 todos os dias por quase um ano, passei uma semana com Codex e GPT-5.4. O veredito: nenhuma ferramenta vence sozinha. A combinação — revisão cruzada entre modelos, forças complementares e resiliência operacional — é melhor do que cada uma isoladamente.
Depois de usar Claude Code todos os dias por quase um ano, passei uma semana com Codex e GPT-5.4. Nenhuma ferramenta vence sozinha — mas usar as duas juntas, com revisão cruzada entre modelos, produz resultados melhores do que usar qualquer uma delas isoladamente. Foi isso que encontrei, do ponto de vista de alguém que já colocou produtos reais no ar com as duas.
Usei Claude Code com Opus 4.6 como minha principal ferramenta de desenvolvimento para tudo: reconstruir este site, colocar DIALØGUE na App Store, construir STRAŦUM, traduzir 3,9 milhões de palavras em 12 idiomas e produzir uma pipeline inteira de vídeo de curso com 18 tipos de layout e sincronização de áudio por palavra.
Então, quando a OpenAI lançou GPT-5.4 com Codex em 5 de março, eu não estava procurando substituição. Estava só curioso. A OpenAI também estava oferecendo um mês grátis, o que deixou a experimentação fácil e sem muito compromisso.
Fiquei positivamente surpreso. Mais do que positivamente surpreso, na verdade — Codex com GPT-5.4 era genuinamente capaz de maneiras que eu não esperava.
Uma semana depois, eu não estou trocando de ferramenta. Estou usando as duas. E acho que a combinação é melhor do que qualquer uma delas isoladamente.
Por que a distinção entre harness e modelo importa?
Antes de entrar nos detalhes, tem uma nuance que acho que a maioria das comparações ignora.
Claude Code e Codex são harnesses — as ferramentas de CLI, a orquestração de agentes, os ecossistemas de plugins, a gestão de contexto, a forma como interagem com o sistema de arquivos e com o terminal. Opus 4.6 e GPT-5.4 são os modelos por trás — a inteligência que toma as decisões de fato sobre o que fazer, como raciocinar sobre um problema e que código escrever.
Isso importa porque algumas das minhas observações são sobre o harness e outras são sobre o modelo. O despacho automático de QA e a gestão de agentes em paralelo do Claude Code? Isso é o harness. O insight arquitetural do GPT-5.4 sobre meu problema de sincronização de fragmentos? Isso é o modelo. Quando falo que a revisão cruzada entre modelos produz planos melhores, estou falando especificamente de como os modelos raciocinam de maneiras diferentes — o harness só entrega a saída.
Um modelo melhor dentro de um harness pior ainda pode ser frustrante. Um harness excelente com um modelo mais fraco pode parecer polido, mas raso. Neste momento, as duas combinações são fortes — mas fortes de formas diferentes.
Como foi o primeiro uso do Codex com GPT-5.4?
Vou ser honesto — eu esperava que o Codex parecesse um passo atrás. Estou bem mergulhado no ecossistema do Claude Code: o plugin Superpowers para planejamento estruturado, o despacho de agentes em paralelo, os agentes de code review que rodam automaticamente depois da implementação. É um workflow maduro.
Codex com GPT-5.4 pareceu competitivo imediatamente. O modelo é forte. O raciocínio é sólido. Ele segue bem planos. Quando dei a ele um plano de implementação bem estruturado, conseguiu trabalhar por mais de 45 minutos seguidos sem perder o fio — fazendo commit, rodando testes, dando push e passando para a próxima tarefa.
Ativei algumas funcionalidades experimentais do Codex bem cedo:
- Multi-agents — execução paralela de tarefas, parecida com o despacho de agentes do Claude Code
- JavaScript REPL — runtime persistente baseado em Node para debugging inline
- Prevent sleep while running — mantém a máquina acordada durante sessões longas
Isso fez diferença. O suporte a multi-agents, em especial, me deu a sensação de que o Codex estava alcançando um tipo de workflow do qual eu já dependia no Claude Code.
Onde o GPT-5.4 superou o Opus 4.6?
Preciso admitir — houve uma área em que o GPT-5.4 venceu claramente o Opus 4.6, e não foi algo pequeno.
Tenho trabalhado numa pipeline de vídeo para cursos que sincroniza fragmentos de slides com áudio narrado. O problema difícil não é timing — a ElevenLabs já nos entrega timestamps em nível de palavra. O problema difícil é alinhamento: decidir qual fragmento na tela deve aparecer quando o narrador começa a falar sobre ele.
As notas do narrador frequentemente não repetem o texto do slide palavra por palavra. Às vezes a narração parafraseia um bullet, às vezes combina dois bullets numa única ideia, às vezes existe um bullet no slide que na prática nunca é falado. Então o sistema fica adivinhando com base em palavras-chave. Isso funciona o bastante para parecer promissor, mas quebra nos slides mais difíceis.
O Opus 4.6 em medium thinking sofreu com isso ao longo de várias sessões. Continuava propondo heurísticas cada vez mais inteligentes — divisão igual por tamanho de texto, busca de palavras-chave nos timestamps, matching por sentença, matching em dupla estratégia — cada uma um pouco melhor, mas todas ainda limitadas na raiz.
O GPT-5.4 em high thinking identificou o problema arquitetural: isso não deveria ser tratado como problema de matching por keyword. Deveria ser tratado como problema de modelo de dados. O renderer deveria emitir os estados reais dos fragmentos, o assembler deveria alinhar a narração a esses estados, e a validação deveria sinalizar slides em que a estrutura visual e a narração não batem.
Era exatamente o insight certo. A mudança de “adivinhar a sincronia pelo texto” para “tornar a sincronia uma parte explícita e de primeira classe da pipeline” era o reframe arquitetural de que o problema precisava. E o GPT-5.4 chegou lá mais rápido do que o Opus.
Onde o Claude Code ainda ganha?
Mas aqui está o ponto — qualidade de execução e follow-through não são a mesma coisa que insight arquitetural.
Qualidade de execução
O exemplo mais claro: pedi às duas ferramentas que auditassem e melhorassem as companion notes em sete módulos de curso. O Codex voltou dizendo que o trabalho estava feito.
O Claude Code voltou com isto:
Audit Complete — All 7 Modules
Tier 1: Fix the 15 existing thin companion notes (bring them up to standard — quick win)
Tier 2: Add companion notes to ~25-30 high-priority slides (core frameworks, tool lists, multi-step processes, dense stats)
Isso não é “feito”. Isso é uma análise estruturada de lacunas identificando 40 a 45 slides que precisam de atenção, priorizadas em tiers. A diferença entre “completei a tarefa” e “completei a tarefa e aqui está o que encontrei” é grande quando você está colocando um produto real no ar.
QA automático
Essa é a killer feature do Claude Code, e acho que as pessoas ainda falam pouco sobre ela. Depois de concluir um bloco de implementação, o Claude Code despacha automaticamente agentes de QA — code review, revisão narrativa, checagens de consistência — sem eu pedir. Isso vem embutido no próprio Claude Code.
O Codex ainda não faz isso. Quando o Codex diz que terminou, você precisa verificar manualmente ou montar o próprio processo de revisão. No Claude Code, a verificação já faz parte do workflow. Brilhante.
Gestão de agentes em paralelo
A orquestração de agentes do Claude Code é mais madura. Ele despacha vários agentes especializados, gerencia os resultados, sintetiza os achados e apresenta um resumo coerente. Já tive sessões com 5 ou 6 agentes rodando ao mesmo tempo — um explorador, um code reviewer, um agente de implementação, um executor de testes — todos coordenados.
O suporte a multi-agents do Codex é promissor, mas ainda está num estágio mais inicial. Funciona, mas a coordenação ainda não é tão fluida.
Consistência
Em sessões longas, com muitas partes se movendo ao mesmo tempo — por exemplo, produzir slides em 7 módulos com 18 tipos de layout — o Claude Code mantém a consistência melhor. Os design tokens continuam corretos, as convenções de nomenclatura se mantêm, e as decisões arquiteturais tomadas na primeira hora ainda são respeitadas na quarta.
Dá para cruzar workflows entre as ferramentas?
Houve um workflow que eu não esperava: usar Codex para inspecionar o ecossistema de plugins do Claude Code e adaptá-lo.
Gosto especialmente de alguns plugins do Claude Code: o workflow de feature development (/feature-dev), o sistema de code review (/code-review), o simplificador de código (/code-simplifier), o framework de planejamento do Superpowers (/superpowers) e a skill de frontend design (/frontend-design). São workflows bem desenhados que incorporam boas práticas diretamente à ferramenta.
Então pedi ao Codex para estudá-los e criar skills equivalentes no Codex:
"Estou escrevendo skills de Codex em
~/.codex/skills, usando os workflows de plugins do Claude como template e adaptando ao modelo de skills do Codex onde recursos exclusivos do Claude, como hooks ou comandos de plugin, não existem."
Funcionou. Não perfeitamente — alguns conceitos do Claude Code não têm equivalente direto no Codex — mas os workflows principais se traduziram bem. Agora tenho processos de desenvolvimento estruturados nas duas ferramentas, informados pela mesma filosofia.
O que acontece quando você faz um modelo revisar o outro?
Esse, para mim, foi o achado mais valioso da semana.
Fazer o Opus 4.6 revisar criticamente um plano do GPT-5.4, e depois fazer o GPT-5.4 revisar a versão revisada pelo Opus — repetindo esse vai-e-vem algumas vezes — produz resultados significativamente melhores do que deixar qualquer um dos dois trabalhar sozinho.
Eles encontram fraquezas diferentes. O Opus tende a capturar inconsistências arquiteturais e edge cases de tratamento de erro. O GPT-5.4 tende a detectar over-engineering e sugerir abordagens mais simples. Eles se complementam nos pontos cegos.
Passei a fazer isso com qualquer plano de implementação que não seja trivial: rascunho em uma ferramenta, revisão na outra, revisão, nova revisão. Duas ou três rodadas. O plano final fica mais enxuto, mais robusto e encontra problemas que nenhum dos modelos teria trazido à tona sozinho.
Se você está usando só uma ferramenta de AI coding, está deixando qualidade na mesa. Não porque qualquer uma delas seja ruim — as duas são genuinamente excelentes — mas porque raciocinam de forma diferente, e raciocínios diferentes encontram problemas diferentes.
O que acontece quando uma ferramenta sai do ar?
Em 11 de março, o Claude Code teve erros elevados — problemas de login, lentidão e falhas intermitentes. Por algumas horas, ficou essencialmente inutilizável.
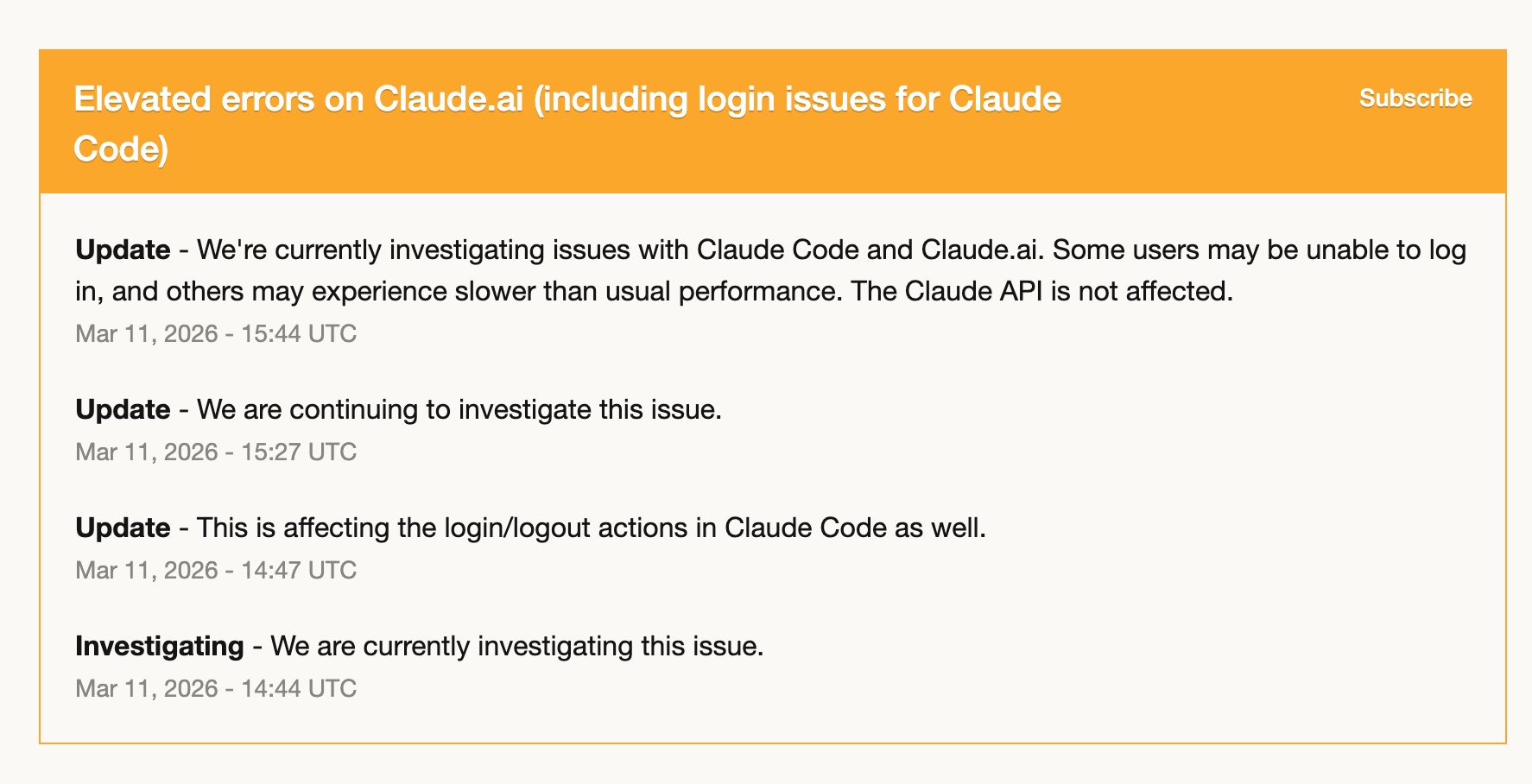
Como eu já vinha me aprofundando no Codex, migrei quase tudo para ele. E fiquei bem. Já tinha minhas skills do Codex prontas, meus workflows traduzidos, e o GPT-5.4 segurou o trabalho com competência.
Essa experiência cristalizou algo para mim: depender inteiramente de uma única ferramenta é um risco. Não porque a ferramenta seja pouco confiável — o Claude Code foi notavelmente estável durante o ano em que o usei — mas porque qualquer serviço pode ter um dia ruim. Ter uma segunda ferramenta com a qual você realmente se sente confortável não é luxo. É resiliência operacional.
Lado a lado: Claude Code vs Codex em um relance
| Dimensão | Claude Code (Opus 4.6) | Codex (GPT-5.4) |
|---|---|---|
| Qualidade de execução | Mais profunda — encontra lacunas e prioriza trabalho | Boa — executa tarefas, menos análise proativa |
| QA automático | Embutido, despacha agentes de revisão automaticamente | Ainda não — exige verificação manual |
| Agentes paralelos | Maduro — 5 a 6 agentes coordenados | Promissor — funciona, mas menos fluido |
| Raciocínio arquitetural | Forte em medium thinking | Excelente em high thinking — reframe mais rápido |
| Execução sustentada de planos | Boa | Impressionante — mais de 46 minutos contínuos |
| Compactação de contexto | Mais lenta | Mais rápida — diferente, não necessariamente melhor |
| Localização em escala | Empatado (Opus 4.6 medium) | Empatado — por enquanto mais barato |
| Ecossistema de plugins/skills | Maduro (Superpowers, /feature-dev, etc.) | Em crescimento — consegue adaptar workflows do Claude |
| Revisão cruzada entre modelos | Pega edge cases e inconsistências | Pega over-engineering e simplifica |
| Custo | US$100-200/mês | Promo de um mês grátis, depois TBD |
Mais algumas observações
Gestão de contexto: o Codex parece compactar contexto mais rápido quando a janela enche. Ainda não decidi se isso é melhor ou pior — só é visivelmente diferente de como o Claude Code lida com isso.
Localização em escala: traduzi 3,9 milhões de palavras em 12 idiomas usando Claude Code com Opus 4.6. A qualidade de tradução do GPT-5.4 está no mesmo nível do Opus 4.6 em medium thinking — e, por enquanto, sai mais barato para eu rodar em escala. Então venho migrando boa parte do meu trabalho pesado de localização para o GPT-5.4. Não sei por quanto tempo essa vantagem de custo vai durar, mas enquanto durar, faz sentido usar.
Custo: estou no plano Max de US$200/mês do Claude Code. Como o Codex agora está assumindo uma parcela relevante da minha carga — especialmente localização — estou considerando cair para o plano de US$100. O mês grátis da OpenAI ajuda nessa transição, mas, mesmo em preço cheio, dividir a carga entre duas ferramentas em tiers mais baixos pode sair melhor do que esgotar uma só.
Onde cheguei
Depois de uma semana real de dual-wielding, este é meu modelo de trabalho hoje:
Recorra ao Claude Code quando: você precisar de qualidade de execução com QA embutido, orquestração complexa de múltiplos agentes, consistência em sessões longas dentro de codebases grandes, ou estiver trabalhando num projeto em que o workflow do Superpowers já está montado.
Recorra ao Codex quando: você precisar de uma perspectiva arquitetural nova, quiser usar high thinking num problema difícil de raciocínio, estiver executando um plano bem definido que se beneficie de trabalho sustentado sem interrupção, ou o Claude Code estiver num dia ruim.
Use os dois para: qualquer plano de implementação que não seja trivial. Faça o rascunho em um, revise no outro. O loop de revisão cruzada entre modelos é, sinceramente, o melhor workflow que encontrei até agora.
Não estou abandonando o Claude Code — ele continua sendo minha ferramenta principal e o ecossistema que conheço melhor. Mas não sou mais um desenvolvedor de ferramenta única. O GPT-5.4 conquistou lugar no meu workflow por capacidade real, não só como backup.
O futuro do desenvolvimento assistido por IA não é escolher um vencedor. É saber quando puxar qual ferramenta e — mais importante ainda — entender que as ferramentas funcionam melhor juntas do que separadas.
Perguntas frequentes
GPT-5.4 é melhor que Opus 4.6 para programar?
Nenhum dos dois é estritamente melhor. O GPT-5.4 em high thinking se destaca em raciocínio arquitetural e execução sustentada de planos. O Opus 4.6 se destaca em qualidade de execução, análise proativa de lacunas e consistência ao longo de sessões longas. Os melhores resultados aparecem quando você usa os dois modelos para revisar o trabalho um do outro.
Vale a pena trocar o Claude Code pelo Codex?
Eu não recomendaria uma troca total. As duas ferramentas têm forças distintas — o QA automático e a orquestração de agentes em paralelo do Claude Code estão genuinamente à frente, enquanto a execução sustentada do Codex e o raciocínio do GPT-5.4 em problemas difíceis são impressionantes. A abordagem de usar os dois te dá o melhor dos dois mundos.
O workflow de revisão cruzada entre modelos vale o esforço extra?
Para planos não triviais, absolutamente. Fazer o Opus revisar a saída do GPT-5.4 e vice-versa captura categorias diferentes de problemas — o Opus pega edge cases e inconsistências, o GPT-5.4 pega over-engineering. Duas ou três rodadas produzem planos visivelmente mais sólidos do que deixar um modelo trabalhar sozinho.
Quanto custa uma configuração com duas ferramentas?
O Claude Code custa entre US$100 e US$200 por mês, dependendo do plano. O preço do Codex varia — a OpenAI está oferecendo um mês grátis no momento. Mesmo em preço cheio, dividir a carga entre duas ferramentas em tiers mais baixos pode sair mais barato do que forçar uma só até o limite.
Dá para usar plugins do Claude Code no Codex?
Não diretamente, mas dá para adaptar. Usei o Codex para inspecionar workflows de plugins do Claude Code (/feature-dev, /code-review, /superpowers) e traduzir a lógica principal em skills do Codex dentro de ~/.codex/skills. Alguns recursos específicos do Claude, como hooks, não se traduzem, mas os workflows sim.
É isso da minha parte. Fiquei curioso — mais alguém está trabalhando com workflows multi-modelo? Usando Claude Code e Codex juntos, ou outras combinações? Que padrões vocês estão vendo surgir?
Abraços, Chandler





