MicrosoftのChatGPT統合でより良い検索体験の準備はできていますか?
MicrosoftのChatGPT-Bing統合はデータの問題を解決しますが、本当の課題は、一つの回答を出すべき時と複数の回答を出すべき時を見極められるインターフェースの設計です。
この記事は2023年に書かれたものです。一部の情報が変更されている可能性があります。
今週、いくつかのニュースメディアが、MicrosoftがChatGPTの機能をBing Searchに組み込む作業を進めていると報じました。以前「ChatGPTはGoogleに取って代わるか?」について書いたことがあるので、ここで追加の考えを述べたいと思います。
ウェブコンテンツのインデックス化はもはや障壁ではない
Microsoftは2019年にOpenAIに$10億を投資したと報じられています。つまり、両社のパートナーシップは少なくとも3年間続いていることになります。Bing Searchは明らかにウェブをインデックス化できるので、OpenAIがChatGPTのデータセットを2021年以降に拡張したい場合、ウェブコンテンツのインデックス化は問題ではないと考えるべきです。Microsoftの規模を考えると、リアルタイムのインデックス化/クロール能力もGoogleと比較してかなり良いと想定できます。
Bingにはすでに画像、動画コンテンツなどがデータセットの一部として含まれているため、これもOpenAIのChatGPTにとって障壁にはなりません。
Bing Searchはコンテンツの信頼性を比較的うまくランク付けできる
Google SearchとBing Searchの結果の最新比較は確認していませんが、コンテンツの信頼性を判断する両社の能力の差はそれほど大きくないと言って問題ないでしょう。したがって、Microsoftの助けがあれば、最も正確な答えを見つけることもOpenAI/ChatGPTにとって大きな障壁にはならないかもしれません。
具体的な例として、ChatGPTには最新のサービス評価データがないため、「近くの最高の配管工」や「近くの最高の中華レストラン」のようなローカルサービスに関する質問に答えることができません。ここでMicrosoftのデータセットが助けになります。
ユーザーインターフェースの問題
ChatGPTの体験がいかにユーザーフレンドリーであるかという議論は妥当ですが、すべての質問/クエリに対して万能の体験ではありません。多くの場合、ユーザーは複数の回答を求めています。たとえば、上記のローカルサービスの場合、ユーザーは適切な選択肢のリストを見たいことが多いです。その場合、ChatGPTのプロンプトを「近くの最高のxyzサービス」ではなく「近くの最高のxyzサービスを5つ教えて」と変更する必要があると主張することもできます。
しかし、それだけでは十分ではないと私は主張します。検索エンジンは、多くの場合、単一の最良の回答や短い最良の回答リストが存在しないことを理解できるほど賢くあるべきです。最良の回答は状況/コンテキストに依存します。
さらに、事実と意見があります。それらはまったく異なるものです。
したがって、複数のシナリオに最適なユーザーインターフェースをどう設計するかが鍵です。たとえば、「recipe for Vietnamese baguette」(ベトナムのバゲットのレシピ) :D のようなシンプルなものでも、2023年1月時点でGoogle、Bing、ChatGPTからそれぞれ以下のような結果が得られます。どれが良いか、またはChatGPTの回答が良いかは明らかではありません。
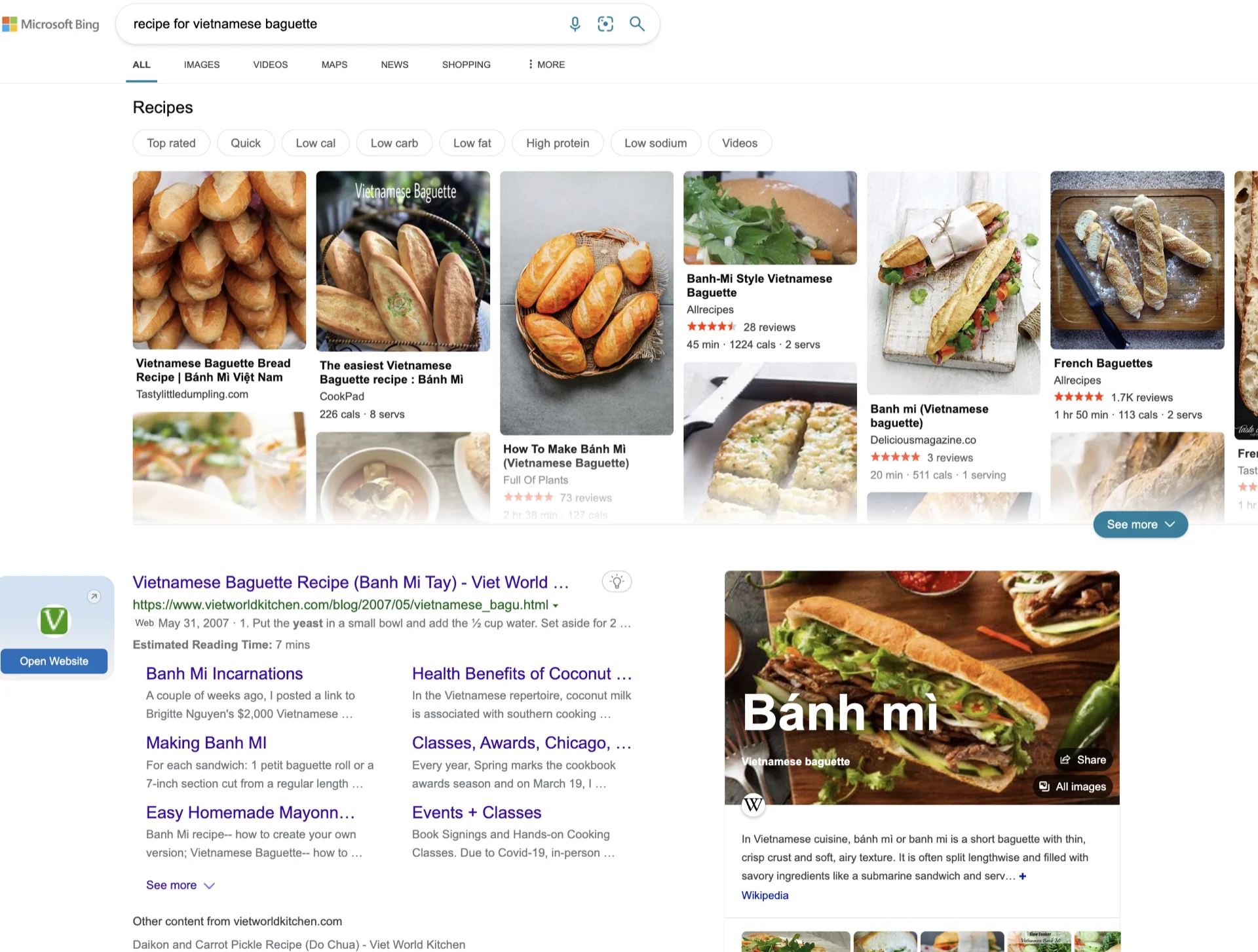
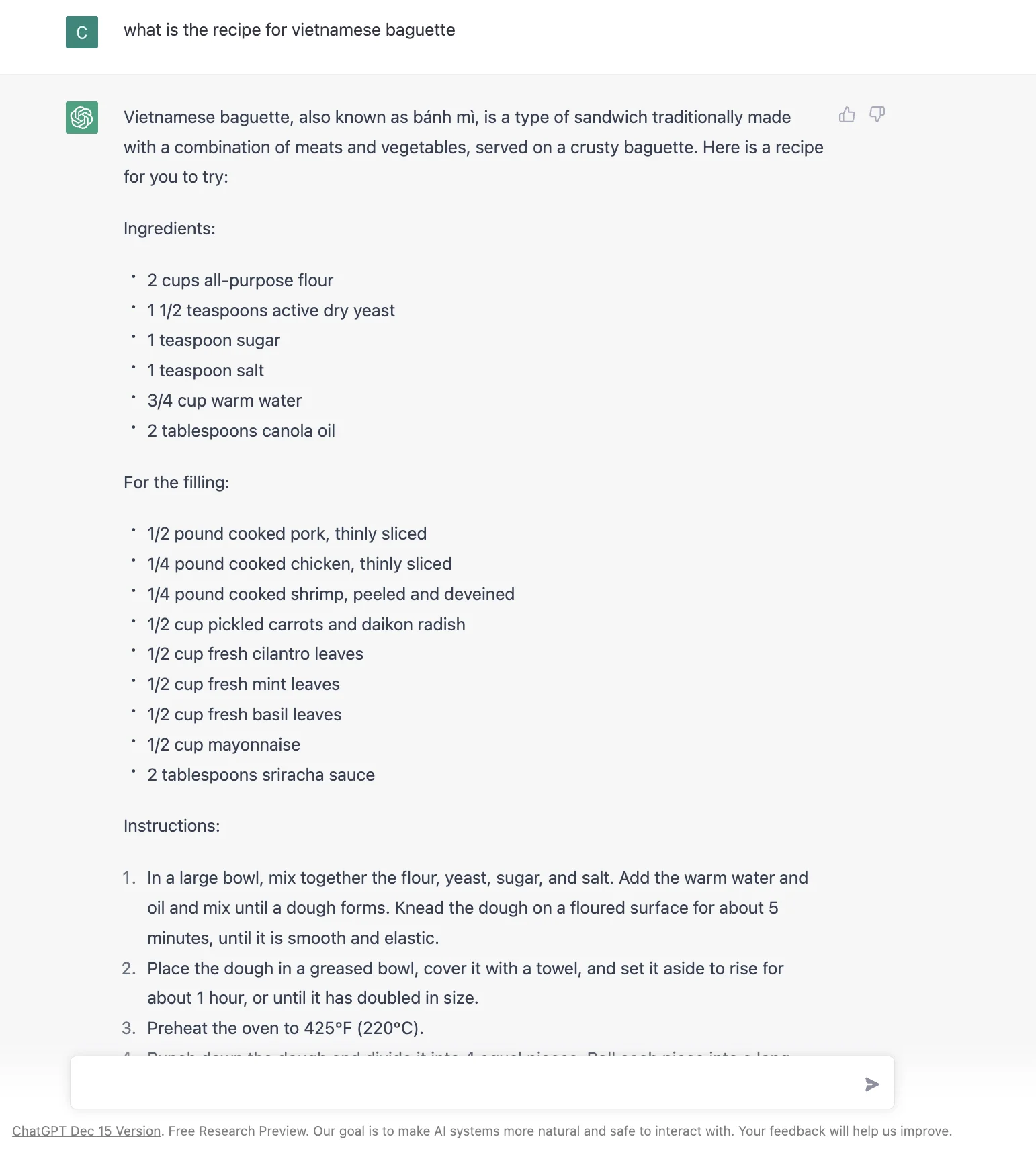
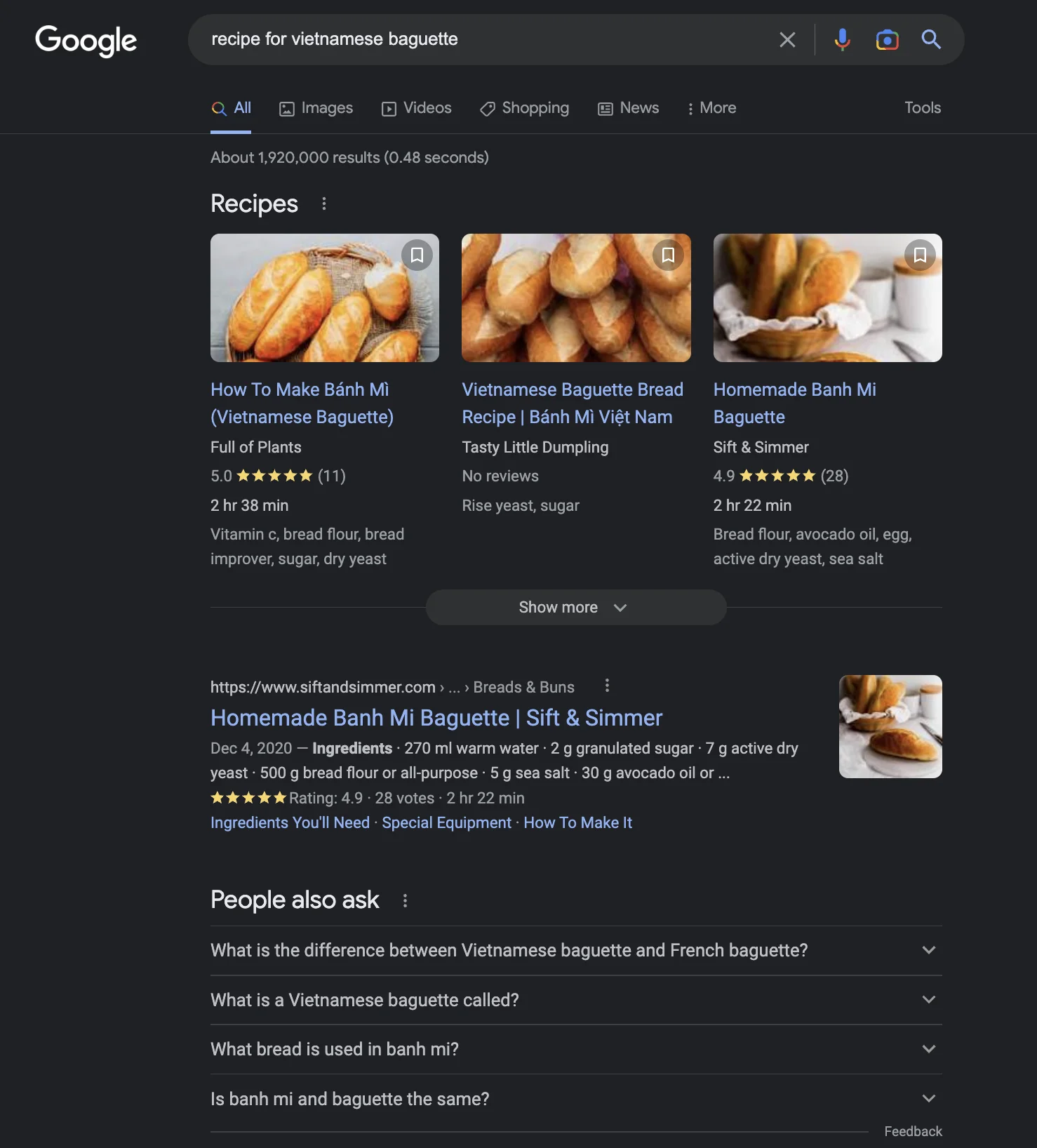
そこで鍵となるのは、機械学習を使ってユーザーの意図に基づいて検索結果のインターフェースを動的に変更することです。これがどれほど簡単か難しいかはわかりませんが、ChatGPTの単一回答スタイルと検索エンジンの強みを組み合わせるのは論理的なステップのようです。
言語アシスタント
純粋な情報検索の観点から回答を提供することが人々がChatGPTを好む理由ではないと主張します。それは、ChatGPTにコンテキストを与えて、詩、紹介文、エッセイなどの言語関連タスクを完了させる能力です。
このユースケースは検索エンジンとはまったく異なり、PowerPointのナレーションを生成したりMicrosoft Wordで文章を書いたりする能力により近いものです。実際、MicrosoftがOffice 365スイートにさまざまなOpenAIの機能を組み込むというニュースの方が良いニュースだと思います。
言語の限界
Jacob BrowningとYann Lecunは、ChatGPTが一般公開される前の2022年8月に、AIと言語の限界について優れた記事を書いています。彼らの記事はLaMDAを参照していますが、その内容はChatGPTや他のあらゆる大規模言語モデルにも基本的に適用できます。記事が長いので、主要なポイントをまとめると:
あるGoogleのエンジニアが最近、GoogleのAIチャットボットLaMDAを「人格」と宣言し、さまざまな反応を引き起こしました。LaMDAは、与えられたテキストの行に対して次に来る可能性の高い単語を予測するように設計された大規模言語モデル(LLM)です。
一部の人はこの考えを嘲笑し、次のAIが人格を持つかもしれないと示唆する人もいました。反応の多様性は、より深い問題を浮き彫りにしています。これらのLLMがより一般的で強力になるにつれて、それらをどう理解するかについての合意が少なくなっています。根本的な問題は言語の限定的な性質にあります。これらのシステムは、人間に見られる本格的な思考に近づくことのない浅い理解にとどまることが明らかです。なぜなら、言語は特定の限定的な種類の知識表現にすぎないからです。言語は離散的なオブジェクトとプロパティ、およびそれらの関係を表現するのには優れていますが、不規則な形状やオブジェクトの動きの記述など、より具体的な情報を表現するのには苦労します。アイコニックな知識や分散型知識のような他の表現スキームがあり、これらの情報をアクセスしやすい方法で表現できます。
言語は情報を伝達するための低帯域幅の方法であり、同音異義語や代名詞のためにしばしば曖昧です。人間は非言語的な理解を共有しているため、完璧なコミュニケーション手段を必要としません。大規模言語モデル(LLM)は、各文の背景知識を拾い上げ、周囲の単語や文を参照して何が起こっているかを理解するように訓練されています。LLMは言語の浅い理解を獲得しましたが、この理解は限定的であり、より複雑な会話のためのノウハウは含まれていません。その結果、矛盾した発言や言語の切り替えによって簡単に混乱させることができます。LLMには、世界の一貫したビューを構築するために必要な理解が欠けています。
言語は少量の形式で多くの情報を伝えることができますが、人間の知識の多くは非言語的であり、図表、地図、工芸品、社会的慣習など他の手段で伝えることができます。これは、言語だけで訓練された機械は、狭いボトルネックを通じて人間の知識のほんの一部にしかアクセスできないため、人間の知能を完全に近似することはできないということを示唆しています。また、言語が有用であるためには、世界に対する深い非言語的理解が必要であることも示唆しています。言語のみで訓練された場合、機械がどれほど賢くなれるかには限界があるということです。
以上が私の考えです。いかがでしょうか?GoogleからChatGPT搭載のBingに乗り換えることを考えていますか、それとも習慣でGoogleを使い続けますか? :)
よろしくお願いします、Chandler