Codex với GPT-5.4 vs Claude Code với Opus 4.6 — Vì Sao Giờ Tôi Dùng Cả Hai
Sau gần một năm dùng Claude Code với Opus 4.6 mỗi ngày, tôi dành một tuần với Codex và GPT-5.4. Kết luận là không tool nào thắng tuyệt đối. Sự kết hợp giữa cross-model review, các thế mạnh bổ trợ cho nhau, và khả năng chống chịu về vận hành cho ra kết quả tốt hơn dùng riêng lẻ.
Sau gần một năm dùng Claude Code mỗi ngày, tôi dành một tuần với Codex và GPT-5.4. Không có công cụ nào thắng tuyệt đối — nhưng dùng cả hai cùng lúc, với cross-model review, cho ra kết quả tốt hơn hẳn từng công cụ riêng lẻ. Đây là những gì tôi rút ra, từ góc nhìn của một người đã ship sản phẩm thật với cả hai.
Tôi đã dùng Claude Code với Opus 4.6 làm công cụ phát triển chính cho gần như mọi thứ: xây lại site này, đưa DIALØGUE lên App Store, build STRAŦUM, dịch 3,9 triệu từ sang 12 ngôn ngữ, và dựng cả một pipeline video khóa học với 18 loại layout cùng đồng bộ audio ở cấp độ từng từ.
Nên khi OpenAI ra mắt GPT-5.4 với Codex vào ngày 5 tháng 3, tôi không đi tìm sự thay thế. Tôi chỉ tò mò thôi. OpenAI cũng đang chạy chương trình miễn phí một tháng, nên việc nhảy vào thử khá dễ, không cần cam kết gì nhiều.
Tôi đã bất ngờ theo hướng tích cực. Thậm chí không chỉ là hơi bất ngờ — Codex với GPT-5.4 thực sự có năng lực theo những cách mà tôi không đoán trước.
Một tuần sau, tôi không đổi hẳn. Tôi dùng song song. Và tôi nghĩ chính sự kết hợp đó mới tốt hơn từng tool đứng riêng.
Vì Sao Việc Phân Biệt Harness với Model Lại Quan Trọng?
Trước khi đi vào chi tiết, có một nuance mà tôi nghĩ hầu hết các bài so sánh đều bỏ qua.
Claude Code và Codex là harness — tức CLI tool, cách điều phối agent, hệ plugin, quản lý context, và cách chúng tương tác với filesystem cùng terminal của bạn. Opus 4.6 và GPT-5.4 là model nằm bên dưới — phần trí tuệ thực sự đưa ra quyết định về việc nên làm gì, suy luận vấn đề ra sao, và viết loại code nào.
Điều này quan trọng vì một số quan sát của tôi là về harness, còn một số là về model. Khả năng tự động dispatch QA và quản lý agent song song của Claude Code? Đó là harness. Insight kiến trúc của GPT-5.4 về bài toán fragment sync của tôi? Đó là model. Khi tôi nói cross-model review cho ra plan tốt hơn, tôi đang nói về việc các model suy nghĩ khác nhau — harness chỉ là thứ chuyển tải đầu ra đó.
Một model tốt hơn trong một harness tệ hơn vẫn có thể gây bực bội. Một harness tuyệt vời với model yếu hơn có thể trông rất bóng bẩy nhưng lại nông. Ngay lúc này, cả hai cặp kết hợp đều mạnh — nhưng mạnh theo những cách khác nhau.
Codex với GPT-5.4 Gây Ấn Tượng Thế Nào Ngay Từ Lần Dùng Đầu?
Phải thừa nhận là ban đầu tôi nghĩ Codex sẽ bị hụt hơi. Tôi đã đi khá sâu vào hệ sinh thái Claude Code: plugin Superpowers cho lập kế hoạch có cấu trúc, dispatch agent song song, các code review agent tự chạy sau khi implement. Đó là một workflow đã khá chín.
Codex với GPT-5.4 lại cạnh tranh ngay lập tức. Model mạnh. Suy luận chắc. Nó follow plan rất tốt. Khi tôi đưa cho nó một implementation plan được cấu trúc cẩn thận, nó có thể làm việc liên tục hơn 45 phút mà không mất mạch — commit, test, push, rồi chuyển sang task tiếp theo.
Tôi cũng bật vài tính năng experimental của Codex khá sớm:
- Multi-agents — chạy các task song song, tương tự như cách Claude Code dispatch agent
- JavaScript REPL — runtime Node persistent để debug inline
- Prevent sleep while running — giữ máy không ngủ trong các phiên làm việc dài
Những thứ này tạo ra khác biệt thấy rõ. Đặc biệt là hỗ trợ multi-agent khiến tôi có cảm giác Codex đang bắt kịp kiểu workflow mà tôi đã quen phụ thuộc bên Claude Code.
GPT-5.4 Vượt Opus 4.6 Ở Điểm Nào?
Phải nói thẳng là có một chỗ GPT-5.4 thắng Opus 4.6 rất rõ, và đây không phải chuyện nhỏ.
Tôi đang build một pipeline video khóa học có nhiệm vụ đồng bộ các fragment trên slide với audio thuyết minh. Phần khó không phải là timing — ElevenLabs đã cho tôi word-level timestamp. Phần khó là alignment: xác định fragment nào trên màn hình nên hiện ra khi người nói bắt đầu nói về nó.
Speaker notes thường không lặp lại nguyên văn text trên slide. Có lúc phần narration diễn đạt lại một bullet. Có lúc nó gộp hai bullet thành một ý. Cũng có lúc bullet nằm trên slide nhưng thực ra chẳng được nhắc đến rõ ràng. Vì thế hệ thống cứ phải đoán từ keyword. Cách đó hoạt động đủ thường xuyên để nhìn có vẻ ổn, nhưng sẽ gãy ở những slide khó hơn.
Opus 4.6 ở mức medium thinking đã vật lộn với chuyện này qua nhiều phiên làm việc. Nó liên tục đưa ra các heuristic ngày càng thông minh hơn — chia đều theo độ dài text, tìm keyword trong timestamp, matching ở cấp câu, matching theo hai chiến lược — từng cái đều khá hơn, nhưng về bản chất vẫn bị giới hạn.
GPT-5.4 ở mức high thinking nhận ra đúng vấn đề kiến trúc: bài toán này không nên bị xử lý như keyword matching. Nó nên được xử lý như một bài toán data model. Renderer nên emit ra các fragment state thực sự, assembler nên align narration với các state đó, còn validation nên flag những slide mà cấu trúc hình ảnh và lời thuyết minh không khớp nhau.
Đó là insight đúng. Sự dịch chuyển từ kiểu "đoán sync từ text" sang "biến sync thành một phần first-class, explicit của pipeline" chính là cú reframe kiến trúc mà bài toán này cần. Và GPT-5.4 đi tới đó nhanh hơn Opus.
Claude Code Vẫn Thắng Ở Đâu?
Nhưng đây mới là vấn đề — insight kiến trúc và chất lượng thực thi đến cùng không phải là một chuyện.
Chất Lượng Thực Thi
Ví dụ rõ nhất: tôi yêu cầu cả hai tool audit và cải thiện companion notes trên bảy module khóa học. Codex quay lại và nói công việc đã xong.
Claude Code thì quay lại với thứ này:
Audit Hoàn Tất — Cả 7 Module
Tier 1: Sửa 15 companion notes mỏng hiện có (đưa lên chuẩn — quick win)
Tier 2: Thêm companion notes cho khoảng 25-30 slide ưu tiên cao (framework cốt lõi, danh sách tool, quy trình nhiều bước, thống kê dày đặc)
Đó không phải là "xong". Đó là một phân tích gap có cấu trúc, chỉ rõ 40-45 slide cần chú ý, lại còn sắp ưu tiên theo tier. Sự khác biệt giữa "Tôi hoàn thành task" và "Tôi hoàn thành task và đây là những gì tôi phát hiện ra" rất đáng kể khi bạn đang ship một sản phẩm thật.
QA Tự Động
Đây là killer feature của Claude Code, và tôi nghĩ mọi người vẫn chưa nói đủ nhiều về nó. Sau khi hoàn thành một phần implementation, Claude Code tự động dispatch các QA agent — code review, narrative review, consistency check — mà tôi không cần phải nhắc.
Codex hiện chưa làm được vậy. Khi Codex nói nó xong, bạn vẫn phải tự verify hoặc tự dựng quy trình review riêng. Với Claude Code, việc verify đã là một phần của workflow. Rất hay.
Quản Lý Agent Song Song
Khả năng orchestration agent của Claude Code chín hơn. Nó dispatch nhiều agent chuyên biệt, quản lý kết quả, tổng hợp các finding, rồi trình bày lại thành một summary mạch lạc. Tôi đã có những phiên với 5-6 agent chạy cùng lúc — explorer, code reviewer, implementation agent, test runner — và tất cả đều được phối hợp tốt.
Multi-agent support của Codex thì có nhiều hứa hẹn nhưng vẫn còn sớm hơn trong vòng đời phát triển. Nó hoạt động, nhưng sự phối hợp chưa mượt bằng.
Tính Nhất Quán
Trong các phiên dài với nhiều moving parts — ví dụ như sản xuất slide cho 7 module với 18 loại layout — Claude Code giữ sự nhất quán tốt hơn. Design token không bị lệch. Naming convention vẫn được giữ. Những quyết định kiến trúc đã thống nhất từ giờ đầu tiên vẫn còn được tôn trọng ở giờ thứ tư.
Có Thể Cross-Pollinate Workflow Giữa Hai Tool Không?
Một workflow mà tôi không ngờ tới là: dùng Codex để nghiên cứu hệ plugin của Claude Code rồi adapt lại.
Tôi đặc biệt thích một số plugin của Claude Code: workflow phát triển tính năng (/feature-dev), hệ thống code review (/code-review), trình đơn giản hóa code (/code-simplifier), framework lập kế hoạch Superpowers (/superpowers), và skill thiết kế frontend (/frontend-design). Đây là những workflow được thiết kế tốt, đóng gói best practice vào tool.
Vì thế tôi yêu cầu Codex nghiên cứu chúng rồi tạo ra các Codex skill tương đương:
"Tôi đang viết các Codex skill cấp user trong
~/.codex/skills, dùng workflow plugin của Claude Code làm template và adapt chúng cho mô hình skill của Codex ở những nơi mà tính năng chỉ có trong Claude Code như hooks hoặc plugin commands không tồn tại."
Nó hoạt động. Không hoàn hảo — có một số khái niệm của Claude Code không có equivalent trực tiếp trong Codex — nhưng workflow cốt lõi được chuyển hóa khá tốt. Giờ tôi có những quy trình phát triển có cấu trúc ở cả hai tool, dựa trên cùng một triết lý thiết kế.
Điều Gì Xảy Ra Khi Bạn Cho Hai Model Review Lẫn Nhau?
Đây là điều giá trị nhất mà tôi rút ra được trong tuần này.
Khi cho Opus 4.6 review kỹ một plan từ GPT-5.4, rồi cho GPT-5.4 review lại phiên bản đã được Opus chỉnh, và chạy qua chạy lại vài vòng như thế — kết quả tốt hơn đáng kể so với việc chỉ để một model làm một mình.
Chúng tìm ra các loại điểm yếu khác nhau. Opus thường bắt được các điểm không nhất quán về kiến trúc và edge case trong error handling. GPT-5.4 lại hay bắt được dấu hiệu over-engineering và đề xuất hướng đi đơn giản hơn. Chúng bù được blind spot của nhau.
Tôi đã bắt đầu làm vậy với mọi implementation plan không tầm thường: draft ở một tool, review ở tool còn lại, chỉnh, rồi review tiếp. Hai hoặc ba vòng. Plan cuối cùng chặt hơn, chắc hơn, và thường bắt được những vấn đề mà từng model một mình đã bỏ sót.
Nếu bạn chỉ dùng một AI coding tool, tôi nghĩ bạn đang để rơi chất lượng trên bàn. Không phải vì tool nào dở — cả hai đều thực sự rất mạnh — mà vì chúng suy luận khác nhau, và các kiểu suy luận khác nhau sẽ bắt được các kiểu vấn đề khác nhau.
Chuyện Gì Xảy Ra Khi Một Tool Bị Sập?
Ngày 11 tháng 3, Claude Code gặp elevated errors — đăng nhập lỗi, hiệu năng chậm, thỉnh thoảng fail. Trong vài giờ, nó gần như không dùng được.
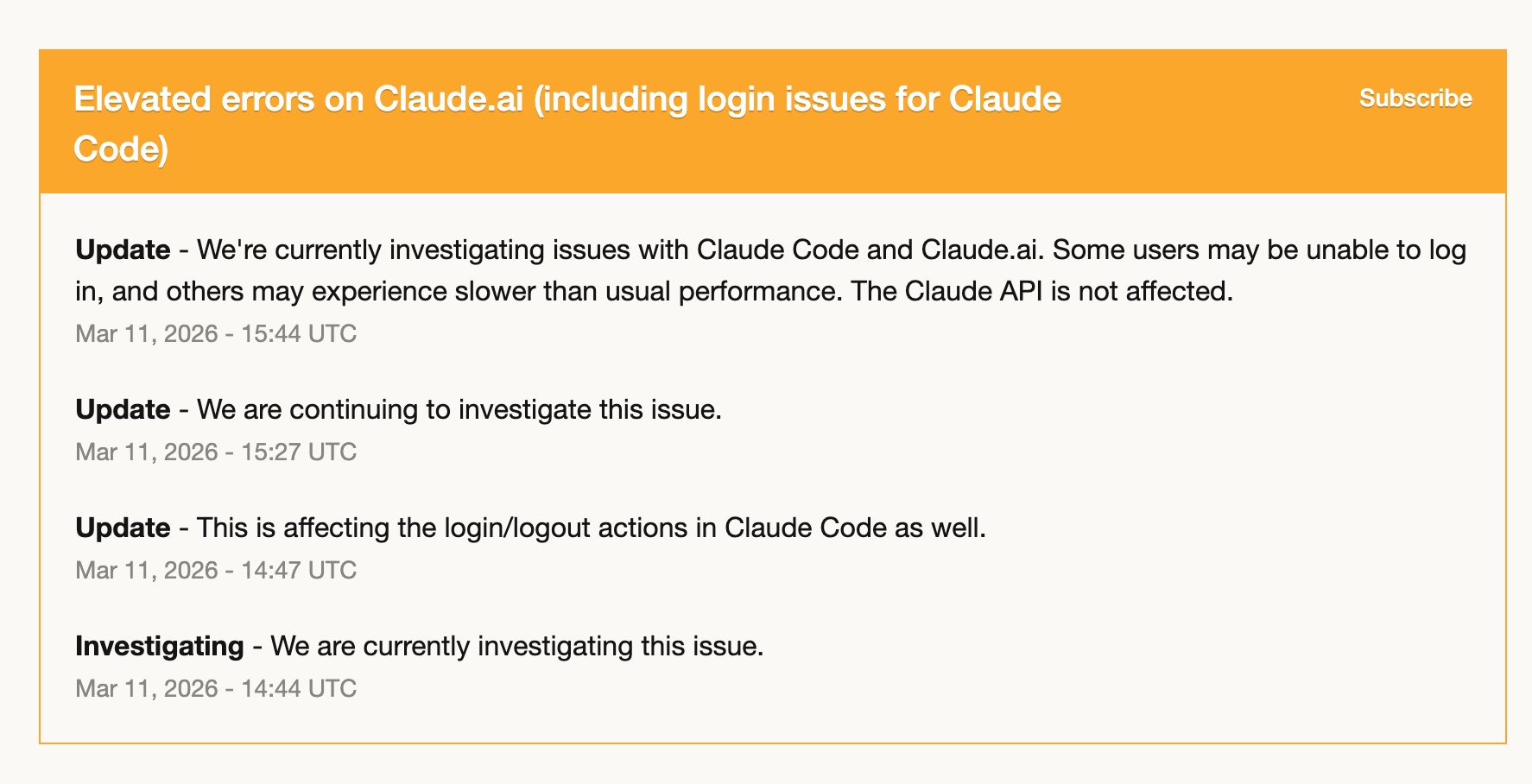
Vì tôi đã bắt đầu ramp up với Codex từ trước, tôi gần như chuyển hẳn sang đó. Và tôi vẫn ổn. Tôi đã có Codex skill sẵn, workflow đã được adapt, và GPT-5.4 xử lý công việc đủ tốt.
Trải nghiệm đó làm tôi nhìn ra một điều rất rõ: phụ thuộc hoàn toàn vào một tool là một rủi ro. Không phải vì tool đó không đáng tin — Claude Code đã ổn định đáng nể trong suốt năm tôi dùng nó — mà vì bất kỳ dịch vụ nào cũng có thể có một ngày tồi. Có sẵn một tool thứ hai mà bạn thực sự thấy thoải mái sử dụng không phải là xa xỉ. Nó là operational resilience.
Nhìn Nhanh: Claude Code vs. Codex
| Tiêu chí | Claude Code (Opus 4.6) | Codex (GPT-5.4) |
|---|---|---|
| Chất lượng thực thi | Sâu hơn — tìm gap, biết ưu tiên việc | Tốt — hoàn thành task, ít chủ động phân tích hơn |
| QA tự động | Có sẵn, tự dispatch review agent | Chưa có — cần verify thủ công |
| Agent song song | Chín hơn — 5-6 agent phối hợp | Đầy hứa hẹn — chạy được nhưng chưa mượt bằng |
| Suy luận kiến trúc | Mạnh ở medium thinking | Rất mạnh ở high thinking — reframe nhanh hơn |
| Thực thi plan dài hơi | Tốt | Ấn tượng — hơn 46 phút liên tục |
| Nén context | Chậm hơn | Nhanh hơn — khác biệt, chưa chắc đã tốt hơn |
| Localization ở quy mô lớn | Ngang ngửa (Opus 4.6 medium) | Ngang ngửa — hiện tại rẻ hơn |
| Hệ plugin/skill | Chín hơn (Superpowers, /feature-dev, v.v.) | Đang lớn dần — có thể adapt workflow của Claude |
| Cross-model review | Bắt edge case, vấn đề nhất quán | Bắt over-engineering, đề xuất đơn giản hóa |
| Chi phí | $100-200/tháng | Miễn phí một tháng, sau đó TBD |
Một Vài Quan Sát Khác
Quản lý context: Codex có vẻ nén context nhanh hơn khi context window đầy. Tôi vẫn chưa quyết định được đó là tốt hơn hay tệ hơn — chỉ là nó khác đi thấy rõ so với cách Claude Code xử lý.
Localization ở quy mô lớn: Tôi đã dịch 3,9 triệu từ sang 12 ngôn ngữ bằng Claude Code với Opus 4.6. Chất lượng dịch của GPT-5.4 ở mức khá ngang với Opus 4.6 medium thinking — và hiện tại thì rẻ hơn cho tôi khi chạy ở quy mô lớn. Vì vậy tôi đã bắt đầu chuyển dần phần localization số lượng lớn sang GPT-5.4. Tôi không chắc lợi thế chi phí đó kéo dài bao lâu, nhưng chừng nào còn thì cứ hợp lý mà dùng.
Chi phí: Tôi đang dùng gói Max $200/tháng của Claude Code. Bây giờ Codex đã xử lý một phần workload đáng kể — đặc biệt là localization — nên tôi đang cân nhắc hạ xuống tier $100. Tháng miễn phí của OpenAI giúp việc chuyển đổi này dễ hơn, nhưng ngay cả khi tính đủ giá, việc chia workload giữa hai tool ở các tier thấp hơn có thể vẫn hiệu quả chi phí hơn so với max-out một tool duy nhất.
Đây Là Kết Luận Của Tôi Lúc Này
Sau một tuần dùng song song thật sự, đây là working model của tôi:
Hãy dùng Claude Code khi: bạn cần chất lượng thực thi cao kèm QA tích hợp, điều phối multi-agent phức tạp, sự nhất quán dài hơi trên codebase lớn, hoặc đang làm việc trong project đã setup sẵn workflow Superpowers.
Hãy dùng Codex khi: bạn cần một góc nhìn kiến trúc mới, muốn high-thinking mode cho một bài toán suy luận khó, đang thực thi một plan rõ ràng cần sustained work không bị gián đoạn, hoặc đơn giản là hôm đó Claude Code đang có một ngày tồi.
Hãy dùng cả hai cho: bất kỳ implementation plan nào không tầm thường. Draft ở một tool, review ở tool kia. Vòng cross-model review thực sự là workflow tốt nhất mà tôi tìm ra cho tới lúc này.
Tôi không bỏ Claude Code — nó vẫn là tool chính và là hệ sinh thái mà tôi quen nhất. Nhưng tôi cũng không còn là một developer chỉ dùng một tool nữa. GPT-5.4 đã tự kiếm được chỗ đứng trong workflow của tôi bằng năng lực thật, chứ không chỉ vì nó đóng vai backup.
Tương lai của AI-assisted development không nằm ở chuyện chọn ra người thắng. Nó nằm ở việc biết khi nào nên với tới tool nào, và — quan trọng hơn — hiểu rằng các tool này tốt hơn khi đi cùng nhau thay vì tách rời.
Câu Hỏi Thường Gặp
GPT-5.4 có tốt hơn Opus 4.6 cho coding không?
Không có cái nào tốt hơn tuyệt đối. GPT-5.4 ở high thinking rất mạnh về suy luận kiến trúc và thực thi plan dài hơi. Opus 4.6 mạnh về chất lượng thực thi, phân tích gap chủ động, và giữ tính nhất quán qua các phiên dài. Kết quả tốt nhất đến từ việc dùng cả hai model review công việc của nhau.
Tôi có nên chuyển từ Claude Code sang Codex không?
Tôi sẽ không khuyên chuyển hoàn toàn. Cả hai tool đều có thế mạnh riêng — QA tự động và orchestration agent song song của Claude Code thực sự đang đi trước, trong khi khả năng sustained execution của Codex và suy luận của GPT-5.4 trên các bài toán khó lại rất ấn tượng. Cách tiếp cận dùng song song cho bạn điều tốt nhất từ cả hai phía.
Workflow cross-model review có đáng công không?
Với các plan không tầm thường, chắc chắn là có. Cho Opus review output của GPT-5.4 rồi làm ngược lại sẽ bắt được các loại vấn đề khác nhau — Opus tìm edge case và sự thiếu nhất quán, còn GPT-5.4 bắt over-engineering. Hai hoặc ba vòng review như vậy cho ra plan chặt hơn hẳn so với chỉ dùng một model.
Một setup dual-tool tốn bao nhiêu tiền?
Claude Code nằm trong khoảng $100-200/tháng tùy gói. Giá Codex còn thay đổi — OpenAI hiện đang cho miễn phí một tháng. Ngay cả ở mức giá đầy đủ, việc chia workload giữa hai tool ở các tier thấp hơn có thể vẫn hiệu quả chi phí hơn so với max-out một tool duy nhất.
Có thể dùng plugin Claude Code trong Codex không?
Không trực tiếp, nhưng có thể adapt. Tôi dùng Codex để nghiên cứu các workflow plugin của Claude Code (/feature-dev, /code-review, /superpowers) rồi chuyển logic cốt lõi thành Codex skill trong ~/.codex/skills. Một số thứ rất riêng của Claude Code như hooks thì không dịch sang được, nhưng workflow thì có.
Đó là chia sẻ của tôi lúc này. Tôi cũng tò mò — có ai khác đang chạy workflow đa model không? Dùng Claude Code và Codex cùng nhau, hay những tổ hợp khác? Bạn đang thấy pattern gì?
Thân, Chandler





