Bereit für eine bessere Sucherfahrung mit Microsofts ChatGPT-Integration?
Microsofts ChatGPT-Bing-Integration löst Datenprobleme, aber die eigentliche Herausforderung liegt im Design einer Oberfläche, die weiß, wann eine Antwort gefragt ist und wann viele.
Dieser Beitrag wurde 2023 geschrieben. Einige Details können sich seitdem geändert haben.
Diese Woche berichteten einige Medien, dass Microsoft daran arbeitet, ChatGPT-Funktionen in die Bing-Suche zu integrieren. Da ich in der Vergangenheit über die Frage "Will chatGPT replace Google?" geschrieben habe, möchte ich hier einige zusätzliche Gedanken teilen.
Die Indexierung von Web-Inhalten ist keine Hürde mehr
Berichten zufolge hat Microsoft bereits 2019 $1 Milliarde in OpenAI investiert. Das bedeutet, dass die Partnerschaft zwischen den beiden Unternehmen seit mindestens drei Jahren besteht. Bing Search kann offensichtlich das Web indexieren, also müssen wir davon ausgehen, dass die Indexierung von Web-Inhalten kein Problem ist, wenn OpenAI den ChatGPT-Datensatz über 2021 hinaus erweitern möchte. Angesichts der Größe von Microsoft können wir auch annehmen, dass seine Echtzeit-Indexierungs-/Crawling-Fähigkeiten im Vergleich zu Google recht gut sind.
Bing hat bereits Bilder, Videoinhalte usw. in seinem Datensatz, also ist auch das keine Hürde für OpenAIs ChatGPT.
Bing Search kann Inhaltsvertrauenswürdigkeit relativ gut einschätzen
Obwohl ich keinen aktuellen Vergleich zwischen Google Search und Bing Search-Ergebnissen gemacht habe, ist es sicher zu sagen, dass der Abstand zwischen den Fähigkeiten der beiden Unternehmen bei der Bestimmung der Vertrauenswürdigkeit von Inhalten nicht sehr groß sein sollte. Also ist das Finden der genauesten Antwort mit Microsofts Hilfe auch keine große Hürde für OpenAI/ChatGPT.
Ein konkretes Beispiel: ChatGPT hat keine aktuellen Servicebewertungsdaten und kann daher keine Fragen zu lokalen Diensten wie "bester Klempner in meiner Nähe" oder "bestes chinesisches Restaurant in meiner Nähe" beantworten. Hier kommt der Microsoft-Datensatz ins Spiel.
Ein Problem der Benutzeroberfläche
Zwar gibt es ein gültiges Argument darüber, wie benutzerfreundlich die ChatGPT-Erfahrung ist, aber sie ist keine Einheitslösung für alle Fragen/Anfragen. In vielen Fällen wollen Nutzer mehrere Antworten. Zum Beispiel möchten Nutzer beim oben genannten lokalen Service oft eine Liste geeigneter Optionen sehen. Man könnte argumentieren, dass Nutzer in diesen Fällen ihre Eingabeaufforderung für ChatGPT auf "Gib mir 5 Optionen für den besten xyz-Service in meiner Nähe" vs. "der beste xyz-Service in meiner Nähe" anpassen müssen.
Ich würde jedoch argumentieren, dass das allein nicht ausreicht. Die Suchmaschine sollte intelligent genug sein zu erkennen, dass es in vielen Fällen keine einzige beste Antwort oder eine kurze Liste bester Antworten gibt. Die beste Antwort ist situations- und kontextabhängig.
Außerdem gibt es Fakten und es gibt Meinungen. Das sind grundlegend verschiedene Dinge.
Die Frage ist also, wie man eine Benutzeroberfläche gestaltet, die für mehrere Szenarien am besten geeignet ist. Zum Beispiel, selbst für etwas so Einfaches wie "Rezept für vietnamesisches Baguette" :D, das ist, was ich im Jan 2023 von Google, Bing und ChatGPT bekomme. Es ist nicht offensichtlich, welches besser ist oder ob die ChatGPT-Antwort besser ist.
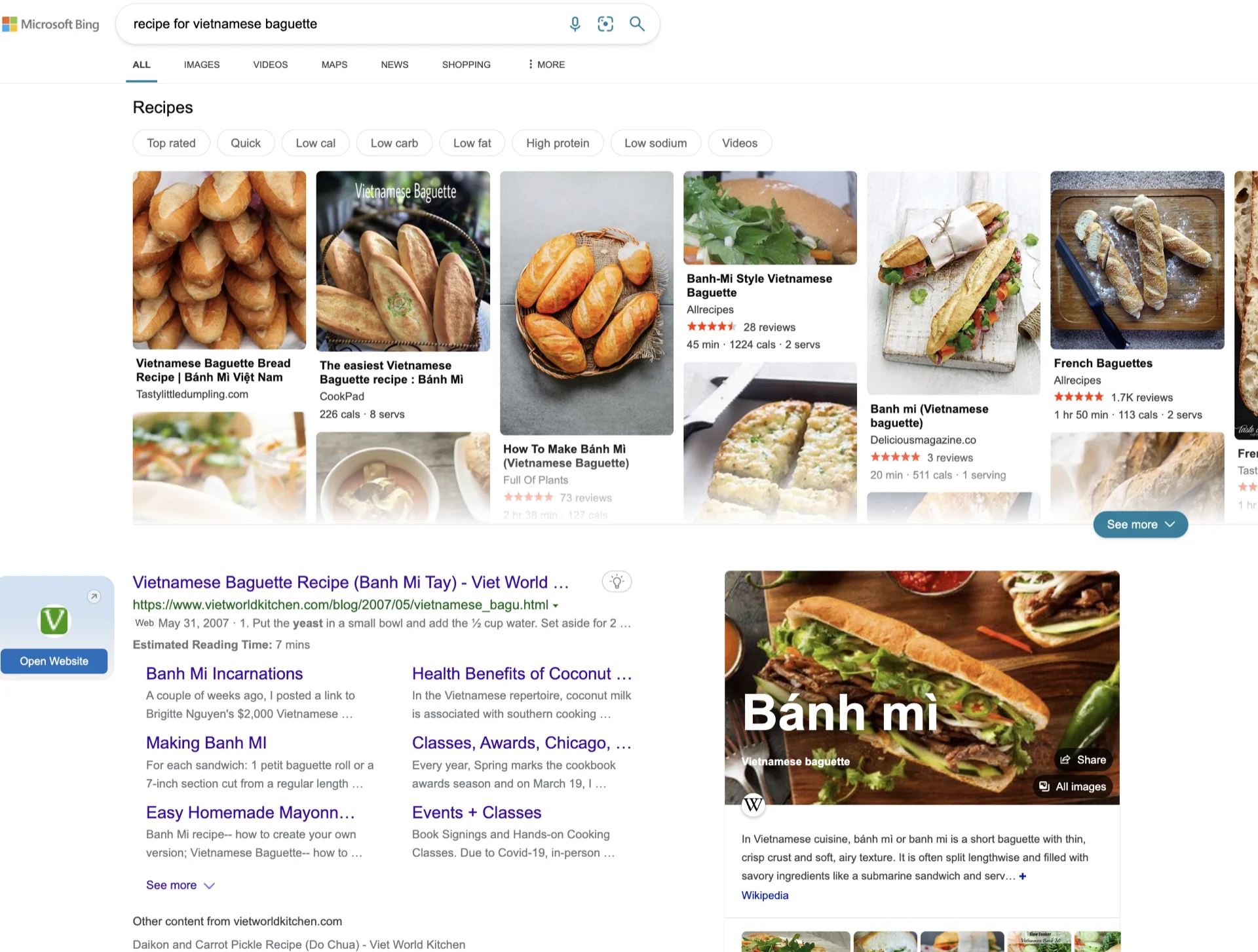
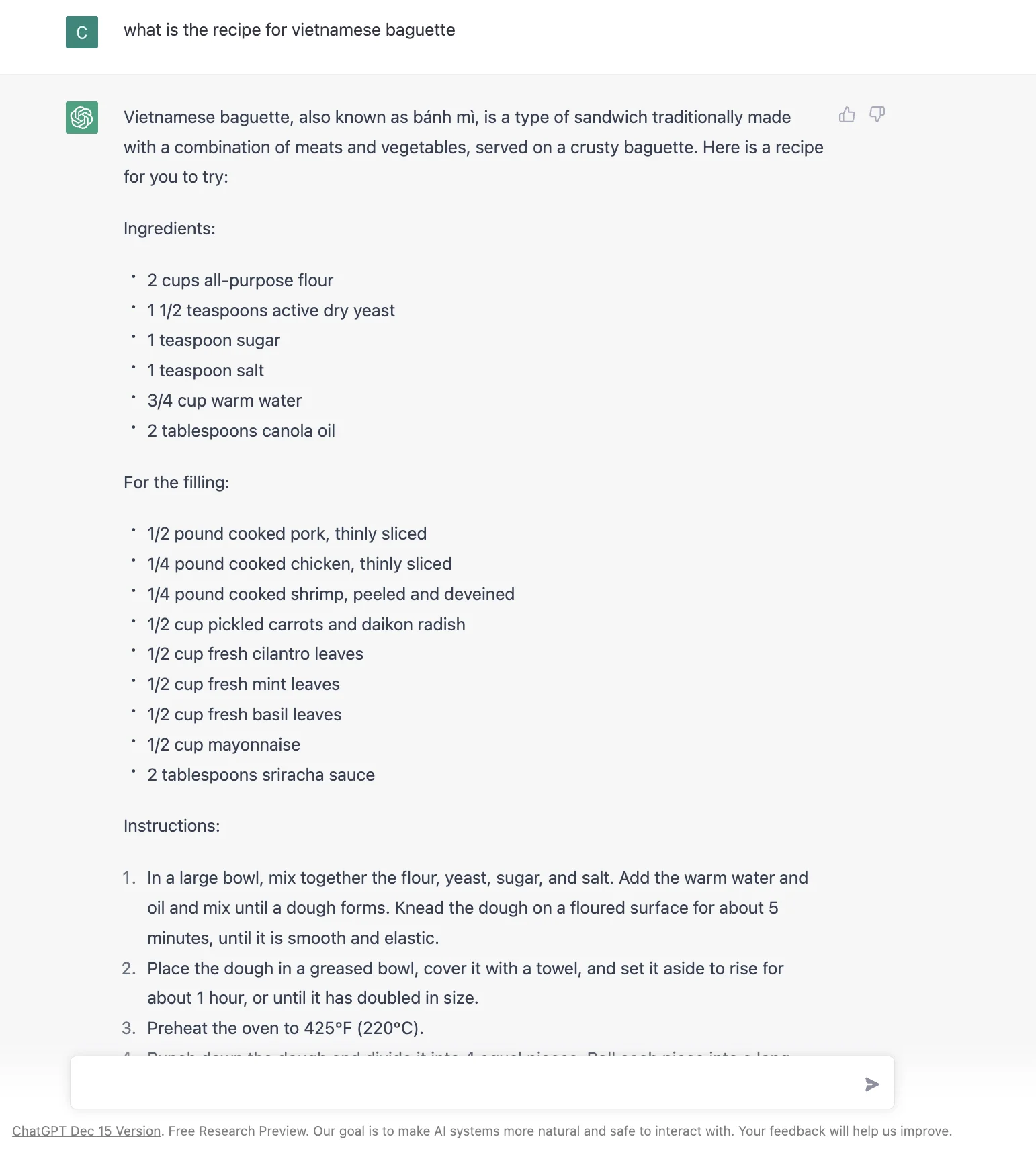
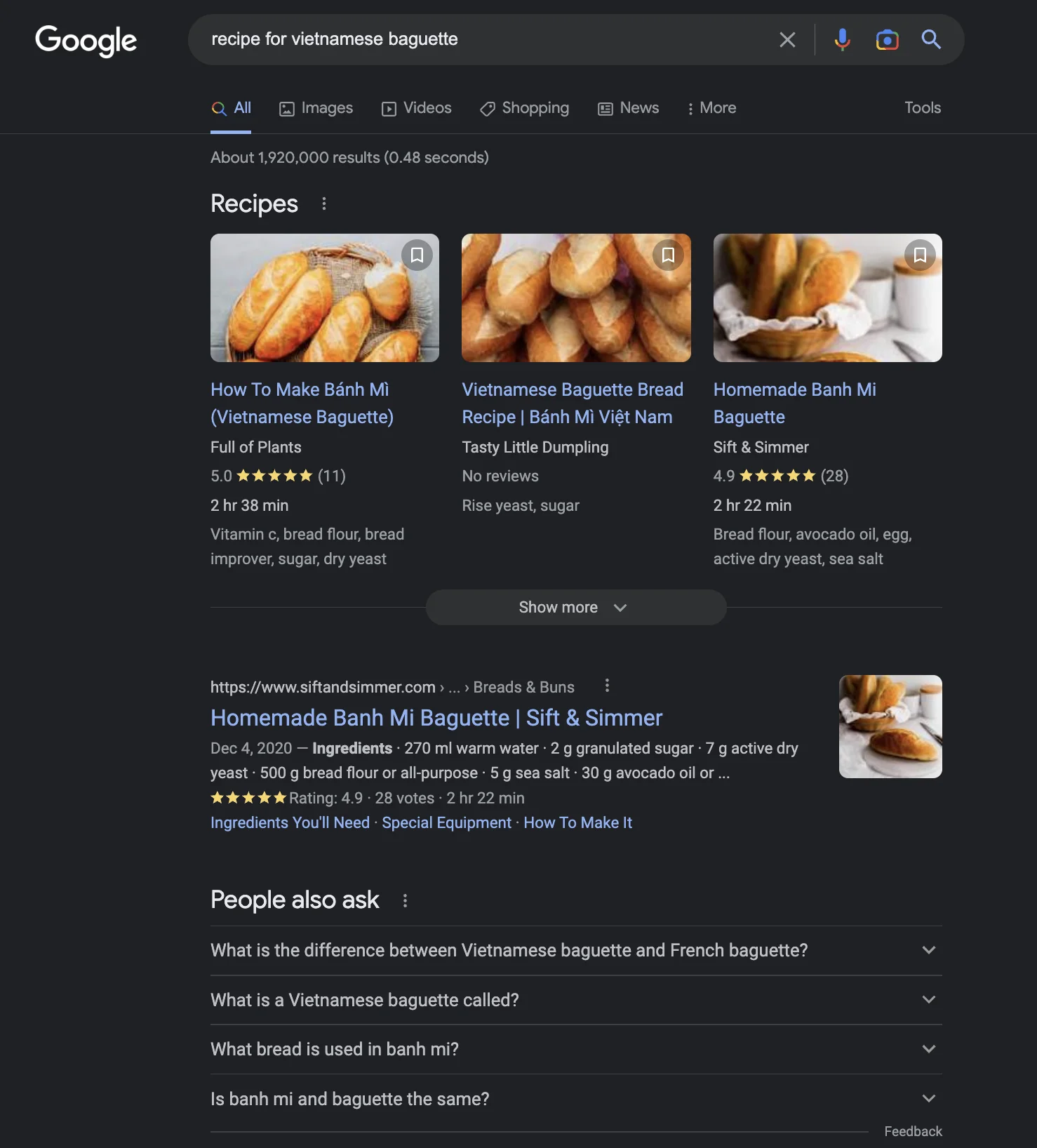
Der Schlüssel liegt dann darin, die Suchergebnis-Oberfläche dynamisch basierend auf der Nutzerabsicht mithilfe von maschinellem Lernen anzupassen. Ich bin nicht sicher, wie einfach oder schwierig das ist. Aber es scheint ein logischer Schritt zu sein, um die Stärke der Einzelantwort-Art von ChatGPT mit der einer Suchmaschine zu kombinieren.
Ein Sprachassistent
Ich würde argumentieren, dass das Liefern von Antworten aus einer reinen Informationssuchperspektive nicht der Grund ist, warum die Menschen ChatGPT mögen. Es ist die Fähigkeit, ChatGPT Kontext zu geben und es dann zu bitten, eine sprachbezogene Aufgabe zu erledigen – wie ein Gedicht, eine Einleitung, einen Aufsatz usw. zu schreiben.
Dieser Anwendungsfall unterscheidet sich stark von einer Suchmaschine und ist eher mit der Fähigkeit verwandt, PowerPoint-Narrationen zu generieren oder in Microsoft Word zu schreiben. Ich denke daher, dass die Neuigkeiten darüber, dass Microsoft verschiedene OpenAI-Fähigkeiten in die Office 365-Suite integriert, die eigentlich bessere Nachricht sind.
Die Grenzen der Sprache
Jacob Browning und Yann Lecun haben im August 2022, noch vor der öffentlichen Öffnung von ChatGPT, einen ausgezeichneten Artikel über AI and the limits of language geschrieben. Obwohl ihr Artikel auf LaMDA verwies, ist der Inhalt im Wesentlichen auch auf ChatGPT oder jedes andere Large Language Model anwendbar. Der Artikel ist lang; wenn du die Kernpunkte haben möchtest, sind sie hier:
Ein Google-Ingenieur erklärte kürzlich Googles KI-Chatbot LaMDA für eine Person, was zu verschiedenen Reaktionen führte. Der Chatbot LaMDA ist ein Large Language Model (LLM), das darauf ausgelegt ist, die wahrscheinlichsten nächsten Wörter zu jeder Textzeile vorherzusagen, die ihm gegeben wird.
Manche belächelten die Idee, während andere suggerierten, dass die nächste KI möglicherweise eine Person ist. Die Vielfalt der Reaktionen unterstreicht ein tieferes Problem: Je verbreiteter und mächtiger diese LLMs werden, desto weniger Einigkeit gibt es darüber, wie man sie versteht. Das zugrunde liegende Problem ist die begrenzte Natur der Sprache. Diese Systeme sind eindeutig zu einem oberflächlichen Verständnis verurteilt, das dem ganzheitlichen Denken, das wir bei Menschen sehen, niemals nahekommen wird. Das liegt daran, dass Sprache nur eine spezifische, begrenzte Art der Wissensrepräsentation ist. Sie eignet sich hervorragend, um diskrete Objekte und Eigenschaften sowie die Beziehungen zwischen ihnen auszudrücken, hat aber Schwierigkeiten, konkretere Informationen darzustellen, wie das Beschreiben von unregelmäßigen Formen oder der Bewegung von Objekten. Es gibt andere Repräsentationsschemata, wie ikonisches Wissen und verteiltes Wissen, die diese Informationen auf zugängliche Weise ausdrücken können.
Sprache ist eine Methode mit geringer Bandbreite zur Informationsübertragung und oft mehrdeutig aufgrund von Homonymen und Pronomen. Menschen brauchen kein perfektes Kommunikationsmittel, weil wir ein nichtsprachliches Verständnis teilen. Large Language Models werden trainiert, das Hintergrundwissen für jeden Satz aufzugreifen und die umgebenden Wörter und Sätze zu nutzen, um zu verstehen, was vor sich geht. LLMs haben ein oberflächliches Sprachverständnis erworben, aber dieses Verständnis ist begrenzt und beinhaltet nicht das Know-how für komplexere Gespräche. Infolgedessen ist es einfach, sie durch Inkonsistenz oder Sprachwechsel zu täuschen. LLMs fehlt das Verständnis, das für die Entwicklung eines kohärenten Weltbildes notwendig ist.
Während Sprache viele Informationen in einem kleinen Format übermitteln kann, ist ein großer Teil des menschlichen Wissens nichtsprachlich und kann durch andere Mittel wie Diagramme, Karten, Artefakte und soziale Bräuche vermittelt werden. Es deutet darauf hin, dass eine Maschine, die allein auf Sprache trainiert wird, menschliche Intelligenz nicht vollständig annähern kann, weil sie nur Zugang zu einem kleinen Teil des menschlichen Wissens durch einen engen Engpass hat und dass das tiefe nichtsprachliche Verständnis der Welt notwendig ist, damit Sprache nützlich ist. Es impliziert auch, dass es Grenzen dafür gibt, wie intelligent Maschinen sein können, wenn sie ausschließlich auf Sprache trainiert werden.
Das war mein Beitrag. Was denkst du? Siehst du dich von Google zu einem ChatGPT-gestützten Bing wechseln, oder hält dich die Gewohnheit bei Google? :)
Viele Grüße,
Chandler