"Bing AI를 신뢰할 수 없다"에 대한 반응
Bing AI가 재무 데이터를 조작한다는 팩트체커의 주장을 제가 직접 팩트체크해 봤습니다 — 결과적으로 수치를 지어내는 문제는 실재하며 제가 바랐던 것보다 심각했습니다.
이 글은 2023에 작성되었습니다. 이후 일부 내용이 달라졌을 수 있습니다.
오늘 Bing AI를 신뢰할 수 없다라는 기사를 접했고, 당연히 관심이 갔습니다. 새로운 Bing Chat이 사실적 정보에 대해 많은 날조된 사실을 포함하고 있음을 팩트체크로 보여주는 좋은 기사입니다. 비교적 짧은 글이니 직접 읽어보시기 바랍니다.
저의 몇 가지 빠른 반응입니다:
놀랍기도 하고 놀랍지 않기도 합니다
대규모 언어 모델(LLM)의 한계에 대해 일반적으로 알고 있으며, ChatGPT도 그 중 하나입니다. 세 가지 주요 한계는 다음과 같습니다:
- 텍스트 데이터 이외의 웹을 인덱싱하지 못합니다 (비디오, 오디오, 이미지 등)
- ChatGPT 데이터셋은 정말 오래되었습니다 (2021년)
- 이 모델들은 어떤 정보 출처가 다른 것보다 더 권위 있고 신뢰할 수 있는지 모르기 때문에 단어를 지어냅니다.
그래서 Bing & OpenAI 통합으로 Bing 검색 엔진이 위의 모든 한계를 해결할 수 있기를 바랐습니다. 글쎄요, Dmitri의 기사에 따르면 Bing은 아직 해결하지 못한 것 같습니다. 전혀요.
기사를 다시 팩트체크하기
Dmitri가 언급한 내용이 사실이 아니라면 그것도 좋지 않을 것입니다. 그래서 직접 몇 가지 팩트체크를 진행했습니다. Gap 재무제표로 시작했는데, 가장 직접적으로 확인할 수 있을 것 같았기 때문입니다. 이 과정을 반복하지 않아도 되도록 출처와 스크린샷을 아래에 포함합니다:
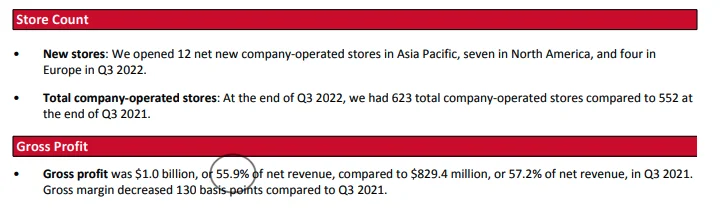
- 이것은 Gap 2022년 3분기 실적 발표입니다.
- 아래 Gap 보고서에서 스크린샷을 찍고 핵심 수치를 빨간색으로 강조했습니다. Dmitri가 옳았습니다. Bing Chat이 조정 매출총이익률, 영업이익률 등의 수치를 지어냈습니다.

Lululemon 수치는 어떨까요?
- 이것은 Lululemon의 2022년 3분기 재무 보고서입니다. 마찬가지로 Dmitri의 기사에서 언급된 핵심 수치를 아래 스크린샷에서 강조했습니다. 그가 옳았습니다. Bing 검색이 수치를 지어냈습니다.

멕시코시티 여행 일정에 대해서는 이 주제의 전문가가 아니라서 신중하게 팩트체크할 수 없습니다. 예를 들어 "Primer Nivel Night Club - Antro"를 검색했을 때 이 Facebook 페이지를 찾았습니다. 하지만 Bing 검색의 제안이 유효한지 100% 확실하게 검증할 방법이 없습니다.
여기서 어디로 갈 수 있을까요?
현 시점에서 Bing & OpenAI 통합이 대규모 언어 모델(LLM)이 그냥 내용을 지어내는 문제를 아직 해결하지 못한 것은 분명해 보입니다.
이 문제를 해결하는 것이 기술적으로 얼마나 어려운지 이해할 만큼 기술적이지 않습니다. 사실적 데이터에서 이렇게 부정확하다면, 최고의 레스토랑/배관공/지역 서비스, 개인 재정, 건강, 관계 등과 같은 더 주관적인 주제에 대해서는 조심해야 합니다.
공정하게 말하자면, Bing과 OpenAI는 프레젠테이션 중에 새 기술이 많은 것을 틀릴 수 있다는 것을 이해한다고 말했고, 그래서 사용자가 쉽게 피드백을 줄 수 있도록 "좋아요/싫어요" 인터페이스를 설계했습니다. 사용자 피드백이 더 많아지면 기계가 더 나아지기를 바랍니다.
LLM 출력을 팩트체크하는 알고리즘?
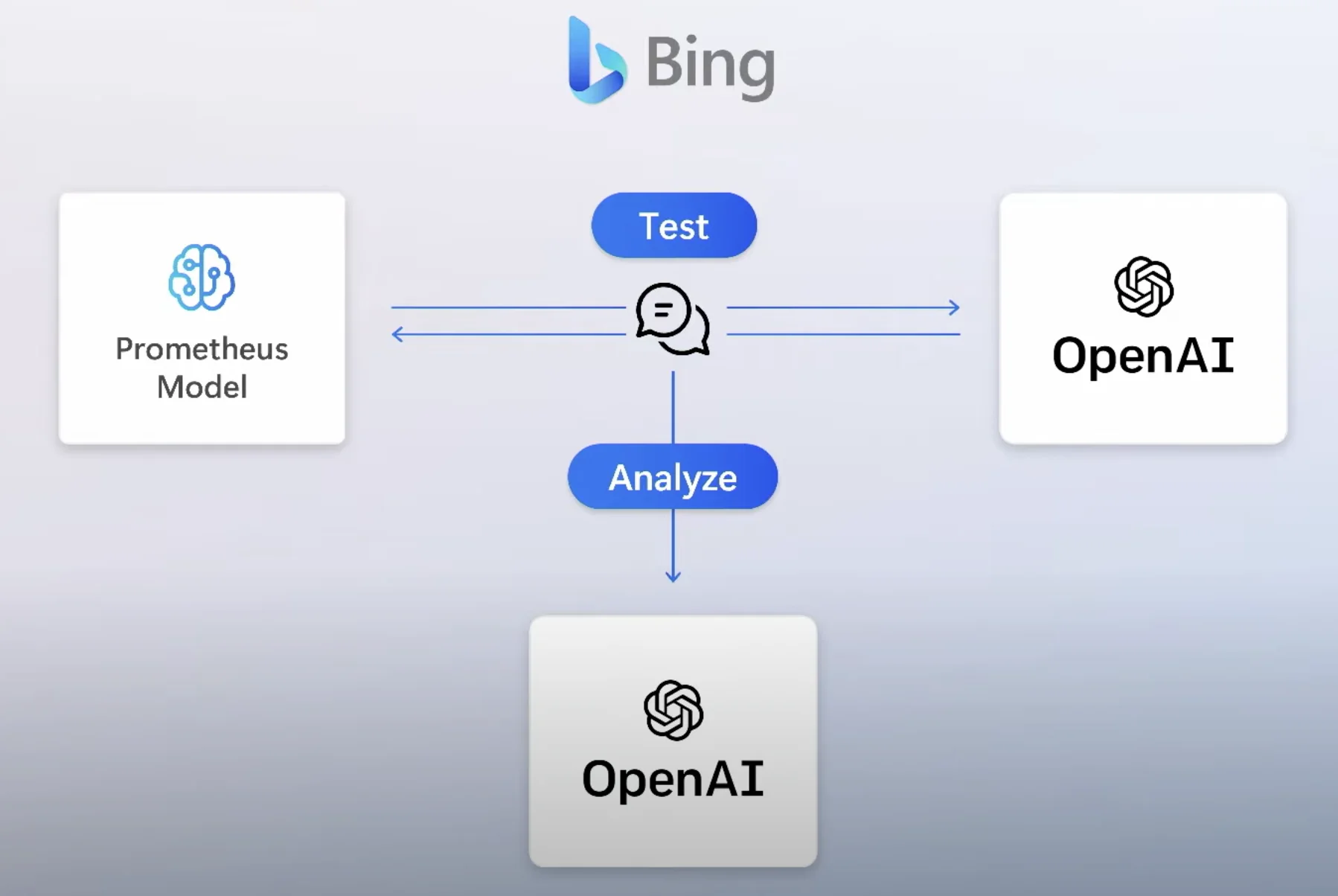
LLM이 종종 잘못된 출력을 생성하므로, 출력을 지속적으로 팩트체크하는 알고리즘을 만드는 것은 어떨까요? 이것은 Microsoft가 Prometheus에 구축한 안전 알고리즘, 즉 악의적 행위자의 프롬프트를 기계에 시뮬레이션하는 것과 유사합니다.
인간의 역할
이 기술은 아직 초기 단계에 있는 것 같으며, 발전은 기하급수적이지만, 인간의 역할이 중요합니다. Bing & OpenAI 통합에도 불구하고 아직 출력을 신뢰할 수 없습니다. 기계가 원하는 결과의 50%(다소 차이는 있지만)를 도와줄 수 있지만, 나머지 50%는 우리가 투입해야 합니다.
우리가 이 기술의 강점과 한계를 적응하고 배우며 효과적으로 활용할 수 있는 충분한 시간이 있는 것 같습니다.
이런 시스템을 설계하는 엔지니어들에게는, 기계가 확신하지 못하는 데이터 포인트와 문장을 최종 사용자에게 더 잘 강조해 줄 필요가 있을 것 같습니다. 우리의 인간 두뇌는 지름길을 좋아하므로, 많은 사람들이(저 포함) 게으른 방법을 택하고 기계가 말하는 것을 진실로 받아들일 것이 확실합니다 :P 항상 100% 경계하기는 어렵습니다.
AI가 생성한 답변 중 자신 있게 틀린 것을 발견한 적이 있으신가요? 구체적인 예시를 들어주시면 좋겠습니다.
감사합니다,
Chandler