Este post foi escrito em 2023. Alguns detalhes podem ter mudado desde então.
Esta semana, alguns veículos noticiaram que a Microsoft está trabalhando pra incorporar recursos do ChatGPT ao Bing Search. Como já escrevi sobre "o ChatGPT vai substituir o Google?" antes, quero compartilhar algumas reflexões adicionais aqui.
A indexação de conteúdo da web não é mais uma barreira.
A Microsoft supostamente investiu $1 bilhão na OpenAI em 2019. Isso significa que a parceria entre as duas empresas já dura pelo menos três anos. O Bing Search claramente indexa a web, então podemos assumir que a indexação de conteúdo não é um problema se a OpenAI quiser expandir o dataset do ChatGPT além de 2021. Dada a escala da Microsoft, podemos assumir que sua capacidade de indexação/rastreamento em tempo real também é bastante boa comparada ao Google.
O Bing já tem imagens, vídeos, etc... como parte do seu dataset, então isso também não será uma barreira pra o ChatGPT da OpenAI.
O Bing Search consegue classificar a confiabilidade do conteúdo relativamente bem
Embora não tenha olhado a comparação mais recente entre os resultados do Google Search e do Bing Search, é seguro dizer que a diferença entre as capacidades das duas empresas em determinar a confiabilidade de um conteúdo não deve ser tão grande. Então, novamente, com a ajuda da Microsoft, encontrar a resposta mais precisa pode não ser um grande obstáculo pra OpenAI/ChatGPT.
Um exemplo específico é que o ChatGPT não tem dados atualizados de avaliações de serviços, então não consegue responder perguntas sobre serviços locais como "melhor encanador perto de mim" ou "melhor restaurante chinês perto de mim". É aí que o dataset da Microsoft entra pra ajudar.
Um problema de interface de usuário
Embora haja um argumento válido sobre o quão amigável é a experiência do ChatGPT, ela não serve pra todos os tipos de perguntas/consultas. Em muitos casos, os usuários querem ter várias respostas. Por exemplo, com o mesmo serviço local acima, os usuários muitas vezes querem ver uma lista de opções adequadas. Pode-se argumentar que nesses casos, os usuários precisariam modificar o prompt pro ChatGPT para "me dê 5 opções do melhor serviço xyz perto de mim" vs. "o melhor serviço xyz perto de mim."
Porém, argumentaria que fazer isso não é suficiente. O mecanismo de busca deve ser inteligente o suficiente pra saber que, em muitos casos, não existe uma única melhor resposta ou uma lista curta das melhores respostas. A melhor resposta depende da situação/contexto.
Além disso, temos fatos e temos opiniões. Eles são completamente diferentes entre si.
Então, como criar uma interface de usuário que seja a melhor pra múltiplos cenários é a chave. Por exemplo, mesmo pra algo tão simples como "receita de banh mi vietnamita" :D, isso é o que obtenho do Google, Bing e ChatGPT em jan 2023. Não é óbvio qual é melhor ou se a resposta do ChatGPT é mais adequada.
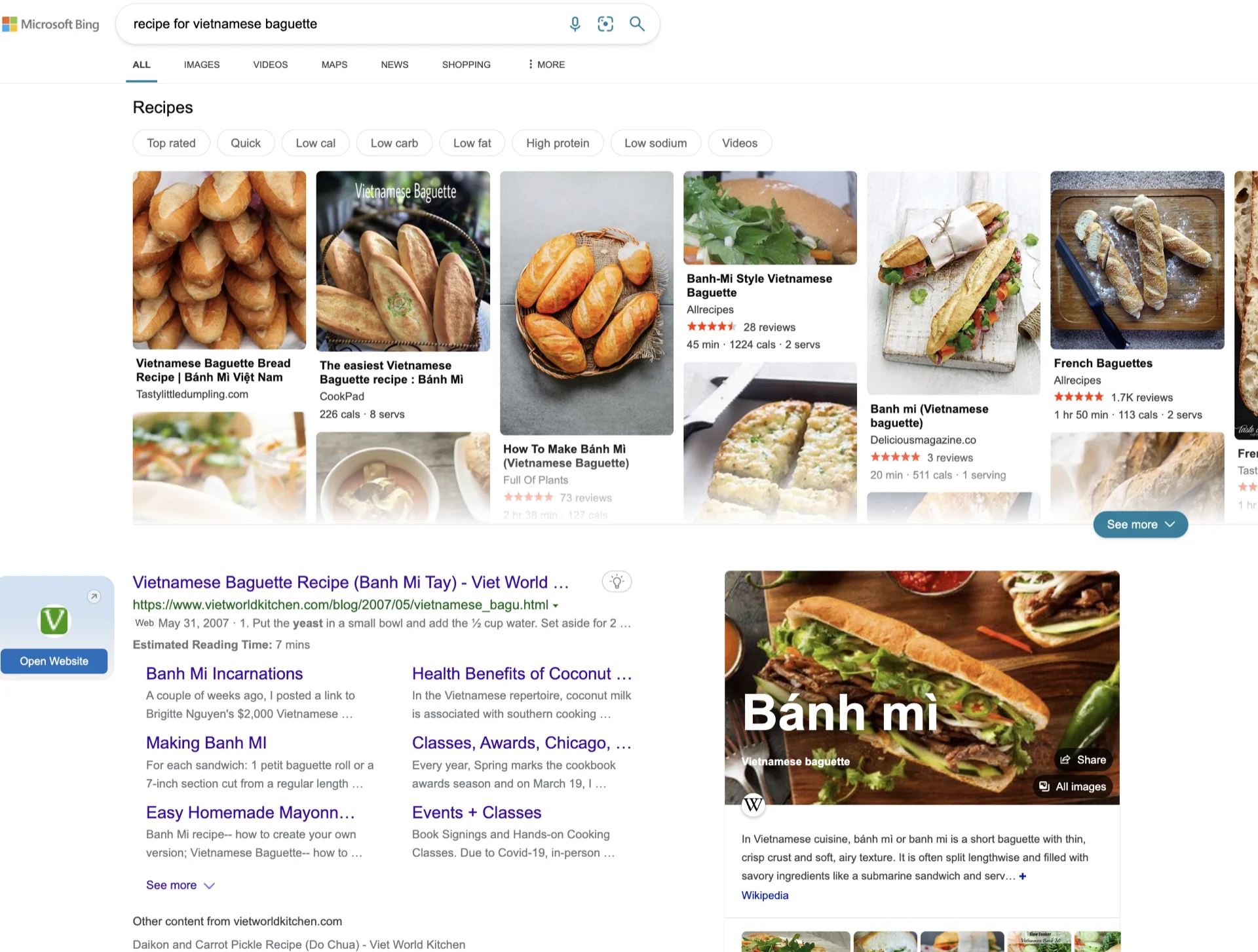
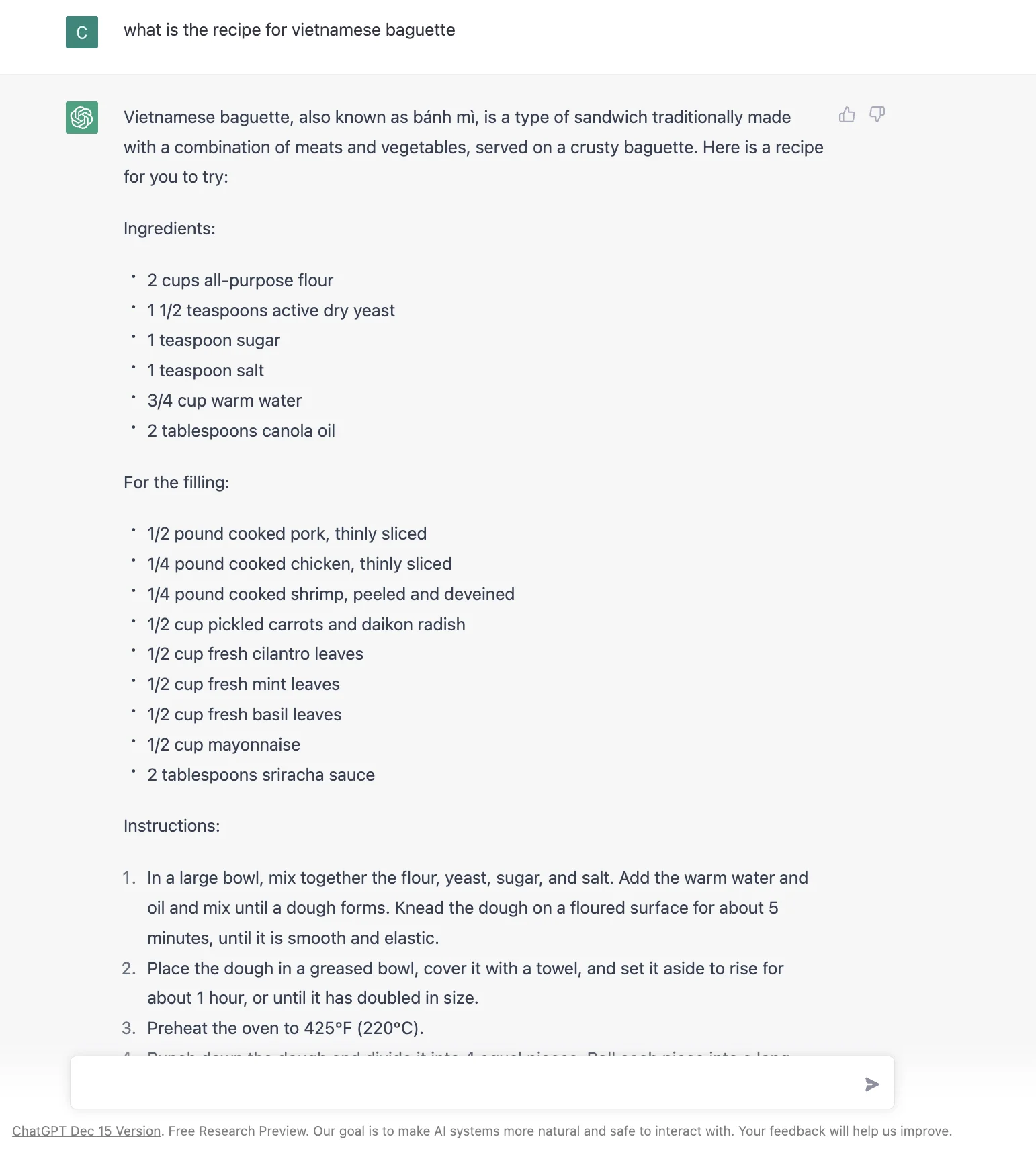
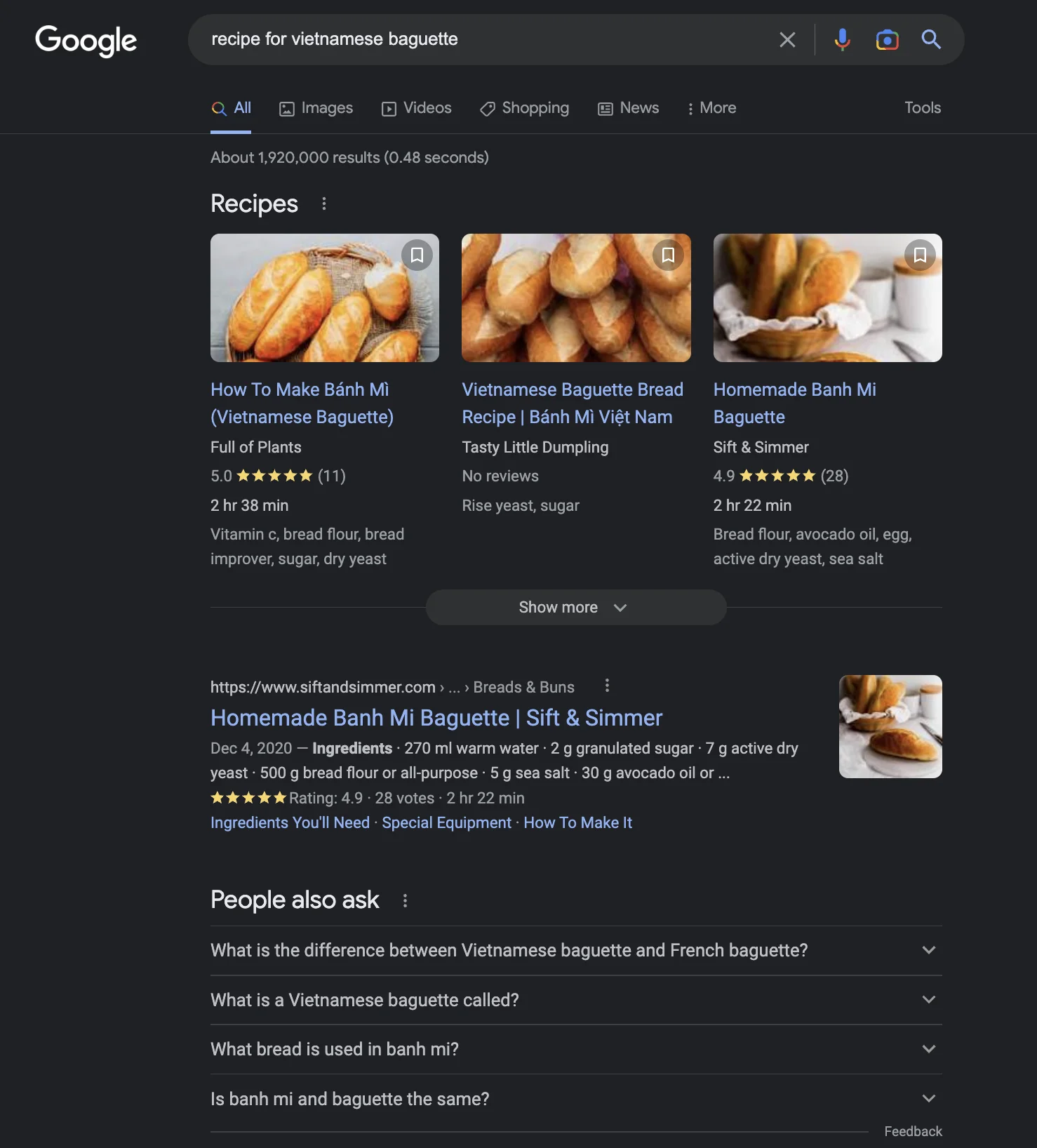
A chave então é mudar dinamicamente a interface de resultados de busca com base na intenção do usuário, usando machine learning. Não tenho certeza de quão fácil ou difícil isso é. Mas parece um passo lógico combinar o estilo de resposta única do ChatGPT com a força de um mecanismo de busca.
Um assistente de linguagem
Argumentaria que fornecer respostas de uma perspectiva de busca de informações pura não é o motivo pelo qual as pessoas gostam do ChatGPT — é a capacidade de dar contexto ao ChatGPT e pedir que ele complete uma tarefa relacionada à linguagem, como escrever um poema, uma introdução, um ensaio, etc...
Esse caso de uso é muito diferente de um mecanismo de busca e está mais relacionado à capacidade de gerar narrativas no PowerPoint ou escrever no Microsoft Word. Por isso, na verdade acho que a notícia sobre a Microsoft incorporar diferentes capacidades da OpenAI à suite Office 365 é uma notícia melhor.
Os limites da linguagem
Jacob Browning e Yann Lecun escreveram um excelente artigo sobre IA e os limites da linguagem em ago 2022, antes do ChatGPT ser aberto ao público. Embora o artigo referenciasse o LaMDA, o conteúdo é essencialmente aplicável ao ChatGPT ou a qualquer outro Large Language Model. O artigo é longo, então se você quiser os pontos principais, aqui estão:
Um engenheiro do Google declarou recentemente que o chatbot de IA da empresa, o LaMDA, é uma pessoa, gerando uma variedade de reações. O chatbot LaMDA é um large language model (LLM) projetado pra prever as próximas palavras prováveis para qualquer sequência de texto fornecida.
Algumas pessoas ridicularizaram a ideia, enquanto outras sugeriram que a próxima IA pode ser uma pessoa. A diversidade de reações destaca um problema mais profundo: à medida que esses LLMs se tornam mais comuns e poderosos, há menos consenso sobre como entendê-los. O problema subjacente é a natureza limitada da linguagem. É claro que esses sistemas estão condenados a uma compreensão superficial que nunca vai se aproximar do pensamento completo que vemos nos humanos. Isso porque a linguagem é apenas um tipo específico e limitado de representação do conhecimento. Ela se destaca em expressar objetos e propriedades discretas e as relações entre eles, mas tem dificuldade em representar informações mais concretas, como descrever formas irregulares ou o movimento dos objetos. Há outros esquemas representacionais, como conhecimento icônico e conhecimento distribuído, que podem expressar essas informações de forma acessível.
A linguagem é um método de baixa largura de banda pra transmitir informações e frequentemente é ambígua por causa de homônimos e pronomes. Os humanos não precisam de um veículo perfeito de comunicação porque compartilham uma compreensão não linguística. Os Large Language Models são treinados pra captar o conhecimento de fundo de cada frase, olhando as palavras e frases ao redor pra entender o que está acontecendo. Os LLMs adquiriram uma compreensão superficial da linguagem, mas essa compreensão é limitada e não inclui o know-how pra conversas mais complexas. Como resultado, é fácil enganá-los sendo inconsistente ou mudando de idioma. Os LLMs carecem da compreensão necessária pra desenvolver uma visão coerente do mundo.
Embora a linguagem possa transmitir muita informação em um formato pequeno, grande parte do conhecimento humano é não linguístico e pode ser transmitido por outros meios, como diagramas, mapas, artefatos e costumes sociais. Isso sugere que uma máquina treinada apenas em linguagem não será capaz de aproximar totalmente a inteligência humana porque só tem acesso a uma pequena parte do conhecimento humano através de um gargalo estreito, e que a compreensão não linguística profunda do mundo é necessária pra a linguagem ser útil. Também implica que há limites pra quão inteligentes as máquinas podem ser se treinadas apenas em linguagem.
É isso da minha parte. O que você acha? Você se vê migrando do Google pra um Bing com ChatGPT, ou o hábito te mantém no Google? :)
Abraços,
Chandler