Reações ao artigo "Bing AI não pode ser confiado"
Fiz fact-checking das afirmações do artigo sobre o Bing AI fabricando dados financeiros — e o problema dos números inventados é real e pior do que eu esperava.
Este post foi escrito em 2023. Alguns detalhes podem ter mudado desde então.
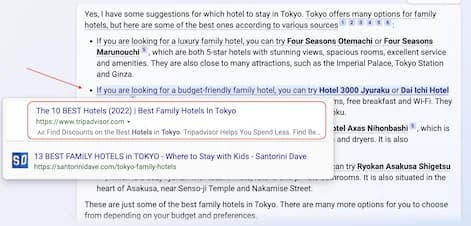
Deparei com este artigo hoje: Bing AI can't be trusted, e naturalmente despertou meu interesse. É um bom artigo cheio de fact checks que mostram que o novo Bing Chat inclui muitos fatos inventados sobre informações factuais. O post é relativamente curto, então vá em frente e leia.
Aqui estão algumas reações rápidas:
Surpreso e não surpreso ao mesmo tempo
Em geral, estou ciente das limitações dos large language models (LLMs), do qual o ChatGPT é um exemplo. As três principais são:
- Não indexam a web além de dados de texto (como vídeo, áudio, imagens, etc…)
- O conjunto de dados do ChatGPT é muito antigo (2021)
- Esses modelos inventam palavras porque não sabem qual fonte de informação é mais autoritativa/confiável do que outra.
Então eu esperava que com a integração Bing e OpenAI, o mecanismo de busca do Bing pudesse resolver todas as limitações acima. Bom, parece que com base no artigo do Dmitri, o Bing ainda não resolveu isso. Nem perto. 🙁
Fact-check do artigo de novo
Não seria ótimo descobrir que o que Dmitri mencionou também não era factualmente correto. Então fiz alguns fact-checks por conta própria. Comecei com as demonstrações financeiras da Gap porque parece o mais direto de verificar. Incluí as fontes e capturas de tela abaixo para que você não precise repetir esse exercício:
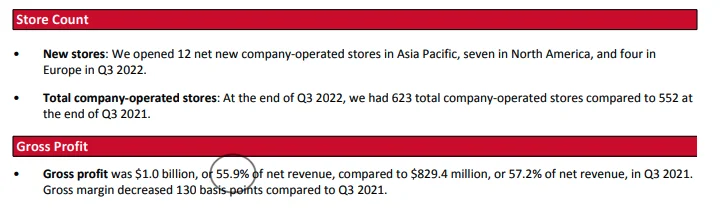
- Este é o resultado do Q3 2022 da Gap.
- Tirei a captura de tela abaixo do demonstrativo da Gap e destaquei os números-chave em vermelho. Dmitri está certo, o Bing Chat inventou os números como margem bruta ajustada, margem operacional, etc…

E os números da Lululemon?
- Este é o relatório financeiro Q3 2022 da Lululemon. Mesma coisa, destaquei os números-chave mencionados no artigo do Dmitri nas capturas de tela abaixo. Ele está certo, o Bing Search inventou os números.

Quanto ao roteiro da Cidade do México, não sou especialista nesse tópico, então não posso fazer um fact-check cuidadoso. Por exemplo, quando procurei por "Primer Nivel Night Club - Antro", encontrei esta página do Facebook. Mas não tenho como verificar com 100% de certeza se as sugestões do Bing Search são válidas ou não.
Para onde vamos a partir daqui?
Parece claro que neste momento, a integração Bing & OpenAI ainda não conseguiu resolver o problema de os large language models (LLMs) simplesmente inventarem coisas enquanto avançam.
Não tenho conhecimento técnico suficiente para entender o quão difícil é resolver esse problema. Se fica tão impreciso com dados factuais, precisamos ter cuidado com tópicos mais subjetivos como melhores restaurantes/encanadores/serviços locais, finanças pessoais, saúde, relacionamentos, etc.
Para ser justo com o Bing e a OpenAI, eles disseram durante a apresentação que entendem que a nova tecnologia pode errar em muitas coisas, então projetaram a interface de "polegar para cima/polegar para baixo" para que os usuários possam dar feedback facilmente. Com mais feedback dos usuários, a máquina vai melhorar.
Um algoritmo para fazer fact-check do output dos LLMs?
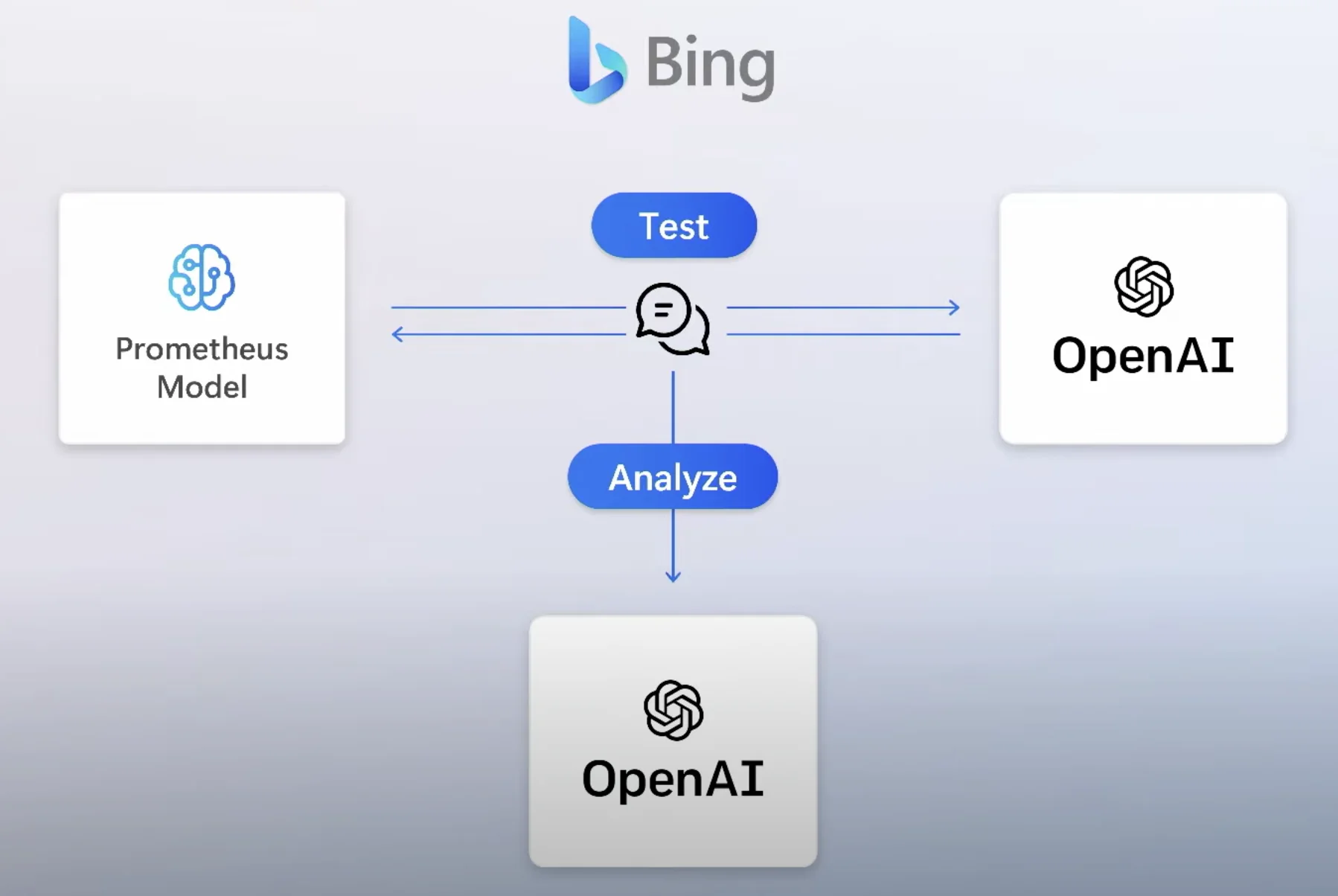
Como os LLMs frequentemente produzem outputs errados, que tal criar um algoritmo para fazer fact-check do output continuamente? Isso é similar ao que a Microsoft falou sobre o algoritmo de segurança que construíram no Prometheus, simulando prompts de agentes maliciosos para a máquina.
O papel do humano
Essa tecnologia parece estar em fase inicial, e embora o progresso seja exponencial, o papel do humano é crítico. Ainda não podemos confiar no output, mesmo com a integração Bing & OpenAI. A máquina pode nos ajudar com 50% do resultado desejado (mais ou menos), mas precisamos colocar os outros 50%.
Parece que há tempo suficiente para nos ajustar, aprender os pontos fortes e as limitações dessa tecnologia, e usá-la efetivamente.
Quanto aos engenheiros que projetam esses sistemas, vocês provavelmente precisam fazer um trabalho melhor de destacar para os usuários finais os pontos de dados e frases sobre os quais a máquina não tem certeza. Nossos cérebros humanos gostam de atalhos, então tenho certeza de que muitos de nós (eu incluído) vamos tomar o caminho fácil e aceitar o que a máquina diz como verdade :P É difícil para nós ficarmos em guarda 100% do tempo.
Você já pegou respostas geradas por IA que estavam confidentemente erradas? Adoraria ouvir seus exemplos — quanto mais específicos, melhor.
Abraços,
Chandler