Maghanda para sa Mas Magandang Search Experience gamit ang ChatGPT Integration ng Microsoft?
Niresolba ng ChatGPT-Bing integration ng Microsoft ang mga problema sa data, pero ang tunay na hamon ay ang pagdidisenyo ng interface na nakakaalam kung kailan magbigay ng isang sagot vs. marami.
Ang post na ito ay isinulat noong 2023. Maaaring may mga detalyeng nagbago na mula noon.
Ngayong linggo, may mga news outlets na nag-ulat na ang Microsoft ay nagtatrabaho upang isama ang mga ChatGPT features sa Bing Search. Dahil nagsulat ako tungkol sa "will chatGPT replace Google?" dati, gusto kong magbigay ng karagdagang mga pag-iisip dito.
Hindi na hadlang ang pag-index ng web content.
Ayon sa mga ulat, ang Microsoft ay nag-invest ng $1 billion sa OpenAI noong 2019. Ibig sabihin, ang partnership sa pagitan ng dalawang kumpanya ay umiiral na ng hindi bababa sa tatlong taon. Malinaw na kaya ng Bing Search i-index ang web, kaya kailangan nating ipagpalagay na ang web content indexing ay hindi isyu kung gusto ng OpenAI na palawakin ang chatGPT dataset lampas sa 2021. Dahil sa scale ng Microsoft, puwede nating ipagpalagay na ang realtime indexing/crawling capability nila ay dapat na medyo maganda rin vs. sa Google.
Mayroon nang Bing ng image, video content, atbp... bilang bahagi ng dataset nito kaya muli, hindi ito magiging hadlang para sa chatGPT ng OpenAI.
Medyo magaling ang Bing Search sa pag-rank ng content trustworthiness
Kahit hindi ko pa tingnan ang pinakabagong comparison sa pagitan ng Google Search at Bing Search results, safe sabihing ang gap sa pagitan ng kakayahan ng dalawang kumpanya sa pagtukoy ng trustworthiness ng isang piraso ng content ay hindi dapat masyadong malaki. Kaya muli, sa tulong ng Microsoft, ang paghahanap ng pinaka-accurate na sagot ay maaaring hindi malaking hadlang para sa OpenAI/chatGPT.
Isang specific na halimbawa ay hindi updated ang service rating data ng chatGPT, kaya hindi nito masasagot ang mga tanong tungkol sa local services tulad ng "best plumber near me" o "best Chinese restaurant near me." Dito pumapasok ang Microsoft dataset para tumulong.
Isang user interface problem
Kahit may valid na argumento tungkol sa kung gaano ka-user-friendly ang ChatGPT experience, hindi ito ang one size fit experience para sa lahat ng tanong/queries. Sa maraming pagkakataon, gusto ng mga users na magkaroon ng maraming sagot. Halimbawa, sa parehong local service sa itaas, madalas gusto ng mga users na makita ang listahan ng mga suitable na pagpipilian. Puwedeng i-argue na sa mga kasong iyon, kailangan ng mga users na baguhin ang prompt para sa ChatGPT na "give me 5 choices of the best xyz service near me" vs. "the best xyz service near me."
Subalit, i-argue ko na ang paggawa nito ay hindi sapat. Dapat maging sapat na intelligent ang search engine para malaman na sa maraming pagkakataon, walang iisang pinakamahusay na sagot o maikling listahan ng pinakamahusay na sagot. Ang pinakamahusay na sagot ay nakadepende sa sitwasyon/konteksto.
Bukod pa rito, mayroon tayong facts at mayroon tayong opinions. Ganap na magkaiba ang mga ito sa isa't isa.
Kaya kung paano mag-disenyo ng user interface na pinakamainam para sa maraming senaryo ang susi. Halimbawa, kahit para sa simpleng bagay tulad ng "recipe for Vietnamese baguette" :D, ito ang nakukuha ko mula sa Google, Bing at ChatGPT noong Jan 2023. Hindi obvious kung alin ang mas maganda o kung mas maganda ang sagot ng chatGPT.
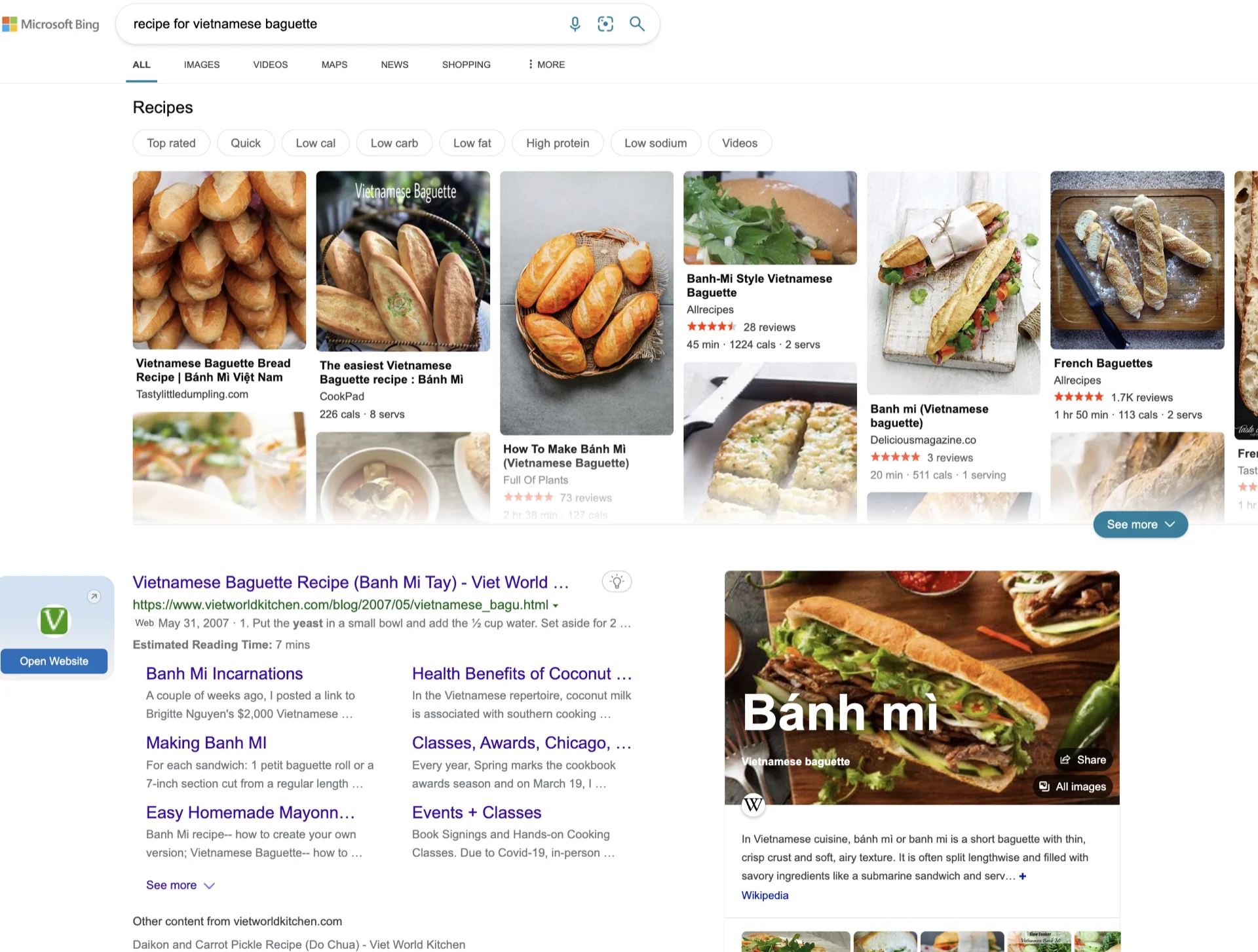
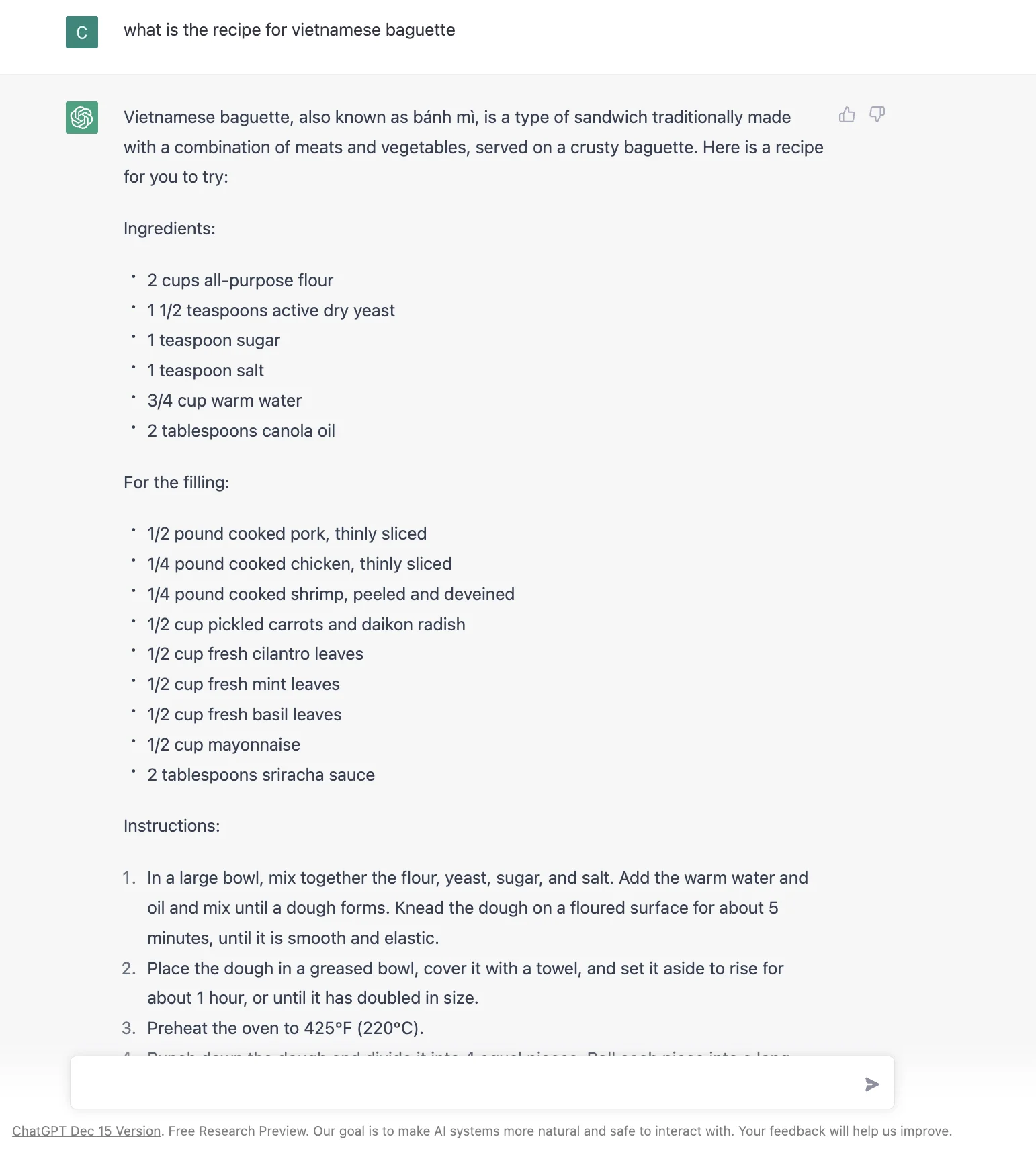
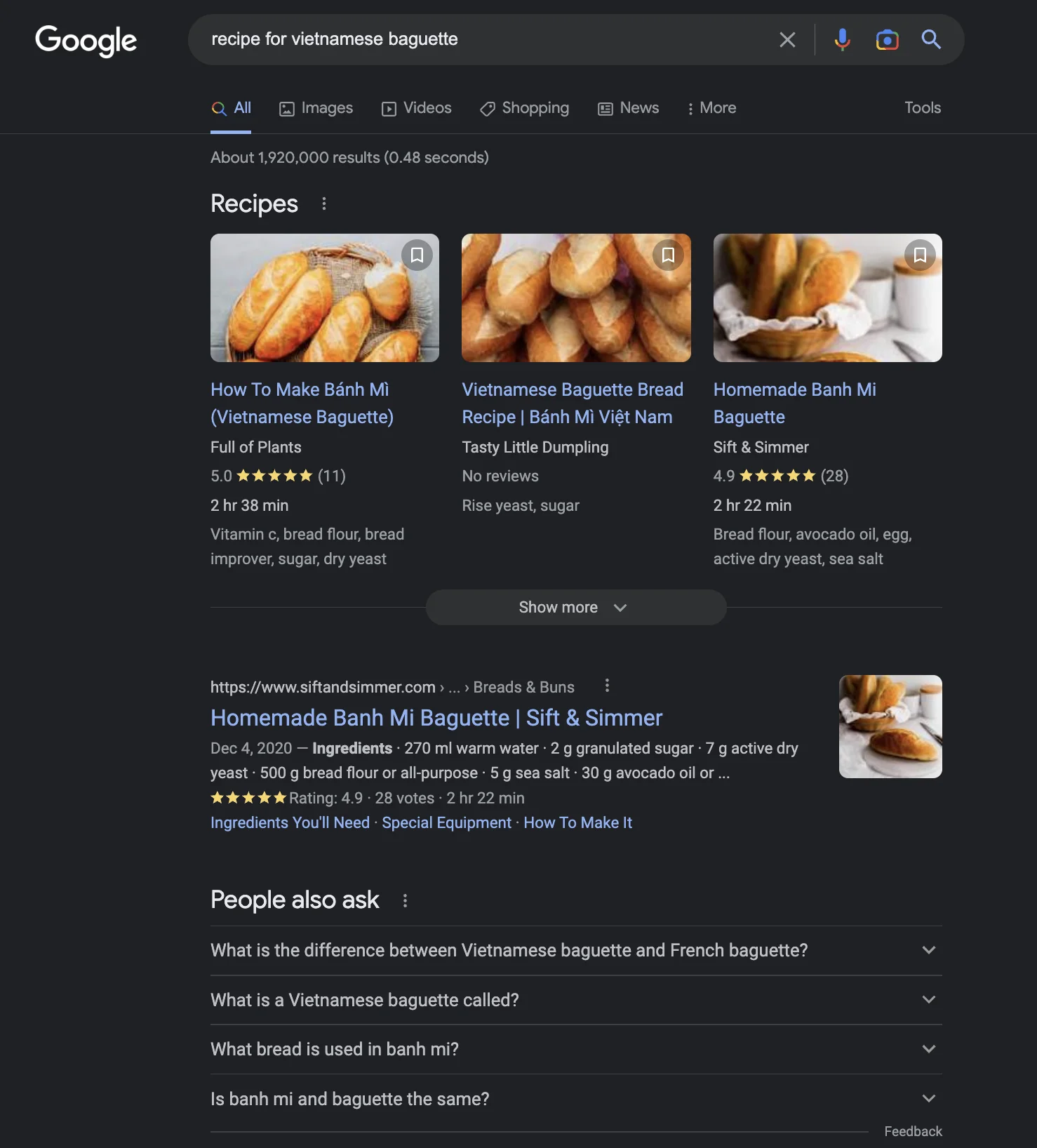
Ang susi ay ang dynamic na pagbabago ng search result interface batay sa user intent, gamit ang machine learning. Hindi ko sigurado kung gaano ito kadali o kahirap gawin. Pero mukhang logical na hakbang ang pagsasama ng lakas ng single answer style mula sa ChatGPT at isang Search engine.
Isang language assistant
I-argue ko na ang pagbibigay ng mga sagot mula sa pure information search perspective ay hindi ang dahilan kung bakit gusto ng mga tao ang ChatGPT, ito ay ang kakayahang bigyan ng context ang chatGPT at pagkatapos ay hilingin itong kumpletuhin ang isang language-related task tulad ng pagsulat ng tula, pagpapakilala, essay, atbp...
Ang use case na ito ay ibang-iba mula sa search engine at mas malapit na kaugnay sa kakayahang mag-generate ng PowerPoint narratives o magsulat sa Microsoft Word. Kaya sa totoo lang, sa tingin ko mas magandang balita ang tungkol sa Microsoft na nagsasama ng iba't ibang OpenAI capabilities sa Office 365 suite.
Ang mga limitasyon ng wika
Nagsulat si Jacob Browning at Yann Lecun ng isang mahusay na artikulo tungkol sa AI and the limits of language noong Aug 2022, bago pa man ibinukas ang ChatGPT sa publiko. Kahit na ang artikulo nila ay tumutukoy sa LaMDA, ang nilalaman ay esensyal na applicable sa chatGPT din o anumang ibang Large language model. Mahaba ang artikulo kaya kung gusto mo ang mga key points, narito sila:
Isang Google engineer ang nagdeklara kamakailan na ang AI chatbot ng Google, ang LaMDA, ay isang tao, na humantong sa iba't ibang reaksyon. Ang chatbot, LaMDA, ay isang large language model (LLM) na idinisenyo upang mahulaan ang mga malamang na susunod na salita sa anumang linya ng teksto na ibinibigay dito.
Ang ilang tao ay nangutya sa ideya, habang ang iba ay nagmungkahi na ang susunod na AI ay maaaring maging isang tao. Ang iba-ibang reaksyon ay nagha-highlight ng mas malalim na problema: habang ang mga LLM na ito ay nagiging mas karaniwan at malakas, mas kaunti ang kasunduan sa kung paano sila uunawain. Ang pinakailalim na problema ay ang limitadong katangian ng wika. Malinaw na ang mga sistemang ito ay nakatakdang magkaroon ng mababaw na pag-unawa na hindi kailanman magiging katulad ng buong-katawan na pag-iisip na nakikita natin sa mga tao. Ito ay dahil ang wika ay isang specific, limitadong uri ng knowledge representation lamang. Ito ay mahusay sa pagpapahayag ng discrete objects at properties at ng mga relasyon sa pagitan nila, pero nahihirapan sa pagrepresenta ng mas concrete na impormasyon, tulad ng paglalarawan ng irregular shapes o ang paggalaw ng mga bagay. May iba pang mga representational schemes, tulad ng iconic knowledge at distributed knowledge, na kayang ipahayag ang impormasyong ito sa accessible na paraan.
Ang wika ay isang low-bandwidth na paraan para sa pagpapadala ng impormasyon, at madalas ambiguous dahil sa homonyms at pronouns. Hindi kailangan ng mga tao ng perpektong sasakyan para sa komunikasyon dahil nagba-bahagi tayo ng nonlinguistic na pag-unawa. Ang mga Large Language models (LLMs) ay sinanay na kunin ang background knowledge para sa bawat pangungusap, tinitingnan ang mga nakapalibot na salita at pangungusap para buuin kung ano ang nangyayari. Ang mga LLM ay nakakuha ng mababaw na pag-unawa ng wika, pero limitado ang pag-unawang ito at hindi kasama ang know-how para sa mas kumplikadong mga pag-uusap. Bilang resulta, madali silang malinlang sa pamamagitan ng pagiging inconsistent o pagpapalit ng mga wika. Kulang ang mga LLM sa pag-unawang kinakailangan para sa pagbuo ng coherent view ng mundo.
Kahit na maraming impormasyon ang maipapadala ng wika sa maliit na format, karamihan ng kaalaman ng tao ay nonlinguistic at maaaring iparating sa pamamagitan ng ibang paraan tulad ng mga diagram, mapa, artifact, at social customs. Ito ay nagmumungkahi na ang isang makina na sinanay sa wika lamang ay hindi makakapag-approximate nang buo sa human intelligence dahil may access lang ito sa maliit na bahagi ng kaalaman ng tao sa pamamagitan ng makitid na bottleneck at na ang malalim na nonlinguistic na pag-unawa ng mundo ay kinakailangan para maging kapaki-pakinabang ang wika. Ito rin ay nagpapahiwatig na may mga limitasyon sa kung gaano katalino ang mga makina kung sinanay lamang sa wika.
Iyon lang mula sa akin. Ano sa tingin mo? Nakikita mo ba ang sarili mo na lumipat mula sa Google sa ChatGPT-powered Bing, o pinapanatili ka ba ng ugali sa Google? :)
Maraming salamat,
Chandler