Mga Reaksyon sa "Bing AI Can't Be Trusted"
Na-fact-check ko ang mga claim ng fact-checker tungkol sa Bing AI na gumawa ng maling financial data—lumabas na totoo ang problema ng made-up numbers at mas malala pa kaysa sa inaasahan ko.
Ang post na ito ay isinulat noong 2023. Maaaring may mga detalyeng nagbago na mula noon.
Nakita ko ang artikulong ito ngayon na Bing AI can't be trusted, at siyempre, naging interesado agad ako. Magandang artikulo ito na puno ng fact checks para ipakita na ang bagong Bing chat ay may maraming gawa-gawang facts tungkol sa factual na impormasyon. Medyo maikli ang post, kaya sige at basahin mo.
Kaya narito ang ilang mabilis na reaksyon mula sa akin:
Nagulat at hindi nagulat nang sabay
Generally aware ako sa mga limitasyon ng large language model (LLM) kung saan isa ang chatGPT. Ang tatlong pangunahing limitasyon ay:
- Hindi nito ini-index ang web na lampas sa text data (tulad ng video, audio, images, atbp...)
- Sobrang luma na ng data set ng chatGPT (2021)
- Gumagawa ng mga salita ang mga models na ito dahil hindi nila alam kung aling information source ang mas authoritative/trustworthy kaysa sa iba.
Kaya umaasa ako na sa Bing & OpenAI integration, masosolusyunan ng Bing search machine ang lahat ng limitasyon sa itaas. Eh, mukhang base sa artikulo ni Dmitri, hindi pa ito nasolusyunan ng Bing. Ni hindi man lang malapit.
I-fact-check ulit ang artikulo
Hindi maganda kung mali rin pala ang mga binanggit ni Dmitri. Kaya nag-fact-check din ako nang sarili ko. Nagsimula ako sa Gap financial statements dahil mukhang pinaka-straightforward na i-check. Kasama ko ang sources at screenshots sa ibaba para hindi mo na kailangang ulitin ang exercise na ito:
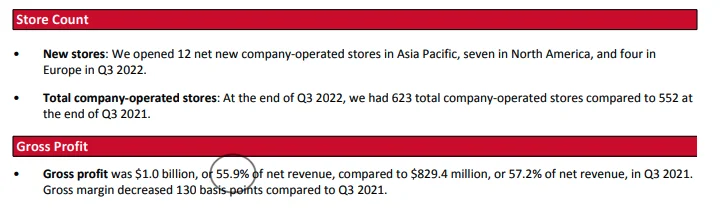
- Ito ang Gap Q3 2022 earning release.
- Kinuha ko ang screenshot sa ibaba mula sa Gap statement at ni-highlight ang key numbers sa pula. Tama si Dmitri, gumawa ng mga numero ang Bing chat tulad ng adjusted gross margin, operating margin, atbp...

Paano naman ang mga numero ng Lululemon?
- Ito ang Q3 2022 financial report ng Lululemon. Pareho lang, ni-highlight ko ang key numbers na binanggit sa artikulo ni Dmitri sa mga screenshot sa ibaba. Tama siya, gumawa ng mga numero ang Bing search.

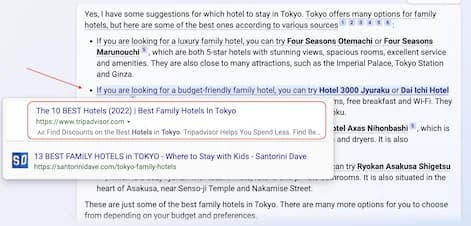
Para naman sa Mexico City itinerary, hindi ako expert sa topic na ito, kaya hindi ko maingat na ma-fact-check. Halimbawa, nang mag-search ako ng "Primer Nivel Night Club - Antro", nakita ko ang Facebook page na ito. Pero wala akong paraan para ma-verify sa 100% na katiyakan kung valid o hindi ang mga suggestions mula sa Bing Search.
Saan tayo pwedeng pumunta mula dito?
Mukhang malinaw na sa puntong ito ng oras, ang Bing & OpenAI integration ay hindi pa nagawa na i-fix ang isyu ng mga large language models (LLMs) na gumagawa lang ng mga bagay habang nagpapatuloy.
Hindi ako sapat na technical para intindihin kung gaano kahirap solusyunan ang isyung ito. Kung ganito na ang pagkaka-inaccurate nito sa factual data, kailangan nating mag-ingat sa mas subjective na mga topic tulad ng best restaurants/plumbers/local services, personal finance, health, relationship, atbp.
Ngayon para maging fair sa Bing at OpenAI, sinabi nila sa presentation na alam nila na ang bagong technology ay pwedeng magkamali sa maraming bagay, kaya dini-design nila ang "thumb up/thumb down" interface para mas madaling makapagbigay ng feedback ang mga users sa kanila. Sana, sa mas maraming user feedback, gaganda ang machine.
Isang algorithm para i-fact-check ang LLM output?
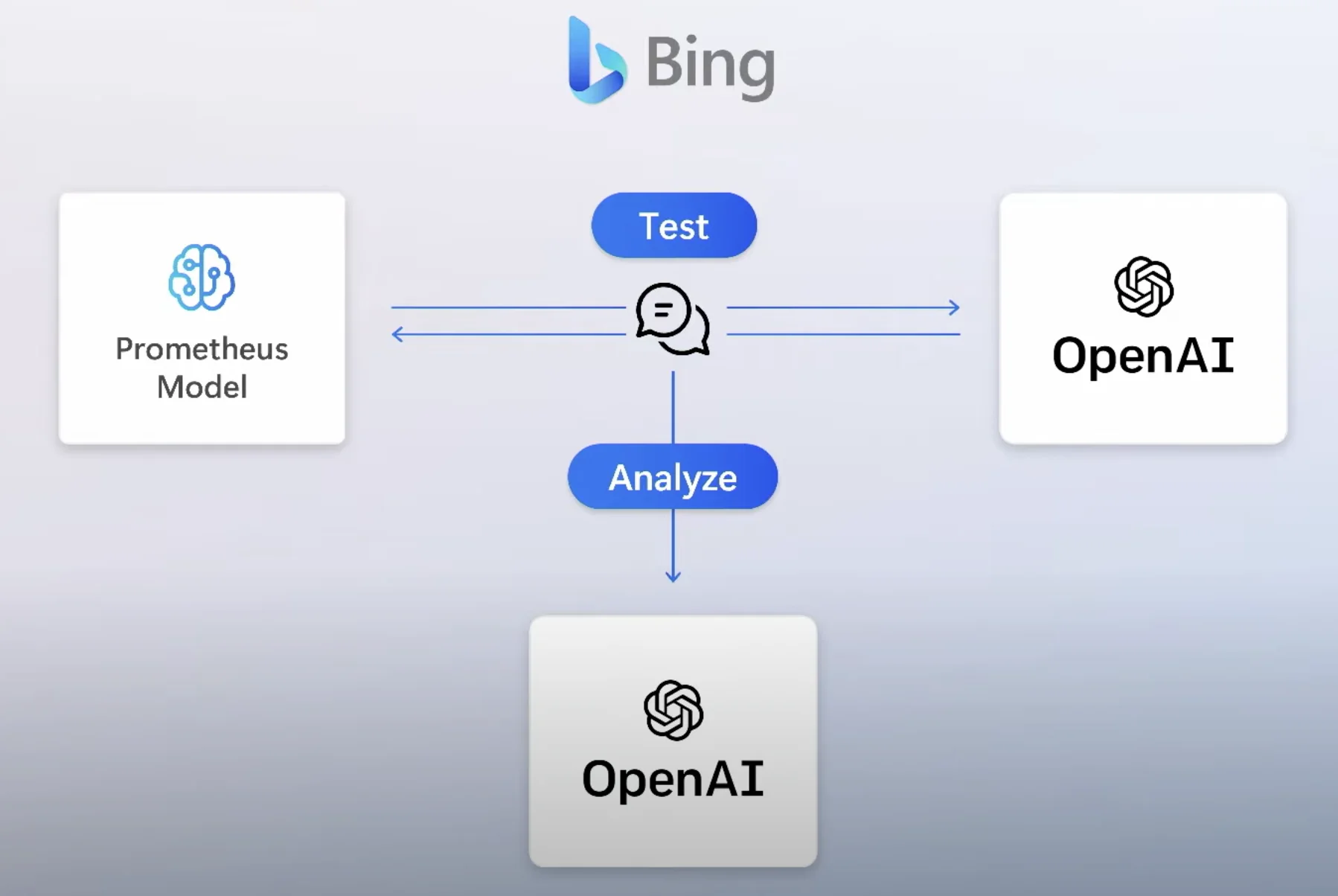
Dahil madalas gumagawa ng maling output ang LLM, paano kung gumawa ng isang algorithm para patuloy na i-fact-check ang output? Katulad ito ng sinabi ng Microsoft tungkol sa safety algorithm na ginawa nila sa Prometheus, na nagsi-simulate ng bad actors' prompts sa machine.
Ang papel ng tao
Mukhang nasa early stage pa ang technology na ito, at habang exponential ang progreso, kritikal ang papel ng tao. Hindi pa natin pwedeng pagkatiwalaan ang output, kahit na may Bing & OpenAI integration. Pwedeng matulungan tayo ng machine sa 50% ng desired outcome (higit o kumulang), pero kailangan nating ilagay ang isa pang 50%.
Mukhang sapat pa ang oras para tayo ay mag-adjust, matuto ng lakas at limitasyon ng technology na ito, at gamitin ito nang epektibo.
Para naman sa mga engineers, na nagdi-design ng mga system na ito, marahil kailangan ninyong gumawa ng mas magandang trabaho sa pag-highlight sa mga end users ng mga data points at sentences na hindi sigurado ang machine. Ang ating mga human brains ay mahilig sa shortcuts kaya sigurado ako na marami sa atin (kasama ako) ang kukuha ng tamad na ruta at tatanggapin ang sinasabi ng machine bilang totoo :P Mahirap para sa atin na nasa guard lagi 100% ng oras.
Nakahuli ka na ba ng anumang AI-generated answers na confident na mali? Gusto kong marinig ang iyong mga halimbawa — mas specific, mas maganda.
Maraming salamat,
Chandler