Codex at GPT-5.4 vs Claude Code at Opus 4.6 — Bakit Pareho Ko Na Silang Ginagamit
Matapos gumamit ng Claude Code at Opus 4.6 araw-araw sa loob ng halos isang taon, gumugol ako ng isang linggo kasama ang Codex at GPT-5.4. Ang hatol: walang tool na tahasang panalo. Mas maganda ang kombinasyon ng cross-model review, mga lakas na nagtutulungan, at operational resilience kaysa sa paggamit ng isa lang.
Matapos gumamit ng Claude Code araw-araw sa loob ng halos isang taon, gumugol ako ng isang linggo kasama ang Codex at GPT-5.4. Walang tool na tahasang panalo — pero kapag pinagsabay mo silang gamitin at pinaparebyu ang gawa ng isa sa kabila, mas maganda ang resulta kaysa sa paggamit ng isa lang. Ito ang nakita ko, bilang isang taong nakapag-ship na ng totoong produkto gamit ang pareho.
Ginamit ko ang Claude Code at Opus 4.6 bilang pangunahing development tool ko para sa halos lahat: ang pag-rebuild ng site na ito, ang paglabas ng DIALØGUE sa App Store, ang pagbuo ng STRAŦUM, ang pag-translate ng 3.9 milyong salita sa 12 wika, at ang paggawa ng buong course video pipeline na may 18 uri ng layout at word-level audio sync.
Kaya noong inilunsad ng OpenAI ang Codex na may GPT-5.4 noong March 5, hindi ako naghahanap ng kapalit. Naging mausisa lang talaga ako. May free month promo rin noon ang OpenAI, kaya madaling sumubok nang hindi muna kailangang mag-commit nang todo.
Nagulat ako sa magandang paraan. Sa totoo lang, higit pa sa nagulat — genuinely capable ang Codex at GPT-5.4 sa mga paraang hindi ko inaasahan.
Pagkalipas ng isang linggo, hindi ako lilipat nang tuluyan. Dual-wield na ako. At sa tingin ko, mas maganda ang kombinasyon kaysa sa alinman sa dalawang tool na mag-isa.
Bakit Mahalaga ang Pagkakaiba ng Harness at Modelo?
Bago ako pumunta sa mga detalye, may isang nuance na pakiramdam ko ay nami-miss ng karamihan sa mga paghahambing.
Harness ang Claude Code at Codex — ibig sabihin, sila ang CLI tools, ang agent orchestration, ang plugin ecosystems, ang context management, at ang paraan ng pakikipag-ugnayan nila sa filesystem at terminal mo. Ang Opus 4.6 at GPT-5.4 naman ang mga modelong nasa ilalim nito — sila ang intelligence na talagang nagpapasya kung ano ang gagawin, paano iisipin ang problema, at anong code ang isusulat.
Mahalaga ito dahil ang ilan sa mga obserbasyon ko ay tungkol sa harness, at ang ilan ay tungkol sa modelo. Ang automatic QA dispatch at parallel agent management ng Claude Code? Harness iyon. Ang architectural insight ng GPT-5.4 sa fragment sync problem ko? Modelo iyon. Kapag sinasabi kong mas gumaganda ang plan sa cross-model review, ang tinutukoy ko ay ang magkaibang paraan ng pagre-reason ng mga model — hatid lang ng harness ang output.
Ang mas mahusay na model sa mas mahina na harness ay puwedeng maging frustrating pa rin. Ang mahusay na harness na may mas mahinang model ay puwedeng mukhang polished pero mababaw. Sa ngayon, malakas pareho ang dalawang kombinasyon — magkaiba lang ng lakas.
Ano ang Unang Impresyon Ko sa Codex at GPT-5.4?
Aaminin ko — inasahan kong parang step down ang Codex. Malalim na kasi ang pinasok ko sa ecosystem ng Claude Code: ang Superpowers plugin para sa structured planning, ang parallel agent dispatching, ang code review agents na kusang tumatakbo pagkatapos ng implementation. Mature na workflow iyon.
Competitive agad ang Codex with GPT-5.4. Malakas ang model. Solid ang reasoning. Marunong itong sumunod sa plan. Kapag binigyan ko ito ng maayos na implementation plan, kaya nitong magtrabaho nang tuloy-tuloy sa loob ng mahigit 45 minuto nang hindi nawawala sa daloy — commit, test, push, tapos lipat sa susunod na task.
Nag-enable rin ako ng ilang experimental features ng Codex nang maaga:
- Multi-agents — parallel task execution, kahawig ng agent dispatching ng Claude Code
- JavaScript REPL — persistent na Node-backed runtime para sa inline debugging
- Prevent sleep while running — para manatiling gising ang makina sa mahahabang session
Malinaw ang naging epekto ng mga iyon. Lalo na ang multi-agent support, na nagparamdam sa akin na humahabol ang Codex sa workflow na nasanay akong asahan sa Claude Code.
Saan Lumamang ang GPT-5.4 sa Opus 4.6?
Kailangan kong aminin — may isang area kung saan malinaw na lamang ang GPT-5.4 sa Opus 4.6, at hindi ito maliit na bagay.
Gumagawa ako ng course video pipeline na nagsi-sync ng slide fragments sa narrated audio. Hindi timing ang pinakamahirap na problema — nagbibigay na ang ElevenLabs ng word-level timestamps. Ang tunay na mahirap ay alignment: pagdedesisyon kung aling fragment sa screen ang dapat lumabas kapag nagsimulang banggitin iyon ng speaker.
Madalas hindi inuulit nang verbatim ng speaker notes ang text sa slide. Minsan paraphrase lang ng isang bullet. Minsan pinagsasama ang dalawang bullet sa iisang ideya. Minsan may bullet sa slide na halos hindi naman talaga nasasabi. Kaya hulaan nang hulaan ang system gamit ang keywords. Gumagana ito nang sapat para magmukhang promising, pero bumibigay sa mahihirap na slide.
Nahihirapan dito ang Opus 4.6 sa medium thinking sa loob ng ilang session. Paulit-ulit itong gumagawa ng mas matatalinong heuristic — equal splits ayon sa haba ng text, keyword search sa timestamps, sentence-level matching, dual-strategy matching — mas maganda nang kaunti sa bawat ikot, pero may parehong pundamental na limitasyon.
Natukoy ng GPT-5.4 sa high thinking ang architectural issue: hindi ito dapat tratuhin bilang keyword-matching problem. Data model problem ito. Dapat mag-emit ang renderer ng totoong fragment states, dapat i-align ng assembler ang narration sa mga state na iyon, at dapat mag-flag ang validation ng mga slide kung hindi tugma ang visual structure at narration.
Tama ang insight na iyon. Ang paglipat mula sa "hulaan ang sync mula sa text" tungo sa "gawing explicit at first-class na bahagi ng pipeline ang sync" ang eksaktong architectural reframe na kailangan ng problemang ito. At mas mabilis doon nakarating ang GPT-5.4 kaysa sa Opus.
Saan Pa Rin Lamang ang Claude Code?
Pero heto ang mahalagang punto — magkaiba ang architectural insight at execution quality hanggang dulo.
Kalidad ng Pagpapatupad
Pinakamalinaw na halimbawa: pinasuri ko sa parehong tool ang companion notes sa pitong course modules at pinasubukang pagandahin ang mga iyon. Bumalik ang Codex at sinabing tapos na ang trabaho.
Bumalik ang Claude Code na may ganito:
Audit Complete — All 7 Modules
Tier 1: Ayusin ang 15 existing thin companion notes (itaas sa standard — quick win)
Tier 2: Magdagdag ng companion notes sa humigit-kumulang 25-30 high-priority slides (core frameworks, tool lists, multi-step processes, dense stats)
Hindi iyon simpleng "tapos na." Structured gap analysis iyon na tumukoy sa 40-45 slide na kailangan ng pansin at inayos pa ayon sa priority tiers. Malaki ang diperensya sa pagitan ng "natapos ko ang task" at "natapos ko ang task at ito ang mga nakita ko" kapag totoong produkto ang sini-ship mo.
Awtomatikong QA
Ito ang killer feature ng Claude Code, at sa tingin ko kulang pa ang usapan tungkol dito. Pagkatapos mag-complete ng isang implementation chunk, kusang nagdi-dispatch ang Claude Code ng QA agents — code review, narrative review, consistency checks — nang hindi ko na kailangang sabihan.
Hindi pa iyon ginagawa ng Codex. Kapag sinabi ng Codex na tapos na siya, ikaw pa rin ang magva-verify o magse-set up ng sarili mong review process. Sa Claude Code, bahagi na iyon ng workflow. Brilliant talaga.
Pamamahala ng Sabayang Agent
Mas mature ang agent orchestration ng Claude Code. Nagdi-dispatch ito ng maraming specialized agents, kino-coordinate ang resulta nila, sinisintesis ang findings, at ibinabalik sa iyo bilang isang coherent na summary. Nagkaroon na ako ng sessions na may 5-6 agents na sabay-sabay tumatakbo — explorer, code reviewer, implementation agent, test runner — lahat coordinated.
Promising ang multi-agent support ng Codex, pero mas maaga pa ito sa development nito. Gumagana naman, pero hindi pa ganoon ka-seamless ang coordination.
Pagkakapare-pareho
Sa mahahabang sessions na maraming moving parts — gaya ng paggawa ng slides para sa 7 modules na may 18 layout types — mas mahusay mapanatili ng Claude Code ang consistency. Tama pa rin ang design tokens. Nanatili ang naming conventions. At ang architectural decisions na ginawa sa unang oras ay nirerespeto pa rin sa ikaapat na oras.
Puwede Bang Ilipat ang Workflow Mula sa Isang Tool Papunta sa Isa?
May isang workflow na hindi ko inaasahan: ang paggamit ng Codex para pag-aralan ang plugin ecosystem ng Claude Code at i-adapt iyon.
Gusto ko lalo na ang ilang Claude Code plugins: ang feature development workflow (/feature-dev), ang code review system (/code-review), ang code simplifier (/code-simplifier), ang Superpowers planning framework (/superpowers), at ang frontend design skill (/frontend-design). Well-designed na workflows ang mga iyon na nag-e-encode ng best practices sa mismong tool.
Kaya pinasuri ko ang mga iyon sa Codex at pinagawa ko ito ng mga katumbas na Codex skills:
"Nagsusulat ako ng user-level Codex skills sa
~/.codex/skills, gamit ang Claude plugin workflows bilang template at ina-adapt ang mga iyon sa skill model ng Codex kung saan wala ang mga Claude-only feature tulad ng hooks o plugin commands."
Gumana ito. Hindi perpekto — may ilang Claude Code concepts na walang direktang equivalent sa Codex — pero mahusay na naisalin ang core workflows. Ngayon, may structured development processes na ako sa parehong tool, galing sa iisang design philosophy.
Ano ang Nangyayari Kapag Pinapa-review Mo Sila sa Isa't Isa?
Ito ang tingin kong pinakamahalagang natuklasan ko nitong linggo.
Kapag pinare-review mo sa Opus 4.6 ang isang plan mula sa GPT-5.4, at pagkatapos ay pinare-review mo naman sa GPT-5.4 ang revised plan mula sa Opus — paulit-ulit sa loob ng ilang rounds — mas maganda nang husto ang resulta kaysa sa paggamit ng isa lang.
Magkaiba ang nahuhuli nilang kahinaan. Madalas makita ng Opus ang architectural inconsistencies at edge cases sa error handling. Madalas namang makita ng GPT-5.4 ang over-engineering at magsuggest ng mas simpleng approach. Binabalanse nila ang blind spots ng isa't isa.
Ginagawa ko na ito ngayon sa bawat implementation plan na hindi trivial: draft sa isang tool, review sa kabila, revise, review ulit. Dalawa o tatlong rounds. Mas masikip ang final plan, mas matibay, at mas maraming issue ang nahuhuli kaysa kapag isang model lang ang ginamit.
Kung iisang AI coding tool lang ang gamit mo, sa tingin ko may quality kang iniiwan sa mesa. Hindi dahil may masama sa alinman sa dalawa — parehong genuinely excellent — kundi dahil magkaiba silang mag-isip, at magkaibang pag-iisip ang nakakahuli ng magkaibang problema.
Ano ang Mangyayari Kapag Nag-down ang Isa sa Mga Tool?
Noong March 11, nakaranas ang Claude Code ng elevated errors — may login issues, mabagal ang performance, at may mga intermittent failures. Sa loob ng ilang oras, halos hindi ito magamit.
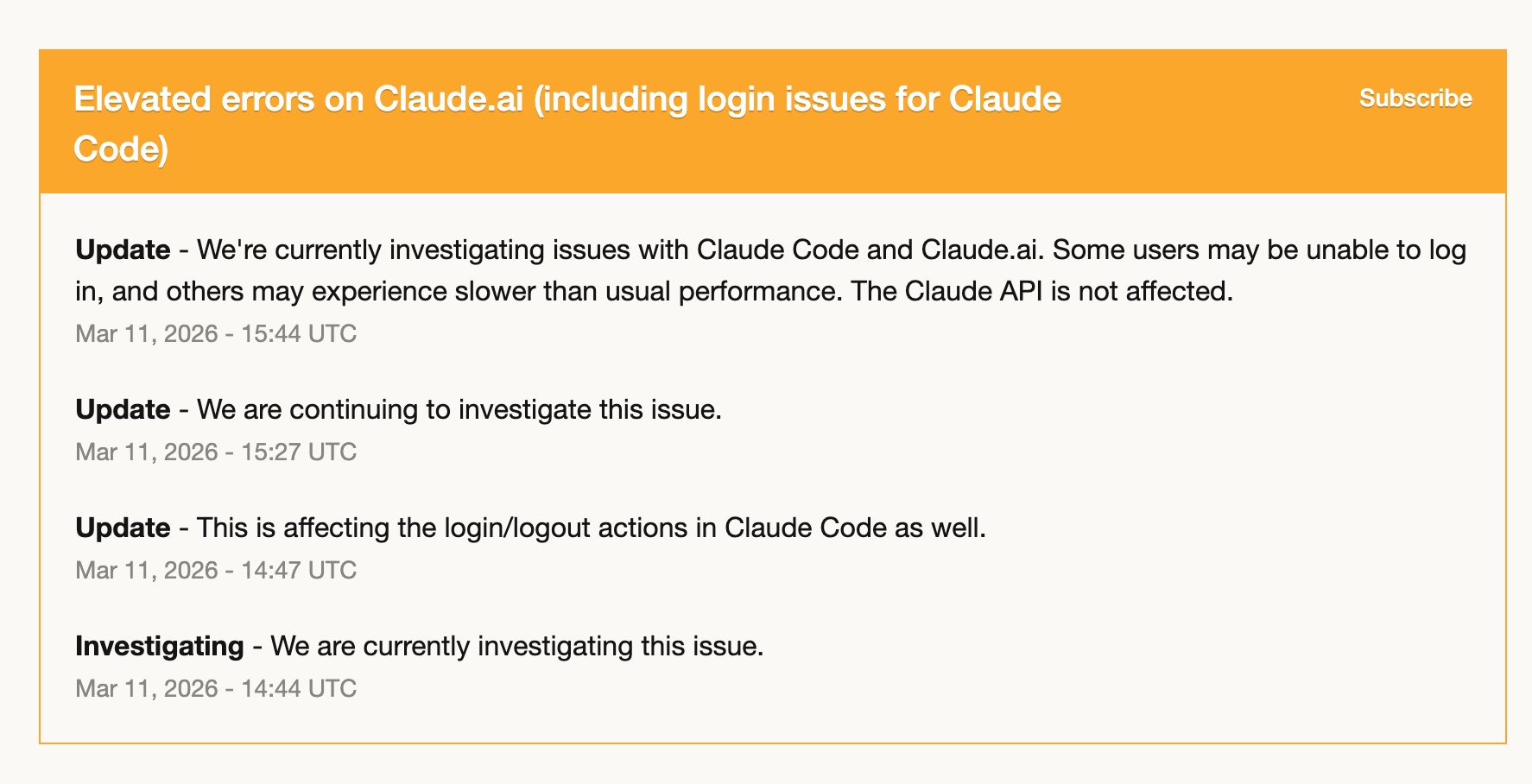
Dahil nagsisimula na akong mag-ramp up sa Codex bago pa iyon, halos doon ako tuluyang lumipat pansamantala. At okay lang ako. Naka-set up na ang Codex skills ko, naisalin ko na ang workflows ko, at maayos na nahawakan ng GPT-5.4 ang trabaho.
May isang bagay na luminaw dahil doon: may risk ang umasa nang buo sa iisang tool. Hindi dahil unreliable ang tool — sa totoo lang, kahanga-hanga ang stability ng Claude Code sa loob ng taon na ginamit ko ito — kundi dahil kahit anong service ay puwedeng magkaroon ng masamang araw. Ang pagkakaroon ng pangalawang tool na totoong komportable kang gamitin ay hindi luho. Operational resilience iyon.
Magkatabi: Claude Code vs. Codex
| Aspeto | Claude Code (Opus 4.6) | Codex (GPT-5.4) |
|---|---|---|
| Kalidad ng pagpapatupad | Mas malalim — nakakahuli ng gaps at marunong mag-prioritize | Maganda — natatapos ang tasks, pero hindi gaanong proactive sa analysis |
| Awtomatikong QA | Built-in, kusang nagdi-dispatch ng review agents | Wala pa — manual verification ang kailangan |
| Sabayang agents | Mature — 5-6 coordinated agents | Promising — gumagana pero hindi pa kasing seamless |
| Architectural reasoning | Malakas sa medium thinking | Napakalakas sa high thinking — mas mabilis mag-reframe |
| Sustained plan execution | Maganda | Kahanga-hanga — 46+ minuto na tuloy-tuloy |
| Context compaction | Mas mabagal | Mas mabilis — iba, hindi pa siguradong mas maganda |
| Localization at scale | Ka-level (Opus 4.6 medium) | Ka-level — sa ngayon mas mura |
| Plugin/skill ecosystem | Mature (Superpowers, /feature-dev, atbp.) | Lumalaki pa — puwedeng i-adapt ang Claude workflows |
| Cross-model review | Nakakahuli ng edge cases at inconsistencies | Nakakahuli ng over-engineering at nagsi-simplify |
| Gastos | $100-200/buwan | Free month promo, pagkatapos TBD |
Ilan Pang Obserbasyon
Context management: Mukhang mas mabilis mag-compact ng context ang Codex kapag napupuno na ang context window. Hindi ko pa masasabi kung mas mabuti iyon o hindi — malinaw lang na iba ito sa paraan ng paghawak ng Claude Code.
Localization at scale: Nag-translate ako ng 3.9 milyong salita sa 12 wika gamit ang Claude Code with Opus 4.6. Ka-level ng translation quality ng Opus 4.6 medium thinking ang GPT-5.4 — at sa ngayon, mas mura para sa akin kapag scale ang usapan. Kaya unti-unti kong inililipat ang bulk localization work ko sa GPT-5.4. Hindi ko alam kung gaano katagal tatagal ang cost advantage na iyon, pero habang nandiyan, makatuwirang gamitin.
Gastos: Nasa $200/month Max plan ako ng Claude Code. Dahil meaningful na bahagi ng workload ko ang hinahawakan ngayon ng Codex — lalo na ang localization — iniisip kong bumaba sa $100 tier. Nakakatulong ang free month ng OpenAI sa transition, pero kahit sa full price, posibleng mas cost-effective pa rin ang paghahati ng trabaho sa dalawang tool kaysa i-max out ang isa lang.
Dito Ako Nauwi
Pagkatapos ng isang linggo ng totoong dual-wielding, ito ang working model ko:
Abutin ang Claude Code kapag: kailangan mo ng matibay na execution quality na may built-in QA, kumplikadong multi-agent orchestration, long-form consistency sa malalaking codebase, o nasa project ka na naka-set up na ang Superpowers workflow.
Abutin ang Codex kapag: kailangan mo ng fresh architectural perspective, gusto mo ng high-thinking mode para sa isang mahirap na reasoning problem, may well-defined plan kang kailangang itulak nang tuloy-tuloy, o may masamang araw ang Claude Code.
Gamitin ang dalawa para sa: anumang implementation plan na hindi trivial. Mag-draft sa isa, magpa-review sa kabila. Ang cross-model review loop ang pinakamagandang workflow na nakita ko sa ngayon.
Hindi ko iniiwan ang Claude Code — ito pa rin ang primary tool ko at ang ecosystem na pinakamalalim kong alam. Pero hindi na rin ako single-tool developer. Nakuha ng GPT-5.4 ang lugar nito sa workflow ko dahil sa tunay na kakayahan, hindi lang bilang backup.
Ang hinaharap ng AI-assisted development ay hindi pagpili ng iisang panalo. Ang totoo ay alam mo kung kailan gagamitin ang alin, at — mas mahalaga — alam mo na mas mahusay ang mga tool na ito kapag magkasama kaysa magkahiwalay.
Madalas Itanong
Mas mahusay ba ang GPT-5.4 kaysa Opus 4.6 para sa coding?
Walang isa na talagang mas mahusay sa lahat. Ang GPT-5.4 sa high thinking ay malakas sa architectural reasoning at sustained plan execution. Ang Opus 4.6 ay malakas sa execution quality, proactive gap analysis, at consistency sa mahahabang session. Pinakamaganda ang resulta kapag pinapareview mo sa bawat isa ang trabaho ng kabila.
Dapat ba akong lumipat mula Claude Code papuntang Codex?
Hindi ko irerekomenda ang full switch. May kanya-kanyang lakas ang dalawa — tunay na nangunguna ang automatic QA at parallel agent orchestration ng Claude Code, habang impressive naman ang sustained execution ng Codex at ang reasoning ng GPT-5.4 sa mahihirap na problema. Mas makukuha mo ang pinakamaganda sa dalawa sa dual-wielding approach.
Sulit ba ang extra effort ng cross-model review workflow?
Para sa mga hindi trivial na plan, oo. Kapag pinareview mo sa Opus ang output ng GPT-5.4 at vice versa, magkaibang uri ng issues ang nahuhuli nila — edge cases at inconsistencies para kay Opus, over-engineering para kay GPT-5.4. Sa dalawa o tatlong rounds, kapansin-pansing mas mahigpit ang plan kaysa sa isa lang ang ginamit.
Magkano ang dual-tool setup?
Umaabot sa $100-200/buwan ang Claude Code depende sa plan. Nagbabago pa ang pricing ng Codex — may free month promo ngayon ang OpenAI. Kahit sa full price, posibleng mas tipid pa rin ang paghahati ng workload sa dalawang tool na nasa mas mababang tiers kaysa i-max out ang iisa lang.
Puwede bang gamitin ang Claude Code plugins sa Codex?
Hindi diretso, pero puwedeng i-adapt. Ginamit ko ang Codex para pag-aralan ang Claude Code plugin workflows (/feature-dev, /code-review, /superpowers) at isalin ang core logic ng mga iyon sa Codex skills sa ~/.codex/skills. May ilang Claude-specific features gaya ng hooks na hindi maisasalin, pero ang workflows mismo ay oo.
Hanggang dito na muna. Curious ako — may iba pa bang nagpapatakbo ng multi-model workflows? Pinagsasabay ang Claude Code at Codex, o ibang kombinasyon? Anong patterns ang nakikita ninyo?
Salamat, Chandler





