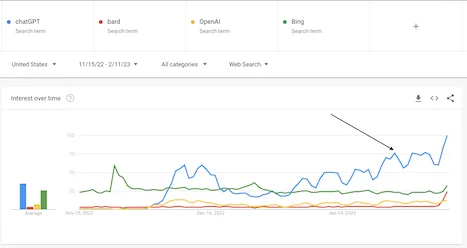
一台强大的机器,正通过 100+ 语言接入全人类公开知识
当 AI 通过 Bing 获得近实时、多语言、全网公开知识访问能力后,真正需要被认真讨论的已不只是技术表现,而是社会适应能力。
本文写于2023年,部分内容可能已发生变化。
昨天看完微软关于新 Bing的发布后,我脑中一直反复出现一个念头:
现在,一台强大的机器已经能够通过 100 多种语言访问全人类公开知识,并且借助 Bing 搜索接入实时或近实时的新信息。
过去 ChatGPT 在搜索场景的三大障碍——无法有效索引非文本内容、缺乏实时数据、难以判断来源权威性——在 Bing 集成后几乎都被补齐了(详细分析在这篇)。
微软负责 Responsible AI 的 Sarah Bird 在这个视频里介绍了他们如何降低系统被滥用的风险,示例包括“规划攻击”这类高风险对话。
之所以要做这些工作,是因为机器一旦接入全球知识,给出的答案会比更早版本(例如早期 ChatGPT)复杂和强大得多。
她提到微软开发了一套新的测试机制,用于提升 Bing 在潜在有害对话上的处理能力。
这套机制会使用“对话模拟器”与模型进行成千上万轮不同对话,再把结果用于识别系统缺口并持续修补,方法包括:
- 结合语言学家的规则和指南
- 与人工专家迭代
- 自动分类对话风险类型
由于这个流程可以重复到百万级甚至更高轮次,它在 Responsible AI 风险缓解与测试覆盖上带来了明显进展。
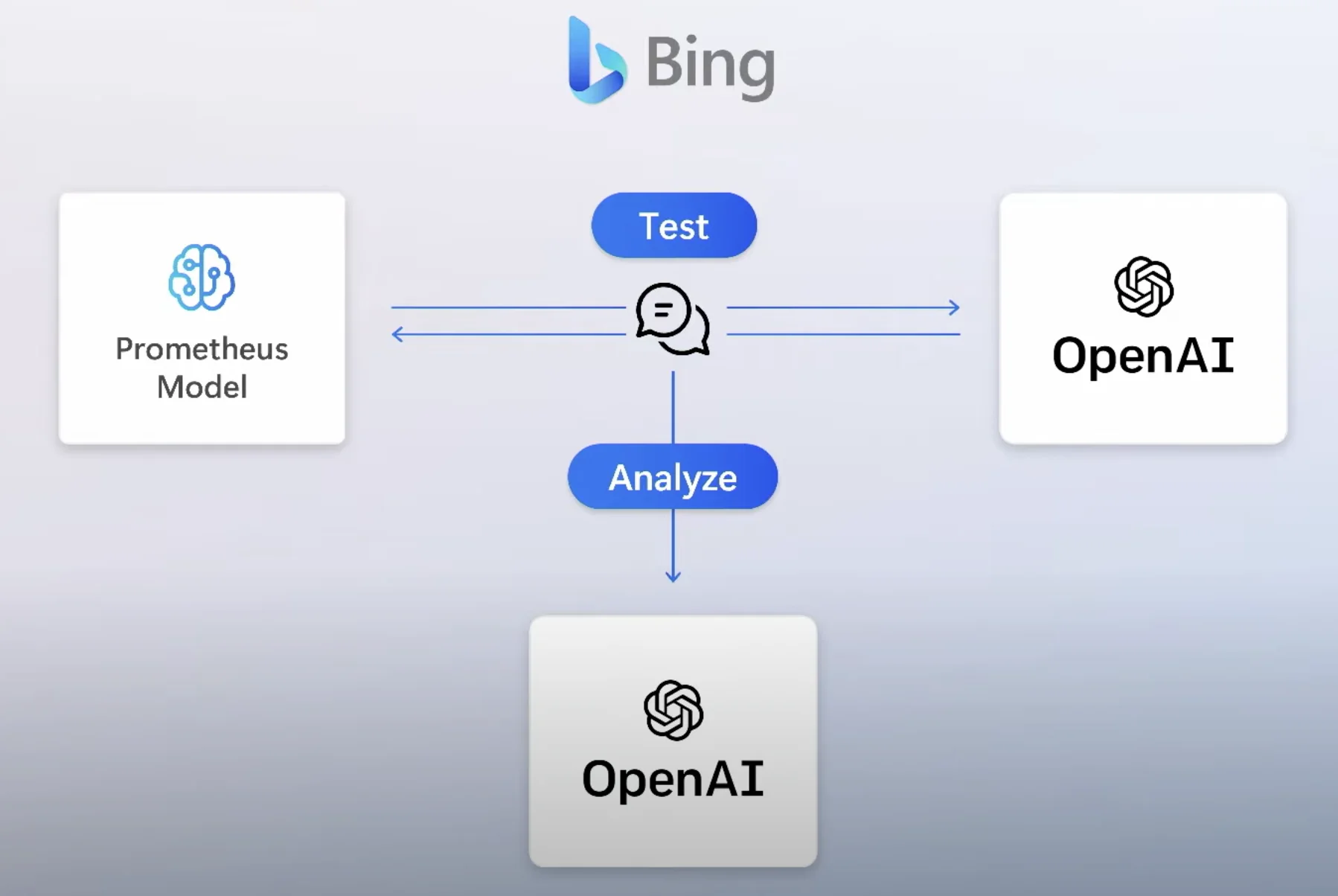
我认为 Bing 与 OpenAI 集成的影响会非常深远,而且很多效应尚未真正显现。
坦白说,这件事既让人兴奋,也让人有点不安。
考虑到机器学习的特性,系统会持续变得更聪明,而且速度很快(它不需要睡觉、休息、吃饭)。社会层面的影响可能很大,尤其对资源有限的发展中国家。
我在越南长大,所以会反复想这些问题:
- 有多少岗位会被替代?
- 有多少人需要再培训?
- 再培训资源从哪里来?
- 当事人是否愿意学习新技能?
比如,是否可以这样做:
- 微软推出系统化在线课程,教大众如何使用“Bing + OpenAI”。
- 我自己连续用了 ChatGPT、Bearly(以及其他 GPT-3 系应用)一段时间后,依然每天在学习如何把系统用得更好。
- 多轮提示词提供具体上下文非常关键。你给 AI 助手/Copilot 的上下文越完整,它执行任务越稳定。
- 比如我昨天才学到:在提示词末尾加一句“Do you understand me?”,让模型先复述它理解到的任务。
- 我几周前也学到:开场就先声明目标受众,会明显提升输出相关性。比如说明“回答对象是美国外派人士”。
- 然后利用机器把课程翻译成尽可能多语言。
- 把课程直接嵌入 Bing 界面里,降低学习门槛,让更多人可用。
我希望负责这项技术的人们有一套足够好的全球可及性计划,让不同国家都能参与、讨论、辩论,而不是只有少数地区受益。
我在这个议题上仍是学习者,也不假装自己有标准答案。但我认为,现在就开始认真思考这些问题,非常重要。
你怎么看?AI 会扩大还是缩小发达国家和发展中国家之间的差距?欢迎分享你的视角。
致敬,
Chandler