对《Bing AI 不能被信任》一文的几点回应
我复核了文中引用的财报案例,结果显示 Bing 确实会在“事实型问题”上编造数字。这意味着当前阶段人类校验仍不可替代。
本文写于2023年,部分内容可能已发生变化。
今天看到这篇文章:Bing AI can't be trusted。
它会吸引我点进去是很自然的。整篇结构清晰,核心是用事实核验(fact-check)证明:新 Bing Chat 在事实信息上仍会给出大量“编造内容”。篇幅不长,建议你直接读原文。
我这边补几条快速回应。
同时“意外”又“不意外”
我本来就知道大语言模型(LLM,ChatGPT 属于其中一种)有几个典型局限:
- 对非文本内容(视频、音频、图像等)索引能力不足
- 数据时效性问题(ChatGPT 当时数据停在 2021)
- 模型缺乏稳定的来源权威判断能力,容易生成看似流畅但并不真实的内容
我原本希望 Bing + OpenAI 集成后,Bing 的搜索能力能把这三点基本补齐。
但从 Dmitri 的文章看,至少在当前阶段,这些问题并没有真正解决,而且差距还不小。🙁
我又做了一轮复核
如果 Dmitri 自己也有事实错误,那会很尴尬。所以我又独立做了几组核对,先从最容易核验的 Gap 财报开始,并附上来源和截图,避免你重复劳动。
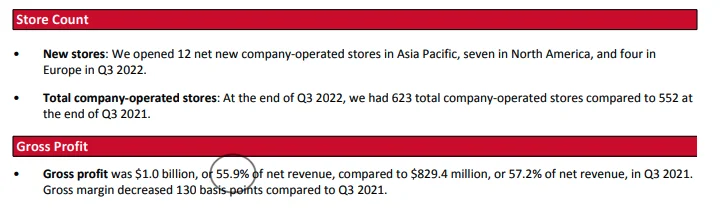
- Gap 2022 Q3 财报原文:这里
- 我在原文件里标了关键数字。结论是:Dmitri 在这点上是对的,Bing Chat 的确把 adjusted gross margin、operating margin 等数字编错了。

再看 Lululemon:
- 2022 Q3 财报:这里
- 我同样标了文中提到的关键数字。结论一致:Bing 在毛利率、营业利润率等数据上也有编造。

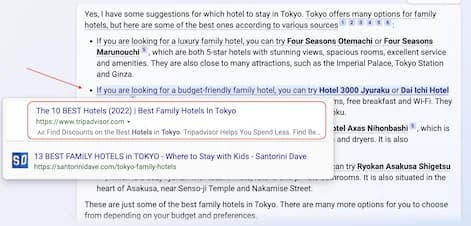
至于文中的 Mexico City 行程建议,我并非该领域专家,没法做同等强度核验。比如我搜索“Primer Nivel Night Club - Antro”时确实能找到这个 Facebook 页面,但我无法 100% 确认 Bing 的全部建议都可靠。
接下来怎么办?
目前看,Bing + OpenAI 还没真正解决 LLM “一本正经胡说”这个核心问题。
我不是技术专家,无法判断彻底解决这件事的工程难度有多高。但如果连财务这种“硬事实”都能错得这么离谱,那在更主观场景(餐厅推荐、本地服务、个人理财、健康、关系建议等)就更要谨慎。
公平一点说,Bing 与 OpenAI 在发布会里也承认新系统会犯错,所以才设计了 thumbs up / thumbs down 反馈机制,希望借大量用户反馈加速迭代。
能不能做“持续事实校验算法”?
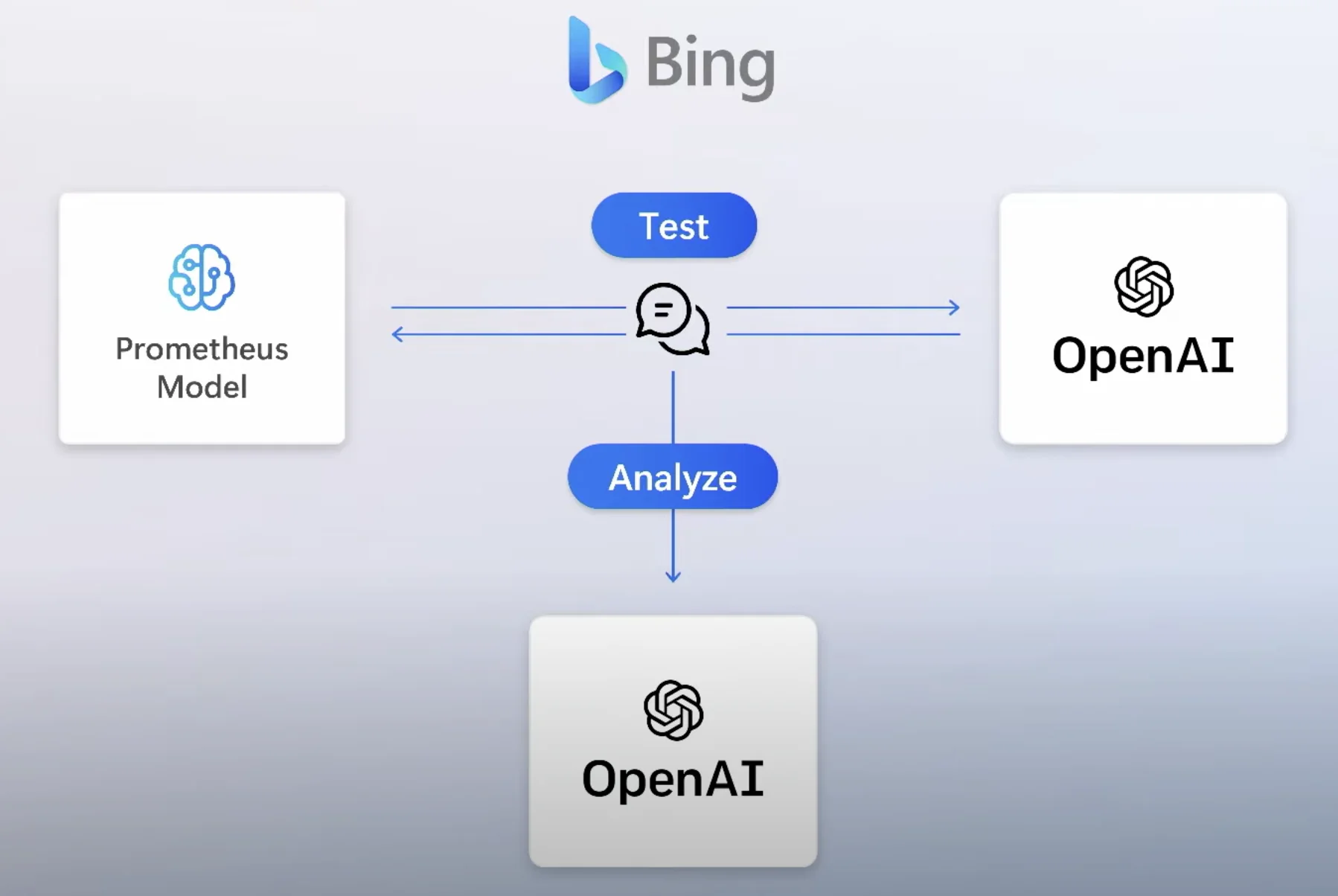
既然 LLM 输出会错,是否可以在输出链路里加入持续 fact-check 算法?
这个思路有点像微软在 Prometheus 安全体系里做的对抗模拟:用大量“坏案例”去压力测试模型。
人类角色短期内仍非常关键
这项技术仍在早期,虽然进步速度很快,但人类审核目前不可替代。
即便有 Bing + OpenAI 集成,我们现在也不能直接把输出当“真相”。机器也许能完成目标的前 50%,剩下的 50% 仍要靠我们验证和修正。
所以我会说:我们还有时间去调整方法、学习这类系统的优势与边界,再把它用到更靠谱。
对系统设计者来说,我也有一个请求:请更明确地标示模型“低置信度段落/数据点”。
人脑天生喜欢走捷径,很多人(包括我自己)会倾向于偷懒,把模型说的话直接当真。要让用户 100% 始终警觉,很难。
你有没有遇到过 AI 回答得非常自信但事实错误的案例?欢迎分享具体例子。
致敬,
Chandler