Codex mit GPT-5.4 vs. Claude Code mit Opus 4.6 — Warum ich jetzt beides nutze
Nachdem ich fast ein Jahr lang täglich Claude Code mit Opus 4.6 genutzt habe, habe ich eine Woche lang mit Codex und GPT-5.4 gearbeitet. Das Fazit: Keines der beiden Tools gewinnt klar. Die Kombination — Cross-Model-Review, komplementäre Stärken und operative Resilienz — ist besser als jedes Tool für sich.
Nachdem ich fast ein Jahr lang täglich Claude Code genutzt habe, habe ich eine Woche mit Codex und GPT-5.4 verbracht. Keines der beiden Tools gewinnt klar — aber beide zusammen, mit Cross-Model-Review, liefern bessere Ergebnisse als jedes Tool allein. Hier ist, was ich herausgefunden habe — aus Sicht von jemandem, der mit beiden echte Produkte ausgeliefert hat.
Ich habe Claude Code mit Opus 4.6 als mein primäres Entwicklungstool für fast alles genutzt: für den Neuaufbau dieser Website, für DIALØGUE im App Store, für STRAŦUM, für die Übersetzung von 3,9 Millionen Wörtern in 12 Sprachen und für eine komplette Kurs-Video-Pipeline mit 18 Layout-Typen und Wort-für-Wort-Audiosynchronisierung.
Als OpenAI also am 5. März GPT-5.4 mit Codex vorgestellt hat, habe ich nicht nach einem Ersatz gesucht. Ich war einfach neugierig. Dazu kam noch eine kostenlose Testphase von OpenAI, was den Einstieg ziemlich einfach machte.
Ich war positiv überrascht. Ehrlich gesagt: mehr als positiv überrascht. Codex mit GPT-5.4 war in Bereichen wirklich stark, in denen ich es nicht erwartet hatte.
Eine Woche später wechsle ich nicht. Ich nutze jetzt beides parallel. Und ich glaube, genau diese Kombination ist besser als jedes einzelne Tool für sich.
Warum ist die Unterscheidung zwischen Harness und Model wichtig?
Bevor ich ins Detail gehe, eine Nuance, die meiner Meinung nach in den meisten Vergleichen fehlt.
Claude Code und Codex sind Harnesses — also CLI-Tools, Agenten-Orchestrierung, Plugin-Ökosysteme, Kontextmanagement, die Art, wie sie mit Dateisystem und Terminal umgehen. Opus 4.6 und GPT-5.4 sind die zugrunde liegenden Models — also die Intelligenz, die entscheidet, was zu tun ist, wie über ein Problem nachgedacht wird und welcher Code entsteht.
Das ist wichtig, weil manche meiner Beobachtungen das Harness betreffen und andere das Model. Claude Codes automatische QA-Dispatches und paralleles Agentenmanagement? Das ist das Harness. GPT-5.4s architektonische Einsicht bei meinem Fragment-Sync-Problem? Das ist das Model. Wenn ich sage, dass Cross-Model-Review zu besseren Plänen führt, dann meine ich konkret, dass die Models unterschiedlich denken — das Harness liefert nur den Output aus.
Ein besseres Model in einem schwächeren Harness kann trotzdem frustrierend wirken. Ein starkes Harness mit einem schwächeren Model kann poliert wirken, aber oberflächlich bleiben. Im Moment sind beide Kombinationen stark — nur eben auf unterschiedliche Weise.
Wie hat sich Codex mit GPT-5.4 beim ersten Einsatz geschlagen?
Ich bin ehrlich: Ich hatte erwartet, dass sich Codex wie ein Schritt zurück anfühlen würde. Ich bin tief in Claude Codes Ökosystem drin: Superpowers für strukturiertes Planen, parallele Agenten, Code-Review-Agenten, die nach der Umsetzung automatisch loslaufen. Das ist ein reifer Workflow.
Codex mit GPT-5.4 fühlte sich sofort konkurrenzfähig an. Das Model ist stark. Das Denken ist solide. Es folgt Plänen gut. Wenn ich ihm einen sauberen Implementierungsplan gegeben habe, konnte es 45+ Minuten am Stück arbeiten, ohne den Faden zu verlieren — committen, testen, pushen und direkt mit dem nächsten Schritt weitermachen.
Ich habe früh ein paar experimentelle Funktionen von Codex aktiviert:
- Multi-agents — parallele Aufgabenausführung, ähnlich zu Claude Codes Agent-Dispatching
- JavaScript REPL — persistente Node-basierte Laufzeit für Inline-Debugging
- Prevent sleep while running — hält den Rechner bei langen Sessions wach
Das hat spürbar geholfen. Vor allem Multi-agent-Support fühlte sich an, als würde Codex bei einem Workflow aufholen, von dem ich inzwischen abhängig geworden bin.
Wo war GPT-5.4 besser als Opus 4.6?
Ich muss zugeben: Es gab einen Bereich, in dem GPT-5.4 Opus 4.6 klar geschlagen hat. Und das war kein kleines Detail.
Ich baue gerade eine Kurs-Video-Pipeline, die Slide-Fragmente mit gesprochenem Audio synchronisiert. Das eigentliche Problem ist nicht das Timing — ElevenLabs liefert Wort-Zeitstempel. Das schwierige Problem ist die Ausrichtung: zu entscheiden, welches visuelle Fragment erscheinen soll, wenn der Sprecher anfängt, darüber zu reden.
Die Speaker Notes wiederholen den Slide-Text oft nicht wortwörtlich. Manchmal paraphrasiert die Erzählung einen Bullet Point. Manchmal werden zwei Punkte zu einem Gedanken zusammengezogen. Manchmal steht etwas auf der Folie, wird aber nie wirklich ausgesprochen. Das System rät also anhand von Keywords — und das funktioniert oft gerade gut genug, um vielversprechend zu wirken, bricht aber bei schwierigeren Slides zusammen.
Opus 4.6 mit mittlerem Thinking hatte damit über mehrere Sessions hinweg zu kämpfen. Es produzierte immer ausgefeiltere Heuristiken — gleichmäßige Splits nach Textlänge, Keyword-Suche in Zeitstempeln, Satz-für-Satz-Matching, Dual-Strategy-Matching — jede etwas besser, aber im Kern immer noch begrenzt.
GPT-5.4 im High-Thinking-Modus hat das architektonische Problem erkannt: Das ist gar kein Keyword-Matching-Problem. Es ist ein Datenmodell-Problem. Der Renderer sollte die tatsächlichen Fragment-Zustände ausgeben, der Assembler sollte die Erzählung gegen diese Zustände ausrichten, und die Validierung sollte Slides markieren, bei denen visuelle Struktur und Erzählung nicht zueinander passen.
Das war die richtige Einsicht. Der Sprung von „Sync aus Text erraten" zu „Sync als expliziten First-Class-Teil der Pipeline modellieren" war genau der Architektur-Frame, den das Problem gebraucht hat. Und GPT-5.4 kam schneller dorthin als Opus.
Wo gewinnt Claude Code weiterhin?
Aber hier ist die Sache: Ausführungsqualität und architektonische Einsicht sind nicht dasselbe.
Ausführungsqualität
Das klarste Beispiel: Ich habe beide Tools gebeten, Companion Notes über sieben Kursmodule hinweg zu auditieren und zu verbessern. Codex kam zurück und sagte mir, die Arbeit sei erledigt.
Claude Code kam mit Folgendem zurück:
Audit abgeschlossen — alle 7 Module
Stufe 1: Die 15 vorhandenen dünnen Companion Notes reparieren (auf Standard bringen — schneller Gewinn)
Stufe 2: Companion Notes zu ~25-30 priorisierten Slides hinzufügen (Kern-Frameworks, Tool-Listen, mehrstufige Prozesse, dichte Statistiken)
Das ist nicht „fertig". Das ist eine strukturierte Gap-Analyse, die 40-45 Slides identifiziert, priorisiert in Stufen. Der Unterschied zwischen „Ich habe die Aufgabe erledigt" und „Ich habe die Aufgabe erledigt und hier ist, was ich dabei gefunden habe" ist erheblich, wenn man ein echtes Produkt shippt.
Automatische QA
Das ist Claude Codes Killer-Feature, und ich glaube nicht, dass genug darüber gesprochen wird. Nachdem ein Implementierungsblock abgeschlossen ist, dispatcht Claude Code automatisch QA-Agenten — Code Review, Narrative Review, Konsistenzchecks — ohne dass ich überhaupt danach frage. Das ist in Claude Code selbst eingebaut.
Codex hat das noch nicht. Wenn Codex sagt, es ist fertig, muss man selbst verifizieren oder den eigenen Review-Prozess darum herum bauen. Bei Claude Code ist die Verifikation Teil des Workflows. Brillant.
Paralleles Agentenmanagement
Claude Codes Agenten-Orchestrierung ist reifer. Es startet mehrere spezialisierte Agenten, verwaltet deren Ergebnisse, synthetisiert die Findings und präsentiert eine kohärente Zusammenfassung. Ich hatte Sessions mit 5-6 Agenten gleichzeitig — Explorer, Code Reviewer, Implementierungsagent, Test Runner — sauber koordiniert.
Codex' Multi-agent-Support ist vielversprechend, aber noch früher in seiner Entwicklung. Es funktioniert, aber die Koordination fühlt sich noch nicht so nahtlos an.
Konsistenz
Über lange Sessions mit vielen beweglichen Teilen — etwa beim Produzieren von Slides über sieben Module mit 18 Layout-Typen — hält Claude Code die Konsistenz besser. Design Tokens bleiben korrekt, Namenskonventionen halten, und Architekturentscheidungen aus Stunde eins gelten auch noch in Stunde vier.
Kann man Workflows zwischen beiden Tools übertragen?
Ein Workflow, den ich nicht erwartet hatte: Codex zu nutzen, um Claude Codes Plugin-Ökosystem zu analysieren und daran angelehnte Skills zu bauen.
Ich mag einige Claude-Code-Plugins besonders gern: den Feature-Development-Workflow (/feature-dev), das Code-Review-System (/code-review), den Code-Simplifier (/code-simplifier), das Superpowers-Planungs-Framework (/superpowers) und den Frontend-Design-Skill (/frontend-design). Das sind gut gestaltete Workflows, die Best Practices direkt ins Tool einbauen.
Also habe ich Codex gebeten, sie zu studieren und äquivalente Codex-Skills zu bauen:
"Ich schreibe user-level Codex skills unter
~/.codex/skills, nutze die Claude-Plugin-Workflows als Vorlage und passe sie an Codex' Skill-Modell an — dort, wo Claude-spezifische Dinge wie Hooks oder Plugin-Commands nicht existieren."
Das hat funktioniert. Nicht perfekt — manche Claude-Code-Konzepte haben in Codex keine direkte Entsprechung — aber die Kern-Workflows ließen sich gut übertragen. Jetzt habe ich strukturierte Entwicklungsprozesse in beiden Tools, gespeist aus derselben Design-Philosophie.
Was passiert, wenn beide Models die Arbeit des jeweils anderen reviewen?
Ich glaube, das ist die wertvollste Erkenntnis dieser Woche.
Wenn Opus 4.6 einen Plan von GPT-5.4 kritisch reviewt und GPT-5.4 anschließend den von Opus überarbeiteten Plan erneut reviewt — also ein paar Runden hin und her — dann entsteht ein deutlich besseres Ergebnis, als wenn eines der Models allein arbeitet.
Sie finden unterschiedliche Schwächen. Opus entdeckt eher architektonische Inkonsistenzen und Edge Cases im Error Handling. GPT-5.4 erkennt eher Over-Engineering und schlägt einfachere Wege vor. Sie ergänzen gegenseitig ihre blinden Flecken.
Ich mache das inzwischen bei jedem nicht-trivialen Implementierungsplan: Entwurf in einem Tool, Review im anderen, überarbeiten, nochmal reviewen. Zwei oder drei Runden. Der finale Plan ist enger, robuster und fängt Probleme ab, die keines der beiden Models allein gesehen hat.
Wenn du nur ein einziges AI-Coding-Tool nutzt, lässt du Qualität auf dem Tisch liegen. Nicht weil eines der Tools schlecht wäre — beide sind wirklich stark — sondern weil sie unterschiedlich denken. Und unterschiedliches Denken findet unterschiedliche Probleme.
Was passiert, wenn eines der Tools ausfällt?
Am 11. März hatte Claude Code erhöhte Fehlerraten — Login-Probleme, langsame Performance, sporadische Ausfälle. Für mehrere Stunden war es effektiv kaum nutzbar.
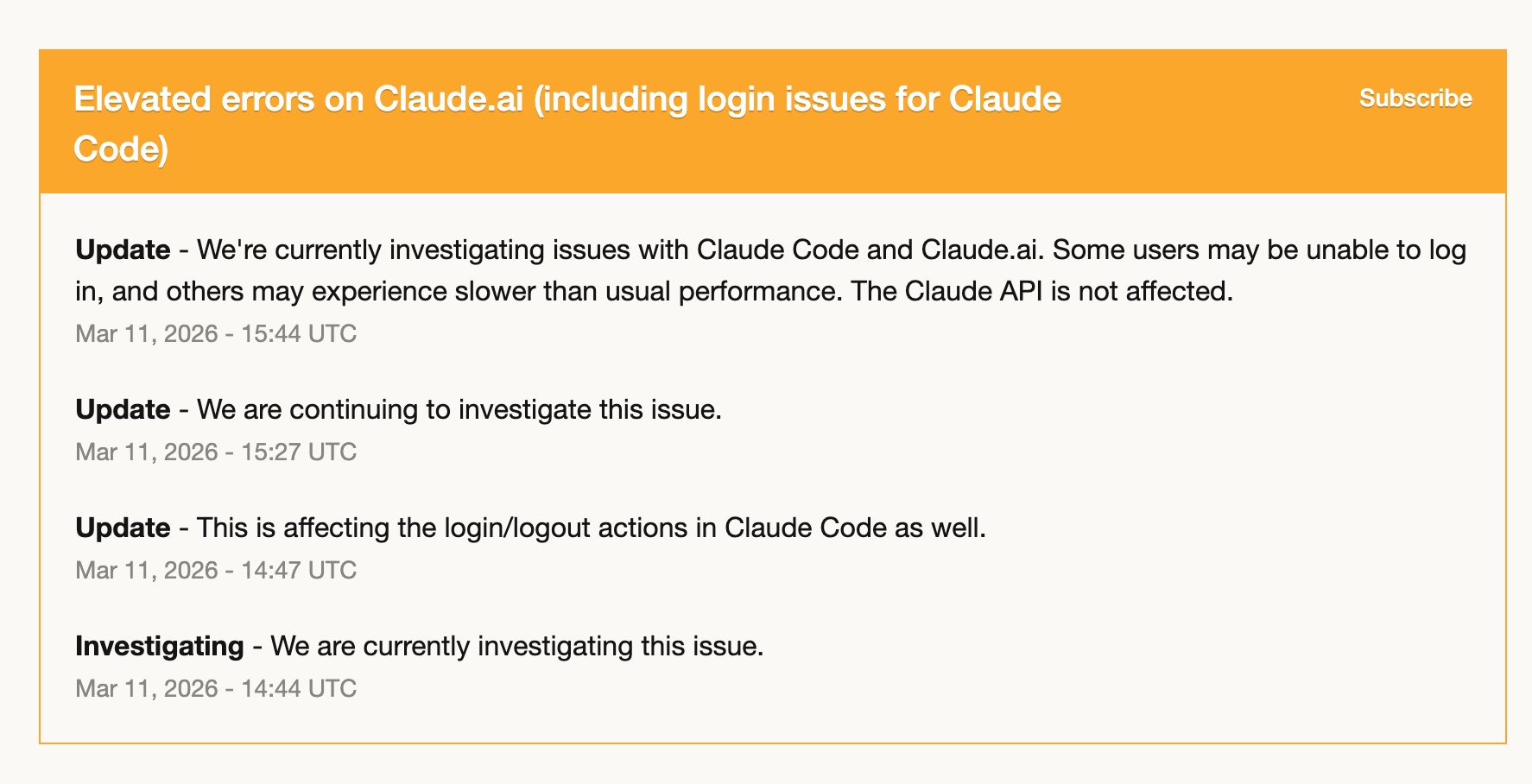
Weil ich mich zu diesem Zeitpunkt bereits in Codex eingearbeitet hatte, bin ich fast vollständig dorthin gewechselt. Und es war okay. Meine Codex-Skills waren eingerichtet, meine Workflows übertragen, und GPT-5.4 hat die Arbeit solide übernommen.
Diese Erfahrung hat für mich etwas klar gemacht: Komplett von einem einzigen Tool abhängig zu sein, ist ein Risiko. Nicht weil das Tool unzuverlässig wäre — Claude Code war in dem Jahr, in dem ich es nutze, bemerkenswert stabil — sondern weil jeder Dienst mal einen schlechten Tag haben kann. Ein zweites Tool zu haben, mit dem man wirklich arbeiten kann, ist kein Luxus. Es ist operative Resilienz.
Gegenüberstellung: Claude Code vs. Codex auf einen Blick
| Dimension | Claude Code (Opus 4.6) | Codex (GPT-5.4) |
|---|---|---|
| Ausführungsqualität | Tiefer — findet Lücken, priorisiert Arbeit | Gut — erledigt Aufgaben, weniger proaktive Analyse |
| Automatische QA | Eingebaut, dispatcht Review-Agenten automatisch | Noch nicht — manuelle Verifikation nötig |
| Parallele Agenten | Reif — 5-6 koordinierte Agenten | Vielversprechend — funktioniert, aber weniger nahtlos |
| Architektonisches Denken | Stark im mittleren Thinking | Exzellent im High Thinking — schnellere Reframes |
| Ausdauer bei Plan-Ausführung | Gut | Beeindruckend — 46+ Minuten am Stück |
| Kontextkomprimierung | Langsamer | Schneller — anders, nicht zwingend besser |
| Lokalisierung im großen Maßstab | Auf Augenhöhe (Opus 4.6 medium) | Auf Augenhöhe — aktuell günstiger |
| Plugin-/Skill-Ökosystem | Reif (Superpowers, /feature-dev usw.) | Wachsend — Claude-Workflows lassen sich übertragen |
| Cross-Model-Review | Findet Edge Cases, Inkonsistenzen | Findet Over-Engineering, vereinfacht |
| Kosten | $100-200/Monat | Kostenloser Testmonat, danach TBD |
Noch ein paar Beobachtungen
Kontextmanagement: Codex scheint Kontext schneller zu komprimieren, sobald das Fenster voll ist. Ich bin noch nicht sicher, ob das besser oder schlechter ist — aber es ist deutlich anders als bei Claude Code.
Lokalisierung im großen Maßstab: Ich habe mit Claude Code und Opus 4.6 3,9 Millionen Wörter in 12 Sprachen übersetzt. Die Übersetzungsqualität von GPT-5.4 ist auf dem Niveau von Opus 4.6 im mittleren Thinking — und im Moment ist es für mich günstiger, es im großen Maßstab laufen zu lassen. Deshalb habe ich einen Teil meiner Bulk-Lokalisierungsarbeit auf GPT-5.4 verlagert. Wie lange dieser Kostenvorteil bleibt, weiß ich nicht. Aber solange er da ist, ergibt das für mich Sinn.
Kosten: Ich bin bei Claude Code im $200/Monat-Max-Plan. Jetzt, da Codex einen relevanten Teil meiner Arbeit übernimmt — vor allem Lokalisierung — überlege ich, auf das $100-Tier herunterzugehen. OpenAIs kostenloser Testmonat hilft beim Übergang. Aber selbst zum vollen Preis könnte es günstiger sein, die Arbeit auf zwei Tools mit kleineren Plänen zu verteilen, statt ein einziges maximal auszureizen.
Wo ich gelandet bin
Nach einer Woche echten Dual-Wieldings ist das mein aktuelles Arbeitsmodell:
Greif zu Claude Code, wenn du Ausführungsqualität mit eingebauter QA brauchst, komplexe Multi-Agent-Orchestrierung, lange Konsistenz über große Codebasen hinweg oder wenn du in einem Projekt arbeitest, in dem der Superpowers-Workflow bereits eingerichtet ist.
Greif zu Codex, wenn du eine frische architektonische Perspektive brauchst, High-Thinking auf ein hartes Problem ansetzen willst, einen klar definierten Plan über längere Zeit sauber ausführen lassen willst oder Claude Code gerade einen schlechten Tag hat.
Nutze beide für jeden nicht-trivialen Implementierungsplan. Entwurf im einen, Review im anderen. Diese Cross-Model-Review-Schleife ist ehrlich gesagt der beste Workflow, den ich bisher gefunden habe.
Ich verlasse Claude Code nicht — es ist immer noch mein primäres Tool und das Ökosystem, das ich am besten kenne. Aber ich bin kein Single-Tool-Entwickler mehr. GPT-5.4 hat sich seinen Platz in meinem Workflow durch echte Leistungsfähigkeit verdient, nicht nur als Backup.
Die Zukunft AI-gestützter Entwicklung liegt für mich nicht darin, einen Sieger zu küren. Sondern darin zu wissen, wann man zu welchem Tool greift — und, noch wichtiger, dass die Tools zusammen besser sind als getrennt.
Häufig gestellte Fragen
Ist GPT-5.4 besser zum Coden als Opus 4.6?
Keines der beiden ist pauschal besser. GPT-5.4 im High-Thinking-Modus ist stark bei architektonischem Denken und ausdauernder Plan-Ausführung. Opus 4.6 ist stark bei Ausführungsqualität, proaktiver Gap-Analyse und Konsistenz über lange Sessions hinweg. Die besten Ergebnisse entstehen, wenn beide Models die Arbeit des jeweils anderen reviewen.
Sollte ich von Claude Code zu Codex wechseln?
Einen kompletten Wechsel würde ich nicht empfehlen. Beide Tools haben unterschiedliche Stärken — Claude Codes automatische QA und parallele Agenten-Orchestrierung sind wirklich voraus, während Codex' Ausdauer bei klaren Plänen und GPT-5.4s Denken bei schwierigen Problemen beeindruckend sind. Der Dual-Wielding-Ansatz gibt dir das Beste aus beiden Welten.
Lohnt sich der zusätzliche Aufwand für Cross-Model-Review?
Bei nicht-trivialen Plänen: absolut. Wenn Opus GPT-5.4 reviewt und umgekehrt, tauchen unterschiedliche Kategorien von Problemen auf — Opus findet Edge Cases und Inkonsistenzen, GPT-5.4 deckt Over-Engineering auf. Zwei oder drei Runden führen spürbar zu strafferen Plänen.
Was kostet ein Setup mit zwei Tools?
Claude Code liegt je nach Plan bei $100-200 pro Monat. Codex-Preise variieren — OpenAI bietet aktuell einen kostenlosen Testmonat an. Selbst zum vollen Preis kann es günstiger sein, die Last auf zwei Tools mit kleineren Plänen zu verteilen, statt eines maximal auszufahren.
Kann man Claude-Code-Plugins in Codex nutzen?
Nicht direkt, aber man kann sie übertragen. Ich habe Codex genutzt, um Claude-Code-Workflows (/feature-dev, /code-review, /superpowers) zu analysieren und die Kernlogik in Codex-Skills unter ~/.codex/skills zu übersetzen. Manche Claude-spezifischen Dinge wie Hooks lassen sich nicht direkt abbilden, die Workflows selbst aber schon.
Das war's von mir. Mich würde interessieren — arbeiten noch andere mit Multi-Model-Workflows? Nutzt ihr Claude Code und Codex zusammen oder andere Kombinationen? Welche Muster seht ihr?
Viele Grüße, Chandler





