Reacciones a "Bing AI no es de fiar"
Verifiqué los datos que el verificador de hechos señaló sobre Bing AI fabricando datos financieros — resulta que el problema de los números inventados es real y peor de lo que esperaba.
Este artículo fue escrito en 2023. Algunos detalles pueden haber cambiado desde entonces.
Hoy me encontré con este artículo: Bing AI can't be trusted, y naturalmente, me despertó la curiosidad. Es un buen artículo lleno de verificaciones de hechos que demuestran que el nuevo Bing Chat incluye muchos hechos inventados sobre información factual. La entrada es relativamente corta, así que adelante y léela.
Así que aquí van mis reacciones rápidas:
Sorprendido y no sorprendido al mismo tiempo
En general, soy consciente de las limitaciones del modelo de lenguaje grande (LLM), del cual ChatGPT es uno. Las tres principales son:
- No indexa la web más allá de datos de texto (como video, audio, imágenes, etc…)
- El conjunto de datos de ChatGPT es realmente antiguo (2021)
- Estos modelos inventan palabras porque no saben qué fuente de información es más autoritativa/confiable que otras.
Así que esperaba que con la integración de Bing y OpenAI, el motor de búsqueda de Bing pudiera resolver todas las limitaciones anteriores. Bueno, parece que basándose en el artículo de Dmitri, Bing no lo ha resuelto todavía. Ni de lejos. 🙁
Verificar el artículo de nuevo
No estaría bien aprender que lo que mencionó Dmitri tampoco era factualmente correcto. Así que fui adelante e hice mis propias verificaciones de hechos. Empecé con los estados financieros de Gap porque parece lo más sencillo de verificar. Incluyo las fuentes y capturas de pantalla a continuación para que no tengas que repetir este ejercicio:
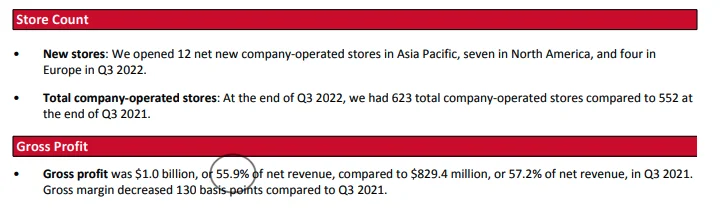
- Este es el informe de resultados del tercer trimestre de 2022 de Gap.
- Tomé la captura de pantalla a continuación del estado de Gap y resalté los números clave en rojo. Dmitri tiene razón, Bing Chat inventó los números como el margen bruto ajustado, el margen operativo, etc…

¿Y los números de Lululemon?
- Este es el informe financiero del tercer trimestre de 2022 de Lululemon. Lo mismo, resalté los números clave mencionados en el artículo de Dmitri en las capturas de pantalla a continuación. Tiene razón, Bing Search inventó números.

En cuanto al itinerario de Ciudad de México, no soy experto en este tema, así que no puedo verificar los hechos cuidadosamente. Por ejemplo, cuando busqué "Primer Nivel Night Club - Antro", encontré esta página de Facebook. Pero no tengo forma de verificar al 100% de certeza si las sugerencias de Bing Search son válidas o no.
¿A dónde vamos desde aquí?
Parece claro que en este momento, la integración de Bing y OpenAI no ha podido solucionar el problema de que los modelos de lenguaje grandes (LLMs) simplemente inventen cosas sobre la marcha todavía.
No soy suficientemente técnico para entender lo difícil que es resolver este problema. Si se equivoca tanto con datos factuales, necesitamos tener cuidado con temas más subjetivos como los mejores restaurantes/fontaneros/servicios locales, finanzas personales, salud, relaciones, etc.
Ahora bien, para ser justos con Bing y OpenAI, dijeron durante la presentación que entienden que la nueva tecnología puede equivocarse en muchas cosas, por lo que diseñaron la interfaz de "pulgar arriba/pulgar abajo" para que los usuarios puedan darles feedback fácilmente. Con suerte, con más retroalimentación de los usuarios, la máquina mejorará.
¿Un algoritmo para verificar los hechos de los LLM?
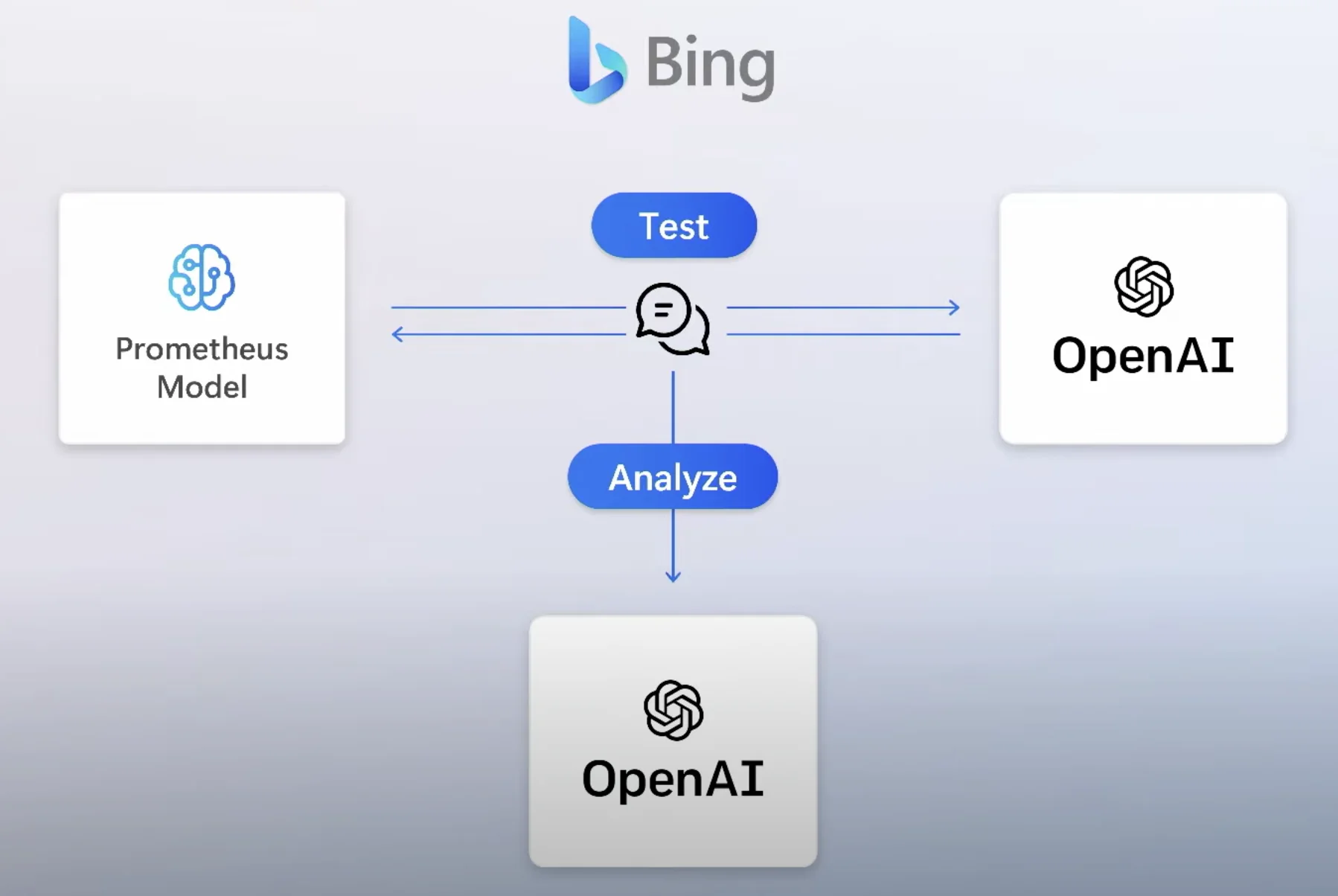
Dado que los LLM a menudo producen resultados incorrectos, ¿qué tal crear un algoritmo para verificar continuamente el resultado? Esto es similar a lo que Microsoft comentó sobre el algoritmo de seguridad que incorporaron en Prometheus, simulando prompts de actores maliciosos a la máquina.
El papel del ser humano
Esta tecnología parece estar en una etapa temprana, y aunque el progreso es exponencial, el papel del ser humano es fundamental. No podemos confiar en el resultado todavía, incluso con la integración de Bing y OpenAI. La máquina puede ayudarnos con el 50% del resultado deseado (más o menos), pero necesitamos poner el otro 50%.
Parece que hay tiempo suficiente para que nos adaptemos, aprendamos las fortalezas y limitaciones de esta tecnología, y la usemos de manera efectiva.
En cuanto a los ingenieros que diseñan estos sistemas, probablemente necesitan hacer un mejor trabajo destacando a los usuarios finales los puntos de datos y oraciones de los que la máquina no está segura. Nuestros cerebros humanos gustan de los atajos, así que estoy seguro de que muchos de nosotros (yo incluido) tomaremos el camino fácil y aceptaremos lo que dice la máquina como verdad :P Es difícil estar en guardia el 100% del tiempo.
¿Has encontrado alguna respuesta generada por IA que estuviera confiadamente equivocada? Me encantaría escuchar tus ejemplos — cuanto más específicos, mejor.
Un abrazo,
Chandler