Codex con GPT-5.4 vs Claude Code con Opus 4.6 — Por qué ahora uso ambos
Después de usar Claude Code con Opus 4.6 todos los días durante casi un año, pasé una semana con Codex y GPT-5.4. El veredicto: ninguna herramienta gana de forma absoluta. La combinación — revisión entre modelos, fortalezas complementarias y resiliencia operativa — es mejor que cualquiera de las dos por separado.
Después de usar Claude Code todos los días durante casi un año, pasé una semana con Codex y GPT-5.4. Ninguna herramienta gana de forma absoluta — pero usar ambas juntas, con revisión entre modelos, produce mejores resultados que cualquiera de las dos por separado. Esto es lo que encontré, desde la perspectiva de alguien que ya ha enviado productos reales con ambas.
He usado Claude Code con Opus 4.6 como mi herramienta principal de desarrollo para todo: reconstruir este sitio, llevar DIALØGUE a la App Store, construir STRAŦUM, traducir 3,9 millones de palabras en 12 idiomas y producir una pipeline completa de video para un curso con 18 tipos de layout y sincronización de audio a nivel de palabra.
Así que cuando OpenAI lanzó GPT-5.4 con Codex el 5 de marzo, no estaba buscando un reemplazo. Solo tenía curiosidad. Además, OpenAI estaba ofreciendo un mes gratis, así que era fácil probarlo sin demasiado compromiso.
Me sorprendió para bien. Más que para bien, en realidad — Codex con GPT-5.4 era genuinamente capaz de formas que no esperaba.
Una semana después, no estoy cambiando de herramienta. Estoy usando las dos. Y creo que la combinación es mejor que cualquiera de las dos por separado.
¿Por qué importa distinguir entre el harness y el modelo?
Antes de entrar en detalles, hay un matiz que creo que casi todas las comparativas pasan por alto.
Claude Code y Codex son harnesses — las herramientas CLI, la orquestación de agentes, los ecosistemas de plugins, la gestión de contexto, la forma en que interactúan con tu sistema de archivos y tu terminal. Opus 4.6 y GPT-5.4 son los modelos subyacentes — la inteligencia que toma las decisiones reales sobre qué hacer, cómo razonar un problema y qué código escribir.
Esto importa porque algunas de mis observaciones son sobre el harness y otras son sobre el modelo. El despacho automático de QA y la gestión de agentes en paralelo de Claude Code es el harness. La intuición arquitectónica de GPT-5.4 sobre mi problema de sincronización de fragmentos es el modelo. Cuando hablo de revisión cruzada entre modelos para producir mejores planes, eso es específicamente sobre cómo razonan los modelos — el harness solo entrega la salida.
Un mejor modelo dentro de un peor harness puede seguir siendo frustrante. Un gran harness con un modelo más flojo puede sentirse pulido, pero superficial. Ahora mismo, ambas combinaciones son fuertes — pero lo son de maneras distintas.
¿Cómo se sintió Codex con GPT-5.4 en el primer uso?
Voy a ser sincero — esperaba que Codex se sintiera como un paso atrás. Llevo mucho tiempo metido en el ecosistema de Claude Code: el plugin Superpowers para planificación estructurada, el despacho de agentes en paralelo, los agentes de code review que se ejecutan automáticamente después de implementar. Es un flujo de trabajo bastante maduro.
Codex con GPT-5.4 se sintió competitivo de inmediato. El modelo es fuerte. El razonamiento es sólido. Sigue bien los planes. Cuando le di un plan de implementación bien estructurado, pudo trabajar de forma continua durante más de 45 minutos sin perder el hilo — haciendo commits, ejecutando tests, empujando cambios y pasando a la siguiente tarea.
Activé algunas funciones experimentales de Codex bastante pronto:
- Multi-agents — ejecución paralela de tareas, parecida al despacho de agentes de Claude Code
- JavaScript REPL — un runtime persistente basado en Node para depuración inline
- Prevent sleep while running — mantiene la máquina despierta durante sesiones largas
Eso marcó una diferencia. El soporte multiagente, en particular, me dio la sensación de que Codex estaba alcanzando un tipo de flujo del que ya dependía en Claude Code.
¿Dónde superó GPT-5.4 a Opus 4.6?
Tengo que admitirlo — hubo un área en la que GPT-5.4 superó claramente a Opus 4.6, y no fue una diferencia menor.
He estado construyendo una pipeline de video para cursos que sincroniza fragmentos de diapositivas con audio narrado. El problema difícil no es el timing — ElevenLabs nos da timestamps a nivel de palabra. El problema difícil es la alineación: decidir qué fragmento en pantalla debe aparecer cuando el narrador empieza a hablar de ello.
Las notas del narrador muchas veces no repiten el texto de la diapositiva palabra por palabra. A veces la narración parafrasea un bullet, a veces combina dos bullets en una sola idea, y a veces hay un bullet en pantalla que realmente nunca se menciona. Así que el sistema va adivinando a partir de keywords. Eso funciona lo suficiente como para parecer prometedor, pero se rompe en las diapositivas difíciles.
Opus 4.6 en modo de razonamiento medio se atascó con esto durante varias sesiones. Seguía proponiendo heurísticas cada vez más ingeniosas — divisiones iguales por longitud de texto, búsqueda de keywords en timestamps, matching a nivel de frase, matching con doble estrategia — cada una un poco mejor, pero todas seguían siendo limitadas en el fondo.
GPT-5.4 en high thinking identificó el problema arquitectónico: esto no debería tratarse como un problema de matching por keywords. Debería tratarse como un problema de modelo de datos. El renderer debería emitir los estados reales de los fragmentos, el ensamblador debería alinear la narración con esos estados y la validación debería marcar las diapositivas en las que la estructura visual y la narración no encajan.
Era la intuición correcta. El cambio de “adivinar la sincronización a partir del texto” a “hacer que la sincronización sea una parte explícita y de primera clase de la pipeline” era exactamente el reencuadre arquitectónico que el problema necesitaba. Y GPT-5.4 llegó ahí más rápido de lo que Opus había llegado.
¿Dónde sigue ganando Claude Code?
Pero aquí está la cuestión — la calidad de ejecución y la capacidad de seguimiento no son lo mismo que la intuición arquitectónica.
Calidad de ejecución
El ejemplo más claro: pedí a ambas herramientas que auditaran y mejoraran las companion notes de siete módulos de un curso. Codex volvió y me dijo que el trabajo estaba hecho.
Claude Code volvió con esto:
Audit Complete — All 7 Modules
Tier 1: Fix the 15 existing thin companion notes (bring them up to standard — quick win)
Tier 2: Add companion notes to ~25-30 high-priority slides (core frameworks, tool lists, multi-step processes, dense stats)
Eso no es “hecho”. Es un análisis estructurado de vacíos que identifica entre 40 y 45 diapositivas que necesitan atención, además de priorizarlas por niveles. La diferencia entre “completé la tarea” y “completé la tarea y esto es lo que encontré” es importante cuando estás enviando un producto real.
QA automático
Esta es la killer feature de Claude Code y creo que no se habla lo suficiente de ella. Después de completar un bloque de implementación, Claude Code lanza automáticamente agentes de QA — revisión de código, revisión narrativa, comprobaciones de consistencia — sin que yo tenga que pedirlo. Está integrado en Claude Code.
Codex todavía no hace eso. Cuando Codex dice que ha terminado, tienes que verificarlo manualmente o montar tu propio proceso de revisión. Con Claude Code, la verificación ya forma parte del flujo. Brillante.
Gestión de agentes en paralelo
La orquestación de agentes de Claude Code es más madura. Despacha varios agentes especializados, gestiona sus resultados, sintetiza los hallazgos y presenta un resumen coherente. He tenido sesiones con 5 o 6 agentes corriendo al mismo tiempo — un explorador, un code reviewer, un agente de implementación, un runner de tests — todos coordinados.
El soporte multiagente de Codex es prometedor, pero todavía está antes en su desarrollo. Funciona, pero la coordinación aún no se siente igual de fluida.
Consistencia
En sesiones largas con muchas piezas moviéndose a la vez — por ejemplo, producir diapositivas para 7 módulos con 18 tipos de layout — Claude Code mantiene mejor la consistencia. Los design tokens se mantienen correctos, las convenciones de nombres aguantan y las decisiones arquitectónicas tomadas en la primera hora siguen respetándose en la cuarta.
¿Se pueden cruzar flujos de trabajo entre herramientas?
Hubo un flujo que no esperaba: usar Codex para inspeccionar el ecosistema de plugins de Claude Code y adaptarlo.
Me gustan especialmente varios plugins de Claude Code: el flujo de desarrollo de features (/feature-dev), el sistema de code review (/code-review), el simplificador de código (/code-simplifier), el framework de planificación de Superpowers (/superpowers) y la skill de diseño frontend (/frontend-design). Son flujos bien diseñados que convierten buenas prácticas en parte de la herramienta.
Así que le pedí a Codex que los estudiara y creara skills equivalentes para Codex:
"Estoy escribiendo skills de Codex a nivel de usuario en
~/.codex/skills, usando los workflows de plugins de Claude como plantilla y adaptándolos al modelo de skills de Codex allí donde las funciones exclusivas de Claude, como hooks o comandos de plugin, no existen."
Funcionó. No de forma perfecta — algunos conceptos de Claude Code no tienen equivalente directo en Codex — pero los workflows centrales sí se tradujeron bastante bien. Ahora tengo procesos de desarrollo estructurados en ambas herramientas, informados por la misma filosofía de diseño.
¿Qué pasa cuando haces que ambos modelos revisen el trabajo del otro?
Creo que este es el descubrimiento más valioso de la semana.
Hacer que Opus 4.6 revise críticamente un plan hecho por GPT-5.4, y luego hacer que GPT-5.4 revise la versión revisada por Opus — repitiendo ese ida y vuelta un par de veces — produce resultados mucho mejores que dejar trabajar a cualquiera de los dos por separado.
Detectan debilidades diferentes. Opus tiende a encontrar inconsistencias arquitectónicas y edge cases en el manejo de errores. GPT-5.4 tiende a detectar sobreingeniería y sugerir enfoques más simples. Se complementan muy bien en sus puntos ciegos.
He empezado a hacer esto con cualquier plan de implementación que no sea trivial: borrador en una herramienta, revisión en la otra, revisión, revisión de vuelta. Dos o tres rondas. El plan final queda más apretado, más robusto y captura problemas que ninguno de los dos modelos habría sacado a la luz por sí solo.
Si solo estás usando una herramienta de AI coding, estás dejando calidad sobre la mesa. No porque cualquiera de las dos sea mala — las dos son realmente excelentes — sino porque razonan de forma distinta, y esa diferencia de razonamiento encuentra problemas distintos.
¿Qué pasa cuando una herramienta se cae?
El 11 de marzo, Claude Code tuvo errores elevados — problemas de login, lentitud y fallos intermitentes. Durante varias horas fue, en la práctica, inutilizable.
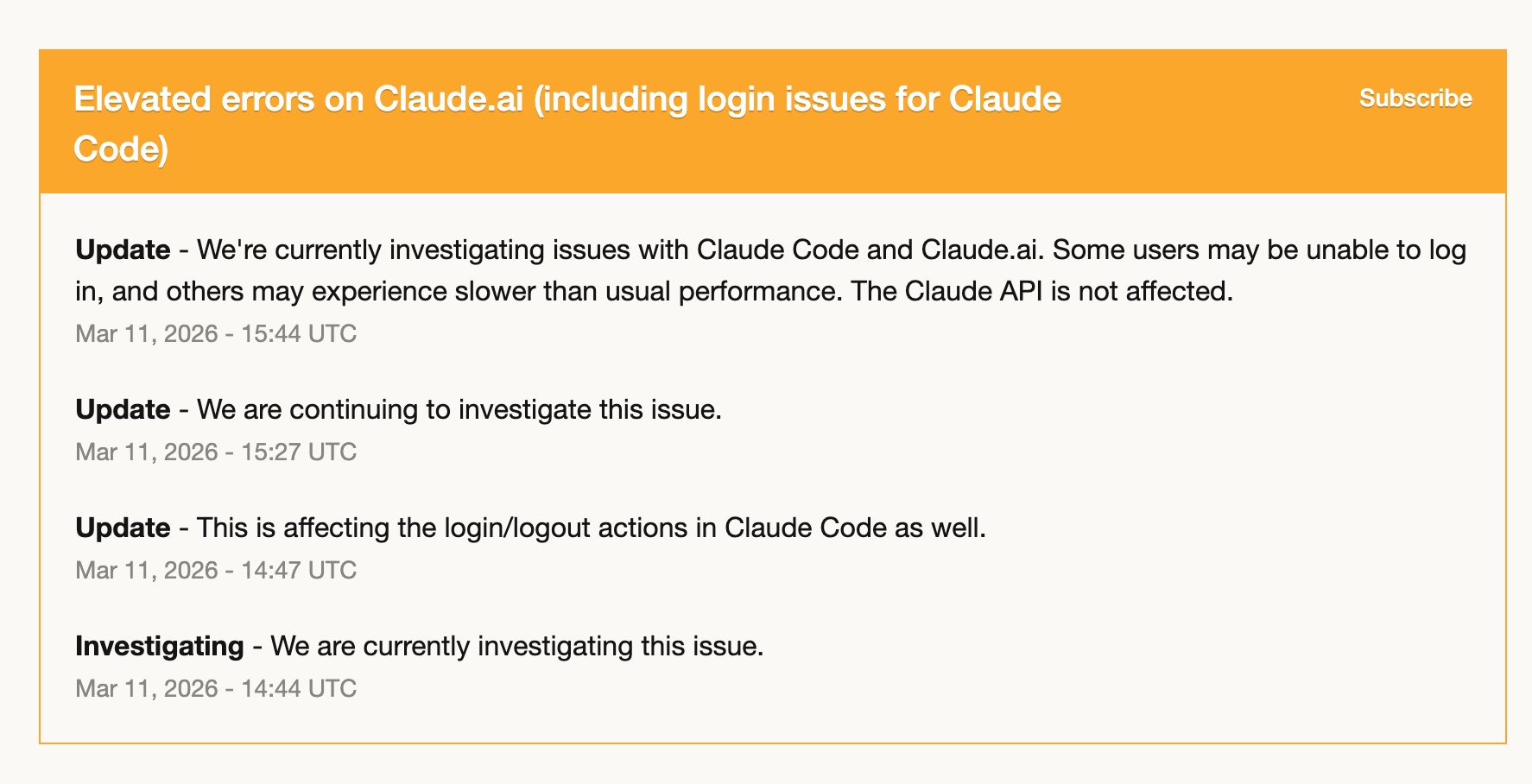
Como yo ya estaba entrando más en serio en Codex, me pasé casi por completo a él. Y estuve bien. Ya tenía mis skills de Codex montadas, mis workflows traducidos y GPT-5.4 manejó el trabajo con solvencia.
Esa experiencia me dejó algo muy claro: depender por completo de una sola herramienta es un riesgo. No porque la herramienta sea poco fiable — Claude Code ha sido notablemente estable durante el año en que la he usado — sino porque cualquier servicio puede tener un mal día. Tener una segunda herramienta con la que de verdad te sientas cómodo no es un lujo. Es resiliencia operativa.
Cara a cara: Claude Code vs Codex de un vistazo
| Dimensión | Claude Code (Opus 4.6) | Codex (GPT-5.4) |
|---|---|---|
| Calidad de ejecución | Más profunda — encuentra vacíos y prioriza trabajo | Buena — completa tareas, pero analiza menos por iniciativa propia |
| QA automático | Integrado, despacha agentes de revisión automáticamente | Todavía no — hace falta verificación manual |
| Agentes en paralelo | Maduro — 5 o 6 agentes coordinados | Prometedor — funciona, pero aún menos fluido |
| Razonamiento arquitectónico | Fuerte en modo medio | Excelente en high thinking — reencuadra más rápido |
| Ejecución sostenida de planes | Buena | Impresionante — más de 46 minutos continuos |
| Compactación de contexto | Más lenta | Más rápida — distinta, no necesariamente mejor |
| Localización a escala | A la par (Opus 4.6 medium) | A la par — ahora mismo más barato |
| Ecosistema de plugins/skills | Maduro (Superpowers, /feature-dev, etc.) | En crecimiento — puede adaptar workflows de Claude |
| Revisión cruzada entre modelos | Detecta edge cases e inconsistencias | Detecta sobreingeniería y propone simplificar |
| Coste | 100-200 $/mes | Promoción de un mes gratis, luego TBD |
Algunas observaciones más
Gestión del contexto: Codex parece compactar el contexto más rápido una vez que se llena la ventana. Todavía no he decidido si eso es mejor o peor — solo es claramente distinto de cómo lo maneja Claude Code.
Localización a escala: traducí 3,9 millones de palabras en 12 idiomas usando Claude Code con Opus 4.6. La calidad de traducción de GPT-5.4 está a la par de Opus 4.6 en medium thinking — y, por ahora, me sale más barato usarlo a gran escala. Así que he ido moviendo mi trabajo de localización masiva hacia GPT-5.4. No sé cuánto durará esa ventaja de coste, pero mientras exista, tiene sentido aprovecharla.
Coste: Estoy en el plan Max de Claude Code de 200 $ al mes. Ahora que Codex está manejando una parte significativa de mi carga — sobre todo localización — me estoy planteando bajar al nivel de 100 $. El mes gratis de OpenAI ayuda con la transición, pero incluso a precio completo, repartir la carga entre dos herramientas en niveles más bajos puede salir mejor que exprimir una sola al máximo.
Dónde he terminado
Después de una semana de auténtico uso dual, este es mi modelo de trabajo ahora mismo:
Acude a Claude Code cuando: necesites calidad de ejecución con QA integrado, orquestación compleja de múltiples agentes, consistencia a largo plazo en codebases grandes o estés trabajando en un proyecto donde el workflow de Superpowers ya está montado.
Acude a Codex cuando: necesites una perspectiva arquitectónica fresca, quieras usar high thinking en un problema de razonamiento difícil, estés ejecutando un plan bien definido que se beneficie de trabajo sostenido sin interrupciones o Claude Code esté teniendo un mal día.
Usa ambos para: cualquier plan de implementación que no sea trivial. Haz el borrador en uno y la revisión en el otro. El bucle de revisión cruzada entre modelos es, de verdad, el mejor workflow que he encontrado hasta ahora.
No estoy abandonando Claude Code — sigue siendo mi herramienta principal y el ecosistema que mejor conozco. Pero ya no soy un desarrollador de una sola herramienta. GPT-5.4 se ganó su lugar en mi flujo por capacidad real, no solo como backup.
El futuro del desarrollo asistido por IA no consiste en elegir un ganador. Consiste en saber cuándo recurrir a cada herramienta y — más importante todavía — saber que las herramientas funcionan mejor juntas que por separado.
Preguntas frecuentes
¿GPT-5.4 es mejor que Opus 4.6 para programar?
Ninguno es estrictamente mejor. GPT-5.4 en high thinking destaca en razonamiento arquitectónico y ejecución sostenida de planes. Opus 4.6 destaca en calidad de ejecución, análisis proactivo de vacíos y consistencia en sesiones largas. Los mejores resultados llegan cuando usas ambos modelos para revisar el trabajo del otro.
¿Debería cambiar de Claude Code a Codex?
No recomendaría un cambio total. Ambas herramientas tienen fortalezas propias — el QA automático y la orquestación de agentes en paralelo de Claude Code van realmente por delante, mientras que la ejecución sostenida de Codex y el razonamiento de GPT-5.4 en problemas difíciles impresionan bastante. El enfoque de usar ambas te da lo mejor de las dos.
¿Vale la pena el workflow de revisión cruzada entre modelos?
Para planes no triviales, absolutamente. Hacer que Opus revise la salida de GPT-5.4 y viceversa detecta categorías distintas de problemas — Opus encuentra edge cases e inconsistencias, GPT-5.4 detecta sobreingeniería. Dos o tres rondas producen planes claramente más sólidos que dejar a cualquiera de los dos por su cuenta.
¿Cuánto cuesta una configuración con dos herramientas?
Claude Code cuesta entre 100 y 200 $ al mes, según el plan. El precio de Codex varía — OpenAI está ofreciendo ahora mismo una promoción de un mes gratis. Incluso a precio completo, repartir la carga entre dos herramientas en niveles más bajos puede salir mejor que llevar una sola al máximo.
¿Se pueden usar plugins de Claude Code dentro de Codex?
No directamente, pero sí se pueden adaptar. Usé Codex para inspeccionar workflows de plugins de Claude Code (/feature-dev, /code-review, /superpowers) y traducir su lógica central en skills de Codex dentro de ~/.codex/skills. Algunas funciones específicas de Claude, como los hooks, no se trasladan, pero los workflows sí.
Eso es todo por mi parte. Me da curiosidad: ¿alguien más está trabajando con flujos multi-modelo? ¿Usando Claude Code y Codex juntos, u otras combinaciones? ¿Qué patrones están encontrando?
Un abrazo, Chandler





