Codex avec GPT-5.4 vs Claude Code avec Opus 4.6 — Pourquoi j'utilise maintenant les deux
Après avoir utilisé Claude Code avec Opus 4.6 tous les jours pendant presque un an, j'ai passé une semaine avec Codex et GPT-5.4. Verdict : aucun outil ne gagne à lui seul. La combinaison — revue croisée entre modèles, forces complémentaires et résilience opérationnelle — est meilleure que chacun pris séparément.
Après avoir utilisé Claude Code tous les jours pendant presque un an, j'ai passé une semaine avec Codex et GPT-5.4. Aucun outil ne gagne à lui seul — mais utiliser les deux ensemble, avec revue croisée entre modèles, produit de meilleurs résultats que chacun séparément. Voilà ce que j'ai constaté, du point de vue de quelqu'un qui a déjà livré de vrais produits avec les deux.
J'ai utilisé Claude Code avec Opus 4.6 comme outil principal de développement pour tout : reconstruire ce site, emmener DIALØGUE sur l'App Store, construire STRAŦUM, traduire 3,9 millions de mots en 12 langues et produire une pipeline complète de vidéos de cours avec 18 types de layout et une synchronisation audio au niveau du mot.
Donc quand OpenAI a lancé GPT-5.4 avec Codex le 5 mars, je ne cherchais pas un remplaçant. J'étais simplement curieux. OpenAI proposait aussi un mois gratuit, donc c'était facile de tester sans trop s'engager.
J'ai été agréablement surpris. Plus qu'agréablement surpris, même — Codex avec GPT-5.4 était réellement capable de choses auxquelles je ne m'attendais pas.
Une semaine plus tard, je ne suis pas en train de changer d'outil. Je joue sur les deux tableaux. Et je pense que la combinaison est meilleure que chacun des deux pris isolément.
Pourquoi la distinction entre le harness et le modèle est-elle importante ?
Avant d'entrer dans le détail, il y a une nuance que la plupart des comparatifs ratent, je pense.
Claude Code et Codex sont des harnesses — les outils CLI, l'orchestration d'agents, les écosystèmes de plugins, la gestion du contexte, la façon dont ils interagissent avec le système de fichiers et le terminal. Opus 4.6 et GPT-5.4 sont les modèles sous-jacents — l'intelligence qui décide concrètement quoi faire, comment raisonner sur un problème et quel code écrire.
Cette distinction compte parce que certaines de mes observations portent sur le harness, et d'autres sur le modèle. Le dispatch automatique du QA et la gestion d'agents parallèles de Claude Code ? C'est le harness. L'intuition architecturale de GPT-5.4 sur mon problème de synchronisation de fragments ? C'est le modèle. Quand je parle de revue croisée entre modèles pour produire de meilleurs plans, je parle bien de la façon dont les modèles raisonnent différemment — le harness ne fait que livrer la sortie.
Un meilleur modèle dans un moins bon harness peut rester frustrant. Un excellent harness avec un modèle plus faible peut sembler très poli, mais un peu plat. Aujourd'hui, les deux combinaisons sont fortes — mais pas de la même manière.
Comment Codex avec GPT-5.4 s'est-il comporté au premier usage ?
Je vais être honnête — je m'attendais à ce que Codex ressemble à un pas en arrière. Je suis profondément installé dans l'écosystème de Claude Code : le plugin Superpowers pour la planification structurée, le dispatch d'agents en parallèle, les agents de code review qui se lancent automatiquement après l'implémentation. C'est un workflow mature.
Codex avec GPT-5.4 s'est révélé immédiatement compétitif. Le modèle est solide. Le raisonnement est solide. Il suit bien les plans. Quand je lui ai donné un plan d'implémentation bien structuré, il a pu travailler plus de 45 minutes d'affilée sans perdre le fil — commit, tests, push, tâche suivante.
J'ai activé assez tôt quelques fonctionnalités expérimentales de Codex :
- Multi-agents — exécution parallèle de tâches, proche du dispatch d'agents de Claude Code
- JavaScript REPL — runtime persistant basé sur Node pour le débogage inline
- Prevent sleep while running — garde la machine éveillée pendant les longues sessions
Ça a fait une vraie différence. Le support multi-agents, en particulier, m'a donné l'impression que Codex rattrapait un style de workflow dont j'étais déjà devenu dépendant dans Claude Code.
Où GPT-5.4 a-t-il dépassé Opus 4.6 ?
Je dois l'admettre — il y a eu un domaine où GPT-5.4 a clairement battu Opus 4.6, et ce n'était pas un détail.
Je construis une pipeline vidéo de cours qui synchronise les fragments des slides avec un audio narré. Le problème difficile n'est pas le timing — ElevenLabs nous donne des timestamps au niveau du mot. Le vrai problème, c'est l'alignement : décider quel fragment à l'écran doit apparaître au moment exact où la narration commence à en parler.
Les notes du narrateur ne répètent souvent pas le texte de la slide mot pour mot. Parfois la narration paraphrase une puce, parfois elle en combine deux en une seule idée, parfois une puce est bien sur la slide mais n'est jamais vraiment prononcée. Du coup, le système essaie de deviner à partir de mots-clés. Ça fonctionne assez souvent pour sembler prometteur, mais ça casse sur les slides plus difficiles.
Opus 4.6 en mode medium thinking s'est battu avec ça pendant plusieurs sessions. Il continuait à proposer des heuristiques de plus en plus ingénieuses — découpage égal selon la longueur du texte, recherche de mots-clés dans les timestamps, matching au niveau de la phrase, double stratégie — chacune un peu meilleure, mais toujours limitée à la base.
GPT-5.4 en high thinking a vu le vrai problème architectural : ça ne devrait pas être traité comme un problème de matching par mots-clés. Ça devrait être traité comme un problème de modèle de données. Le renderer devrait émettre les véritables états de fragments, l'assembleur devrait aligner la narration sur ces états, et la validation devrait signaler les slides où la structure visuelle et la narration ne se correspondent pas.
C'était la bonne intuition. Passer de « deviner la synchro depuis le texte » à « faire de la synchro une partie explicite et de première classe de la pipeline » était exactement le reframe architectural dont le problème avait besoin. Et GPT-5.4 y est arrivé plus vite qu'Opus.
Où Claude Code garde-t-il l'avantage ?
Mais voilà le point important — la qualité d'exécution et le suivi ne sont pas la même chose que l'intuition architecturale.
Qualité d'exécution
L'exemple le plus clair : j'ai demandé aux deux outils d'auditer et d'améliorer les companion notes sur sept modules de cours. Codex est revenu en disant que le travail était terminé.
Claude Code est revenu avec ça :
Audit Complete — All 7 Modules
Tier 1: Fix the 15 existing thin companion notes (bring them up to standard — quick win)
Tier 2: Add companion notes to ~25-30 high-priority slides (core frameworks, tool lists, multi-step processes, dense stats)
Ça, ce n'est pas « terminé ». C'est une analyse structurée des manques qui identifie 40 à 45 slides à retravailler, avec une priorisation par paliers. La différence entre « j'ai accompli la tâche » et « j'ai accompli la tâche et voilà ce que j'ai trouvé » est importante quand on livre un vrai produit.
QA automatique
C'est la killer feature de Claude Code, et je trouve qu'on n'en parle pas assez. Une fois un bloc d'implémentation terminé, Claude Code déclenche automatiquement des agents de QA — code review, revue narrative, vérifications de cohérence — sans que j'aie à le demander. C'est intégré à Claude Code lui-même.
Codex ne fait pas encore ça. Quand Codex dit que c'est fini, il faut vérifier manuellement ou construire son propre processus de revue. Avec Claude Code, la vérification fait déjà partie du workflow. Brillant.
Gestion des agents parallèles
L'orchestration des agents de Claude Code est plus mature. Il dispatch plusieurs agents spécialisés, gère leurs résultats, synthétise les constats et présente un résumé cohérent. J'ai eu des sessions avec 5 ou 6 agents tournant en même temps — un explorateur, un code reviewer, un agent d'implémentation, un lanceur de tests — tous coordonnés.
Le support multi-agents de Codex est prometteur, mais encore plus tôt dans sa maturité. Ça marche, mais la coordination n'est pas encore aussi fluide.
Cohérence
Sur les longues sessions avec beaucoup d'éléments en mouvement — par exemple produire des slides sur 7 modules avec 18 types de layout — Claude Code maintient mieux la cohérence. Les design tokens restent corrects, les conventions de nommage tiennent, et les décisions architecturales prises dans la première heure sont toujours respectées à la quatrième.
Peut-on faire circuler des workflows entre les deux outils ?
Il y a un workflow que je n'avais pas anticipé : utiliser Codex pour inspecter l'écosystème de plugins de Claude Code et l'adapter.
J'aime particulièrement plusieurs plugins de Claude Code : le workflow de développement de features (/feature-dev), le système de code review (/code-review), le simplificateur de code (/code-simplifier), le framework de planification Superpowers (/superpowers) et la skill de frontend design (/frontend-design). Ce sont des workflows bien conçus qui encodent de bonnes pratiques directement dans l'outil.
J'ai donc demandé à Codex de les étudier et de créer des skills équivalentes pour Codex :
"J'écris des skills Codex au niveau utilisateur dans
~/.codex/skills, en utilisant les workflows de plugins Claude comme modèle et en les adaptant au modèle de skills de Codex là où les fonctionnalités propres à Claude, comme les hooks ou les commandes de plugin, n'existent pas."
Ça a fonctionné. Pas parfaitement — certains concepts de Claude Code n'ont pas d'équivalent direct dans Codex — mais les workflows essentiels se sont bien transposés. J'ai maintenant des processus de développement structurés dans les deux outils, guidés par la même philosophie.
Que se passe-t-il quand les deux modèles se relisent mutuellement ?
Je pense que c'est la découverte la plus précieuse de la semaine.
Faire relire de façon critique un plan GPT-5.4 par Opus 4.6, puis faire relire la version révisée par GPT-5.4 — en faisant plusieurs allers-retours — produit des résultats nettement meilleurs que laisser l'un ou l'autre travailler seul.
Ils voient des faiblesses différentes. Opus a tendance à repérer les incohérences architecturales et les edge cases dans la gestion d'erreurs. GPT-5.4, lui, voit plus vite la sur-ingénierie et propose des approches plus simples. Ils se complètent très bien dans leurs angles morts.
J'ai commencé à faire ça pour tout plan d'implémentation un peu sérieux : brouillon dans un outil, review dans l'autre, révision, review à nouveau. Deux ou trois tours. Le plan final est plus serré, plus robuste, et détecte des problèmes qu'aucun des deux modèles n'aurait fait remonter seul.
Si tu n'utilises qu'un seul outil de AI coding, tu laisses de la qualité sur la table. Pas parce qu'un des deux serait mauvais — les deux sont réellement excellents — mais parce qu'ils raisonnent différemment, et que ce raisonnement différent attrape des problèmes différents.
Que se passe-t-il quand un outil tombe ?
Le 11 mars, Claude Code a connu des erreurs élevées — problèmes de login, lenteurs, pannes intermittentes. Pendant plusieurs heures, il était de fait inutilisable.
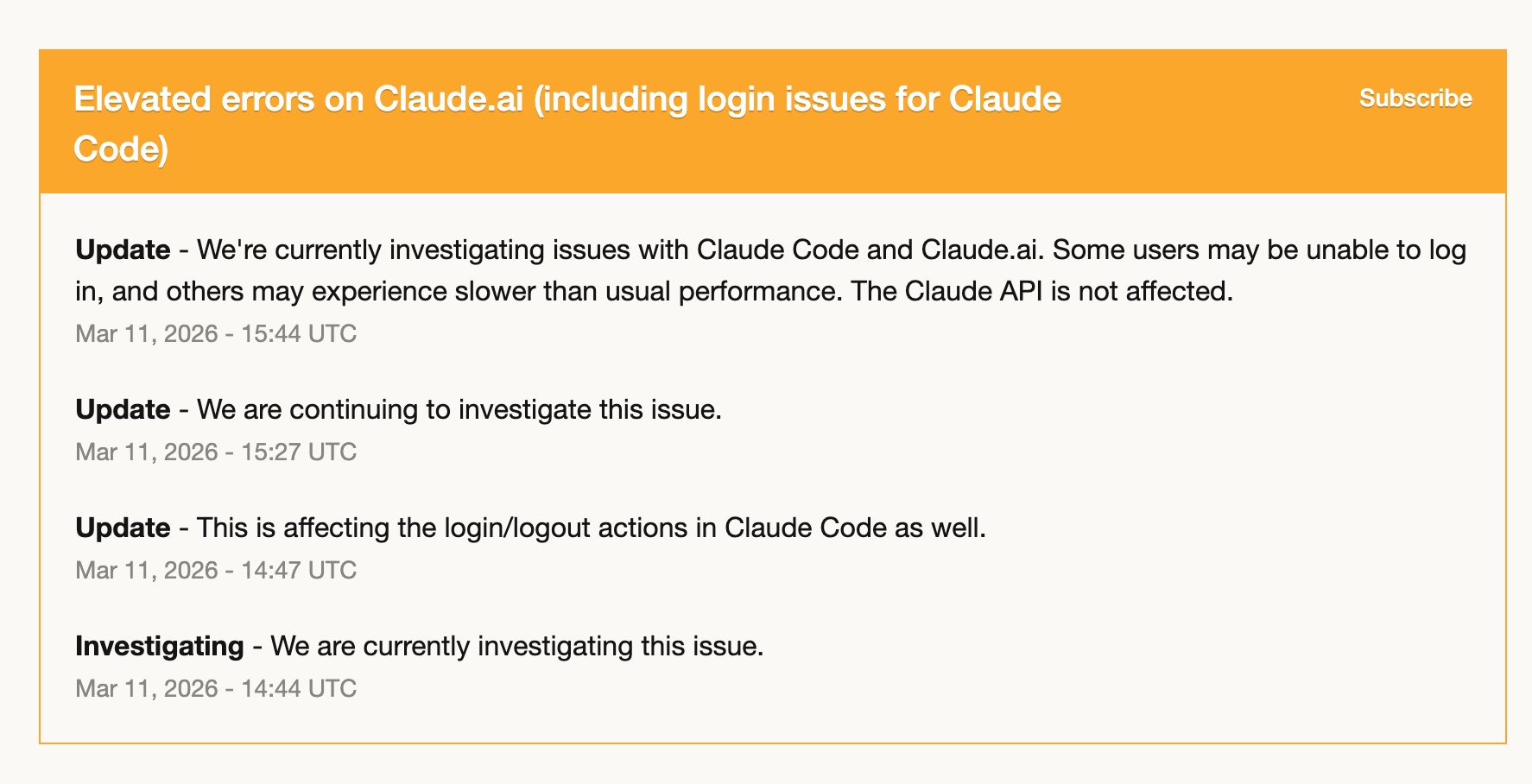
Comme j'avais déjà commencé à monter en puissance avec Codex, j'ai presque tout basculé dessus. Et ça s'est très bien passé. J'avais déjà mes skills Codex en place, mes workflows traduits, et GPT-5.4 a pris le relais sans problème.
Cette expérience m'a cristallisé quelque chose : dépendre entièrement d'un seul outil est un risque. Non pas parce que l'outil serait peu fiable — Claude Code a été remarquablement stable pendant l'année où je l'ai utilisé — mais parce que n'importe quel service peut connaître une mauvaise journée. Avoir un deuxième outil avec lequel on est réellement à l'aise n'est pas un luxe. C'est de la résilience opérationnelle.
Face à face : Claude Code vs Codex, en un coup d'œil
| Dimension | Claude Code (Opus 4.6) | Codex (GPT-5.4) |
|---|---|---|
| Qualité d'exécution | Plus profonde — identifie les manques et priorise | Bonne — exécute, mais analyse moins spontanément |
| QA automatique | Intégré, envoie des agents de review automatiquement | Pas encore — vérification manuelle nécessaire |
| Agents parallèles | Mature — 5 à 6 agents coordonnés | Prometteur — marche, mais moins fluide |
| Raisonnement architectural | Solide en medium thinking | Excellent en high thinking — reframe plus vite |
| Exécution soutenue de plans | Bonne | Impressionnante — plus de 46 minutes d'affilée |
| Compactage du contexte | Plus lent | Plus rapide — différent, pas forcément meilleur |
| Localisation à grande échelle | À niveau égal (Opus 4.6 medium) | À niveau égal — actuellement moins cher |
| Écosystème de plugins/skills | Mature (Superpowers, /feature-dev, etc.) | En croissance — peut adapter les workflows Claude |
| Revue croisée entre modèles | Repère edge cases et incohérences | Repère sur-ingénierie et simplifie |
| Coût | 100 à 200 $/mois | Promo d'un mois gratuit, puis TBD |
Quelques observations supplémentaires
Gestion du contexte : Codex semble compacter le contexte plus vite une fois la fenêtre remplie. Je n'ai pas encore décidé si c'est mieux ou pire — c'est simplement assez différent de la manière dont Claude Code le gère.
Localisation à grande échelle : j'ai traduit 3,9 millions de mots en 12 langues avec Claude Code et Opus 4.6. La qualité de traduction de GPT-5.4 est au niveau d'Opus 4.6 en medium thinking — et, pour l'instant, ça me coûte moins cher à grande échelle. Du coup, j'ai commencé à déplacer mon gros travail de localisation vers GPT-5.4. Je ne sais pas combien de temps cet avantage de coût durera, mais tant qu'il existe, autant en profiter.
Coût : je suis sur le plan Max de Claude Code à 200 $/mois. Maintenant que Codex prend une part significative de ma charge — surtout la localisation — j'envisage de redescendre au niveau 100 $. Le mois gratuit d'OpenAI aide pour la transition, mais même au plein tarif, répartir la charge entre deux outils sur des plans plus bas peut être plus rentable que pousser un seul outil au maximum.
Où j'en suis aujourd'hui
Après une vraie semaine de dual-wielding, voilà mon modèle de travail actuel :
Sors Claude Code quand : tu as besoin de qualité d'exécution avec QA intégré, d'orchestration complexe de multiples agents, de cohérence sur de longues sessions dans de grandes codebases, ou que tu travailles dans un projet où le workflow Superpowers est déjà en place.
Sors Codex quand : tu as besoin d'un regard architectural neuf, que tu veux activer le high thinking sur un problème de raisonnement difficile, que tu exécutes un plan bien défini qui profite d'un travail soutenu sans interruption, ou que Claude Code traverse une mauvaise journée.
Utilise les deux pour : tout plan d'implémentation un peu sérieux. Rédige dans l'un, relis dans l'autre. La boucle de revue croisée entre modèles est, honnêtement, le meilleur workflow que j'ai trouvé jusqu'ici.
Je n'abandonne pas Claude Code — ça reste mon outil principal et l'écosystème que je connais le mieux. Mais je ne suis plus un développeur mono-outil. GPT-5.4 a gagné sa place dans mon workflow par sa capacité réelle, pas simplement comme solution de secours.
L'avenir du développement assisté par l'IA ne consiste pas à désigner un gagnant. Il consiste à savoir quand sortir quel outil et — plus important encore — à comprendre que les outils sont meilleurs ensemble que séparément.
Questions fréquentes
GPT-5.4 est-il meilleur qu'Opus 4.6 pour coder ?
Aucun des deux n'est strictement meilleur. GPT-5.4 en high thinking excelle en raisonnement architectural et en exécution soutenue de plans. Opus 4.6 excelle en qualité d'exécution, en analyse proactive des manques et en cohérence sur les longues sessions. Les meilleurs résultats arrivent quand on utilise les deux modèles pour relire le travail l'un de l'autre.
Faut-il basculer complètement de Claude Code à Codex ?
Je ne recommanderais pas un switch complet. Les deux outils ont des forces distinctes — le QA automatique et l'orchestration d'agents parallèles de Claude Code sont réellement en avance, tandis que l'exécution soutenue de Codex et le raisonnement de GPT-5.4 sur les problèmes difficiles sont impressionnants. L'approche dual-wielding donne le meilleur des deux.
Est-ce que le workflow de revue croisée entre modèles vaut l'effort supplémentaire ?
Pour les plans non triviaux, absolument. Faire relire la sortie de GPT-5.4 par Opus, puis l'inverse, attrape des catégories différentes de problèmes — Opus repère les edge cases et les incohérences, GPT-5.4 détecte la sur-ingénierie. Deux ou trois tours produisent des plans nettement plus solides que ceux d'un modèle seul.
Combien coûte une configuration à deux outils ?
Claude Code coûte entre 100 et 200 $ par mois selon le plan. Le pricing de Codex varie — OpenAI propose actuellement un mois gratuit. Même au plein tarif, répartir la charge entre deux outils sur des plans inférieurs peut coûter moins cher que de pousser un seul outil au maximum.
Peut-on utiliser les plugins de Claude Code dans Codex ?
Pas directement, mais on peut les adapter. J'ai utilisé Codex pour inspecter les workflows de plugins Claude Code (/feature-dev, /code-review, /superpowers) et traduire leur logique centrale en skills Codex dans ~/.codex/skills. Certaines fonctions propres à Claude, comme les hooks, ne se transposent pas, mais les workflows, eux, oui.
C'est tout pour moi. Je suis curieux — est-ce que d'autres travaillent déjà en workflow multi-modèle ? Avec Claude Code et Codex ensemble, ou avec d'autres combinaisons ? Quels patterns voyez-vous émerger ?
À bientôt, Chandler





