Codex और GPT-5.4 vs Claude Code और Opus 4.6 — अब मैं दोनों क्यों इस्तेमाल करता हूँ
लगभग एक साल तक रोज़ Claude Code with Opus 4.6 इस्तेमाल करने के बाद मैंने एक हफ़्ता Codex और GPT-5.4 के साथ बिताया। निष्कर्ष: कोई एक tool साफ़ तौर पर नहीं जीतता। Cross-model review, complementary strengths और operational resilience वाली combination — दोनों में से किसी एक tool से बेहतर है।
लगभग एक साल तक रोज़ Claude Code इस्तेमाल करने के बाद मैंने एक हफ़्ता Codex और GPT-5.4 के साथ बिताया। कोई एक tool साफ़ तौर पर नहीं जीतता — लेकिन दोनों को साथ चलाने पर, cross-model review के साथ, results किसी एक tool से बेहतर आते हैं। यह है जो मैंने देखा — एक ऐसे इंसान की नज़र से जिसने दोनों के साथ real products ship किए हैं।
मैंने Claude Code with Opus 4.6 को लगभग हर चीज़ के लिए अपना primary development tool बनाया था: इस site को rebuild करना, DIALØGUE को App Store तक पहुँचाना, STRAŦUM build करना, 12 भाषाओं में 39 लाख शब्द translate करना, और 18 layout types व word-level audio sync वाली पूरी course video pipeline तैयार करना।
तो जब OpenAI ने 5 मार्च को GPT-5.4 with Codex launch किया, मैं replacement नहीं ढूँढ रहा था। मैं बस curious था। ऊपर से OpenAI free month promo भी चला रहा था, तो बिना commitment के dive in करना आसान था।
मैं pleasantly surprised हुआ। सच कहूँ तो सिर्फ pleasantly surprised नहीं — Codex with GPT-5.4 कुछ जगह genuinely उतना सक्षम निकला जितना मैंने expect नहीं किया था।
एक हफ़्ते बाद, मैं switch नहीं कर रहा। मैं dual-wielding कर रहा हूँ। और मुझे लगता है कि यह combination किसी एक tool से बेहतर है।
Harness और Model का फ़र्क़ इतना important क्यों है?
Specifics में जाने से पहले, एक nuance है जो मुझे लगता है ज़्यादातर comparisons miss कर देते हैं।
Claude Code और Codex harnesses हैं — CLI tools, agent orchestration, plugin ecosystems, context management, और वो तरीक़ा जिससे ये आपके filesystem और terminal के साथ काम करते हैं। Opus 4.6 और GPT-5.4 underlying models हैं — वही intelligence जो असल में decide करती है क्या करना है, problem के बारे में कैसे सोचना है, और कौन सा code लिखना है।
यह distinction इसलिए matter करती है क्योंकि मेरी कुछ observations harness के बारे में हैं और कुछ model के बारे में। Claude Code का automatic QA dispatch और parallel agent management? वो harness है। GPT-5.4 की मेरे fragment sync problem पर architectural insight? वो model है। जब मैं कहता हूँ कि cross-model review बेहतर plans देता है, तो मेरा point यह है कि models अलग तरह से reason करते हैं — harness बस output delivery layer है।
एक बेहतर model अगर कमजोर harness में हो तो भी frustrating लग सकता है। और एक polished harness अगर weaker model के साथ हो, तो smooth लगेगा लेकिन shallow रह सकता है। अभी दोनों combinations strong हैं — बस अलग-अलग तरीक़े से।
Codex with GPT-5.4 को पहली बार इस्तेमाल करना कैसा लगा?
मैं honestly कहूँ तो मुझे लगा था Codex शायद एक step down लगेगा। मैं Claude Code के ecosystem में काफ़ी deep हूँ: structured planning के लिए Superpowers plugin, parallel agent dispatching, और code review agents जो implementation के बाद अपने-आप run होते हैं। यह एक mature workflow है।
Codex with GPT-5.4 surprisingly competitive लगा। Model strong है। Reasoning solid है। Plans को अच्छे से follow करता है। जब मैंने इसे एक साफ़, well-structured implementation plan दिया, तो यह 45+ minutes तक बिना thread खोए लगातार काम कर सकता था — commit करना, test करना, push करना, फिर अगले step पर जाना।
मैंने Codex की कुछ experimental features भी जल्दी enable कर दीं:
- Multi-agents — parallel task execution, कुछ-कुछ Claude Code के agent dispatching जैसा
- JavaScript REPL — inline debugging के लिए persistent Node-backed runtime
- Prevent sleep while running — लंबी sessions में machine को awake रखता है
इनका फर्क़ महसूस हुआ। खासकर multi-agent support ने यह एहसास दिया कि Codex उस workflow तक पहुँच रहा है जिस पर मैं Claude Code में depend करने लगा था।
GPT-5.4 ने Opus 4.6 को कहाँ beat किया?
मुझे मानना पड़ेगा — एक area था जहाँ GPT-5.4 ने Opus 4.6 को साफ़ तौर पर पीछे छोड़ा। और यह कोई छोटी बात नहीं थी।
मैं एक course video pipeline बना रहा हूँ जो slide fragments को narrated audio के साथ sync करती है। मुश्किल हिस्सा timing नहीं है — ElevenLabs word-level timestamps दे देता है। मुश्किल हिस्सा alignment है: speaker जब किसी बात को बोलना शुरू करे, उस moment पर कौन सा on-screen fragment दिखना चाहिए।
Speaker notes अक्सर slide text को verbatim repeat नहीं करते। कभी narration किसी bullet को paraphrase करती है, कभी दो bullets को एक thought में merge कर देती है, कभी slide पर कोई bullet होती है लेकिन spoken form में वह properly आती ही नहीं। इसलिए system keywords से guess करता रहता है — जो काफ़ी बार promising लगता है, लेकिन harder slides पर टूट जाता है।
Opus 4.6 on medium thinking इस problem के साथ कई sessions तक struggle करता रहा। यह बार-बार और clever heuristics बनाता रहा — text length के हिसाब से equal splits, timestamps में keyword search, sentence-level matching, dual-strategy matching — हर बार थोड़ा बेहतर, लेकिन fundamentally still limited।
GPT-5.4 on high thinking ने architectural issue पकड़ लिया: इसे keyword-matching problem की तरह treat ही नहीं करना चाहिए। इसे data model problem की तरह treat करना चाहिए। Renderer को actual fragment states emit करने चाहिए, assembler को narration को उन्हीं states के साथ align करना चाहिए, और validation को उन slides को flag करना चाहिए जहाँ visual structure और narration match नहीं करते।
वही सही insight थी। "Text से sync guess करो" से "sync को pipeline का explicit first-class हिस्सा बनाओ" वाली shift — problem को यही architectural reframe चाहिए था। और GPT-5.4 वहाँ Opus से तेज़ पहुँचा।
Claude Code अब भी कहाँ जीतता है?
लेकिन यहाँ बात यह है — architectural insight और execution quality एक ही चीज़ नहीं हैं।
निष्पादन की गुणवत्ता
सबसे साफ़ example: मैंने दोनों tools से कहा कि वे सात course modules में companion notes को audit करें और improve करें। Codex वापस आया और बोला, काम हो गया।
Claude Code वापस आया और उसने यह दिया:
Audit Complete — All 7 Modules
Tier 1: Fix the 15 existing thin companion notes (bring them up to standard — quick win)
Tier 2: Add companion notes to ~25-30 high-priority slides (core frameworks, tool lists, multi-step processes, dense stats)
यह "done" नहीं है। यह एक structured gap analysis है जो 40-45 slides को identify कर रही है, priority tiers में। "मैंने task complete कर दिया" और "मैंने task complete किया और यह भी पाया" — इन दोनों के बीच फर्क़ बहुत बड़ा है, खासकर जब आप real product ship कर रहे हों।
स्वचालित QA
यह Claude Code का killer feature है, और मुझे नहीं लगता लोग इसके बारे में काफ़ी बात करते हैं। किसी implementation chunk के बाद Claude Code automatically QA agents dispatch कर देता है — code review, narrative review, consistency checks — बिना मेरे कहे। यह Claude Code के अंदर built-in है।
Codex अभी यह नहीं करता। जब Codex कहता है "done", तो आपको manually verify करना पड़ता है या अपना अलग review process बनाना पड़ता है। Claude Code में verification workflow का हिस्सा है। Brilliant.
समानांतर agent प्रबंधन
Claude Code की agent orchestration ज़्यादा mature है। यह multiple specialized agents dispatch करता है, उनके results manage करता है, findings synthesize करता है, और एक coherent summary देता है। मेरी 5-6 agents वाली sessions हुई हैं — explorer, code reviewer, implementation agent, test runner — सब coordinated।
Codex का multi-agent support promising है, लेकिन अभी earlier stage में है। यह काम करता है, लेकिन coordination अभी उतनी seamless नहीं लगती।
एकरूपता
लंबी sessions में जहाँ बहुत सारे moving parts हों — जैसे 7 modules और 18 layout types वाले slides बनाना — Claude Code consistency बेहतर बनाए रखता है। Design tokens सही रहते हैं, naming conventions नहीं टूटतीं, और first hour की architectural decisions fourth hour तक survive करती हैं।
क्या आप workflows को दोनों tools के बीच cross-pollinate कर सकते हैं?
एक workflow जिसकी मैंने उम्मीद नहीं की थी: Codex से Claude Code के plugin ecosystem को inspect करवाना, और उसी logic को Codex में adapt करना।
मुझे Claude Code के कुछ plugins बहुत पसंद हैं: feature development workflow (/feature-dev), code review system (/code-review), code simplifier (/code-simplifier), Superpowers planning framework (/superpowers), और frontend design skill (/frontend-design)। ये अच्छी तरह designed workflows हैं जो best practices को सीधे tool के अंदर encode करते हैं।
तो मैंने Codex से कहा कि इनको study करे और equivalent Codex skills बनाए:
"I'm writing user-level Codex skills under
~/.codex/skills, using the Claude plugin workflows as the template and adapting them to Codex's skill model where Claude-only features like hooks or plugin commands don't exist."
यह काम कर गया। Perfectly नहीं — Claude Code की कुछ concepts का direct Codex equivalent नहीं है — लेकिन core workflows अच्छी तरह translate हो गए। अब मेरे पास दोनों tools में structured development processes हैं, और दोनों एक जैसी design philosophy से informed हैं।
जब दोनों models एक-दूसरे के plans review करते हैं तब क्या होता है?
मुझे लगता है यह इस हफ़्ते की सबसे valuable discovery है।
अगर Opus 4.6, GPT-5.4 के plan को critically review करे, और फिर GPT-5.4, Opus के revised plan को review करे — और यह back-and-forth दो-तीन rounds चले — तो result किसी एक model के अकेले काम करने से काफ़ी बेहतर निकलता है।
दोनों अलग तरह की weaknesses पकड़ते हैं। Opus अक्सर architectural inconsistencies और error handling वाले edge cases पकड़ता है। GPT-5.4 over-engineering पकड़ता है और simpler approaches suggest करता है। दोनों एक-दूसरे के blind spots complement करते हैं।
मैं अब यह किसी भी non-trivial implementation plan के लिए करने लगा हूँ: draft एक tool में, review दूसरे में, revise, फिर review। दो या तीन rounds। Final plan tighter होता है, ज़्यादा robust होता है, और उन issues को पकड़ता है जो कोई एक model अकेला surface नहीं करता।
अगर आप सिर्फ़ एक AI coding tool इस्तेमाल कर रहे हैं, तो आप quality table पर छोड़ रहे हैं। इसलिए नहीं कि कोई एक tool खराब है — दोनों genuinely strong हैं — बल्कि इसलिए कि दोनों अलग तरह से reason करते हैं। और अलग reasoning अलग problems पकड़ती है।
जब एक tool नीचे चला जाए तो क्या होता है?
11 मार्च को Claude Code में elevated errors थे — login issues, slow performance, intermittent failures। कई घंटों तक यह effectively unusable था।
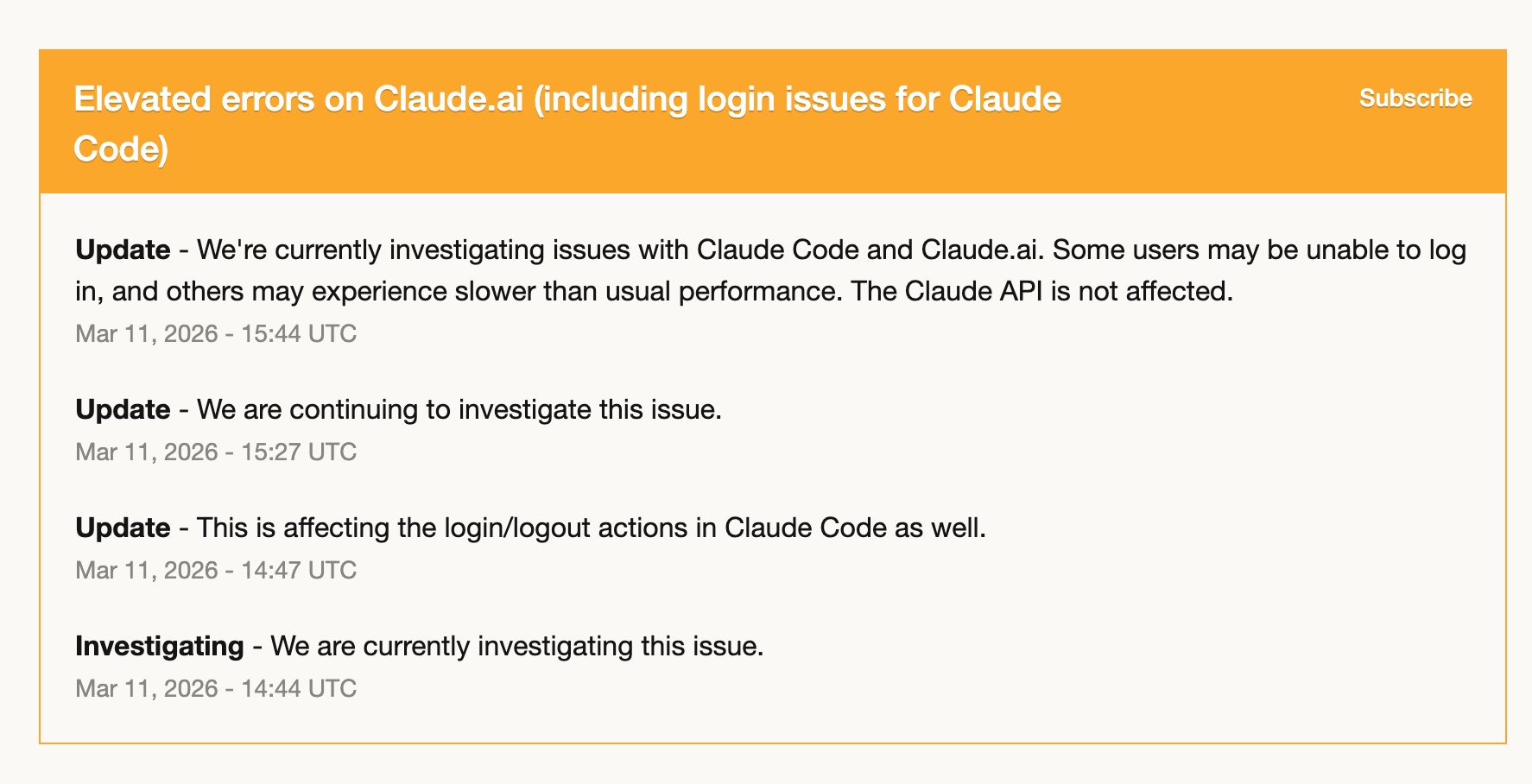
क्योंकि मैं तब तक Codex के साथ ramp up कर चुका था, मैं लगभग पूरा switch वहीं कर पाया। और मैं ठीक था। मेरे Codex skills ready थे, workflows translate हो चुके थे, और GPT-5.4 काम संभाल रहा था।
उस experience ने मेरे लिए एक बात crystal clear कर दी: पूरी तरह एक ही tool पर depend करना risk है। इसलिए नहीं कि tool unreliable है — Claude Code मेरे इस्तेमाल के पूरे साल में remarkably stable रहा है — बल्कि इसलिए कि कोई भी service कभी भी खराब दिन से गुजर सकती है। एक दूसरा tool, जिसमें आप genuinely comfortable हों, luxury नहीं है। वह operational resilience है।
एक नज़र में: Claude Code vs. Codex
| Dimension | Claude Code (Opus 4.6) | Codex (GPT-5.4) |
|---|---|---|
| Execution quality | Deeper — gaps ढूँढता है, work prioritize करता है | Good — tasks complete करता है, कम proactive analysis |
| स्वचालित QA | Built-in, review agents खुद dispatch करता है | अभी नहीं — manual verification ज़रूरी |
| Parallel agents | Mature — 5-6 coordinated agents | Promising — काम करता है, पर कम seamless |
| Architectural reasoning | Medium thinking पर strong | High thinking पर excellent — faster reframes |
| Sustained plan execution | Good | Impressive — 46+ minutes continuous |
| Context compaction | Slower | Faster — अलग, ज़रूरी नहीं बेहतर |
| Localization at scale | On par (Opus 4.6 medium) | On par — अभी cheaper |
| Plugin/skill ecosystem | Mature (Superpowers, /feature-dev, etc.) | Growing — Claude workflows adapt हो सकते हैं |
| Cross-model review | Edge cases, inconsistencies पकड़ता है | Over-engineering पकड़ता है, simplify करता है |
| Cost | $100-200/month | Free month promo, फिर TBD |
कुछ और टिप्पणियाँ
Context management: Codex context window भरने के बाद context को तेज़ी से compact करता हुआ लगता है। अभी तक मैं तय नहीं कर पाया कि यह better है या worse — लेकिन Claude Code से noticeably अलग है।
Localization at scale: मैंने Claude Code with Opus 4.6 से 12 भाषाओं में 39 लाख शब्द translate किए। GPT-5.4 की translation quality Opus 4.6 medium thinking के बराबर लगती है — और अभी bulk scale पर run करना मेरे लिए सस्ता पड़ रहा है। इसलिए मैं अपनी bulk localization work का कुछ हिस्सा GPT-5.4 पर shift कर रहा हूँ। यह cost advantage कब तक रहेगा, पता नहीं। लेकिन जब तक है, इसका इस्तेमाल करना sensible लगता है।
Cost: मैं Claude Code के $200/month Max plan पर हूँ। अब जब Codex मेरे workload का meaningful हिस्सा संभाल रहा है — खासकर localization — तो मैं $100 tier पर नीचे जाने का सोच रहा हूँ। OpenAI का free month transition को आसान बनाता है। लेकिन full price पर भी, काम को दो tools में split करना शायद एक ही tool को max करने से ज़्यादा cost-effective हो सकता है।
मैं कहाँ पहुँचा हूँ
एक हफ़्ते की genuine dual-wielding के बाद, मेरा working model यह है:
Claude Code तब उठाओ जब तुम्हें built-in QA के साथ execution quality चाहिए, complex multi-agent orchestration चाहिए, बड़े codebase में लंबी consistency चाहिए, या तुम ऐसे project में हो जहाँ Superpowers workflow पहले से set up है।
Codex तब उठाओ जब तुम्हें fresh architectural perspective चाहिए, किसी hard reasoning problem पर high-thinking mode चाहिए, किसी clear plan को sustained uninterrupted execution के साथ चलवाना है, या Claude Code का खराब दिन चल रहा है।
दोनों का साथ इस्तेमाल करो जब implementation plan non-trivial हो। Draft एक में, review दूसरे में। यह cross-model review loop genuinely सबसे अच्छा workflow है जो मैंने अब तक पाया है।
मैं Claude Code छोड़ नहीं रहा — यह अभी भी मेरा primary tool है और वही ecosystem है जिसे मैं सबसे अच्छे से जानता हूँ। लेकिन अब मैं single-tool developer नहीं हूँ। GPT-5.4 ने मेरे workflow में अपनी जगह capability से कमाई है, सिर्फ़ backup बनकर नहीं।
AI-assisted development का future मेरे लिए winner pick करना नहीं है। Future यह जानना है कि किस moment पर कौन सा tool उठाना है — और उससे भी ज़्यादा important, यह समझना कि tools साथ में अलग-अलग से बेहतर हैं।
अक्सर पूछे जाने वाले सवाल
क्या GPT-5.4 coding के लिए Opus 4.6 से बेहतर है?
कोई भी strictly बेहतर नहीं है। GPT-5.4 on high thinking architectural reasoning और sustained plan execution में strong है। Opus 4.6 execution quality, proactive gap analysis और long-session consistency में strong है। Best results तब आते हैं जब दोनों models एक-दूसरे के काम को review करते हैं।
क्या मुझे Claude Code छोड़कर Codex पर switch कर लेना चाहिए?
मैं full switch recommend नहीं करूँगा। दोनों tools की अलग strengths हैं — Claude Code का automatic QA और parallel agent orchestration genuinely आगे है, जबकि Codex का sustained execution और hard problems पर GPT-5.4 की reasoning impressive है। Dual-wielding approach आपको दोनों दुनिया का best देता है।
क्या cross-model review वाला workflow extra effort के लायक़ है?
Non-trivial plans के लिए, बिल्कुल। जब Opus GPT-5.4 को review करता है और vice versa, तो अलग categories की problems सामने आती हैं — Opus edge cases और inconsistencies पकड़ता है, GPT-5.4 over-engineering पकड़ता है। दो या तीन rounds noticeably tighter plans देते हैं।
दो tools वाले setup की cost कितनी पड़ती है?
Claude Code $100-200/month के बीच है, plan पर depend करता है। Codex pricing अलग है — OpenAI अभी free month promo दे रहा है। Full price पर भी, workload को lower tiers पर दो tools में split करना एक ही tool को max करने से सस्ता पड़ सकता है।
क्या Claude Code plugins को Codex में use किया जा सकता है?
Directly नहीं, लेकिन adapt किया जा सकता है। मैंने Codex से Claude Code plugin workflows (/feature-dev, /code-review, /superpowers) inspect करवाए और core logic को ~/.codex/skills के अंदर Codex skills में translate किया। Claude-specific चीज़ें जैसे hooks direct translate नहीं होतीं, लेकिन workflows हो जाते हैं।
बस इतना ही। मैं genuinely curious हूँ — क्या और लोग भी multi-model workflows चला रहे हैं? Claude Code और Codex साथ में, या कोई और combination? तुम्हें कौन से patterns दिख रहे हैं?
शुक्रिया, Chandler





