Codex dengan GPT-5.4 vs Claude Code dengan Opus 4.6 — Kenapa Sekarang Saya Pakai Keduanya
Setelah hampir setahun memakai Claude Code dengan Opus 4.6 setiap hari, saya menghabiskan seminggu dengan Codex dan GPT-5.4. Kesimpulannya: tidak ada tool yang menang telak. Kombinasi cross-model review, kekuatan yang saling melengkapi, dan ketahanan operasional ternyata lebih baik daripada salah satu tool dipakai sendirian.
Setelah hampir setahun memakai Claude Code setiap hari, saya menghabiskan seminggu dengan Codex dan GPT-5.4. Tidak ada tool yang menang telak — tapi kalau keduanya dipakai bersama, dengan cross-model review, hasilnya lebih baik daripada masing-masing dipakai sendirian. Inilah yang saya lihat, dari sudut pandang seseorang yang sudah benar-benar shipping produk dengan dua-duanya.
Saya sudah memakai Claude Code dengan Opus 4.6 sebagai tool utama untuk hampir semuanya: membangun ulang site ini, membawa DIALØGUE ke App Store, membangun STRAŦUM, menerjemahkan 3,9 juta kata ke 12 bahasa, dan membangun seluruh course video pipeline dengan 18 jenis layout plus sinkronisasi audio di level kata.
Jadi ketika OpenAI merilis GPT-5.4 dengan Codex pada 5 Maret, saya tidak sedang mencari pengganti. Saya cuma penasaran. OpenAI juga sedang menjalankan promo gratis satu bulan, jadi relatif mudah untuk masuk dan mencoba tanpa komitmen besar.
Saya cukup terkejut. Bahkan bukan cuma cukup terkejut — Codex dengan GPT-5.4 benar-benar kapabel dengan cara-cara yang tidak saya duga.
Seminggu kemudian, saya tidak pindah total. Saya dual-wield. Dan saya rasa kombinasi ini lebih baik daripada salah satu tool berdiri sendiri.
Kenapa Pembedaan Antara Harness dan Model Itu Penting?
Sebelum masuk ke detail, ada satu nuance yang menurut saya sering terlewat di banyak perbandingan.
Claude Code dan Codex adalah harness — CLI tool, orkestrasi agent, ekosistem plugin, manajemen context, dan cara mereka berinteraksi dengan filesystem serta terminal. Opus 4.6 dan GPT-5.4 adalah model di bawahnya — kecerdasan yang benar-benar mengambil keputusan soal apa yang harus dilakukan, bagaimana memikirkan sebuah masalah, dan kode seperti apa yang harus ditulis.
Ini penting karena sebagian observasi saya sebenarnya tentang harness, dan sebagian lagi tentang model. Kemampuan Claude Code untuk otomatis dispatch QA dan mengelola agent paralel? Itu harness. Insight arsitektural GPT-5.4 untuk masalah fragment sync saya? Itu model. Ketika saya bilang cross-model review menghasilkan plan yang lebih baik, saya sedang bicara tentang cara model berpikir berbeda — harness hanya menyampaikan output itu.
Model yang lebih kuat di harness yang lebih lemah tetap bisa terasa menyebalkan. Harness yang bagus dengan model yang lebih lemah bisa terasa polished tapi dangkal. Saat ini, kedua kombinasi sama-sama kuat — hanya saja kuatnya di tempat yang berbeda.
Bagaimana Kesan Pertama Saya Saat Memakai Codex dengan GPT-5.4?
Jujur saja — saya sempat mengira Codex bakal terasa seperti langkah mundur. Saya sudah sangat dalam dengan ekosistem Claude Code: plugin Superpowers untuk planning yang lebih terstruktur, agent dispatching paralel, code review agent yang otomatis jalan setelah implementasi. Workflow-nya sudah matang.
Codex dengan GPT-5.4 ternyata langsung kompetitif. Model-nya kuat. Cara berpikirnya solid. Ia mengikuti plan dengan baik. Ketika saya memberinya implementation plan yang rapi, tool ini bisa bekerja terus selama lebih dari 45 menit tanpa kehilangan arah — commit, test, push, lalu lanjut ke task berikutnya.
Saya juga mengaktifkan beberapa fitur experimental Codex sejak awal:
- Multi-agents — eksekusi task secara paralel, mirip dengan agent dispatching di Claude Code
- JavaScript REPL — runtime Node yang persistent untuk debugging inline
- Prevent sleep while running — menjaga mesin tetap bangun saat sesi kerja panjang
Fitur-fitur itu terasa bedanya. Terutama support multi-agent, yang membuat saya merasa Codex sedang mengejar jenis workflow yang selama ini sangat saya andalkan di Claude Code.
Di Mana GPT-5.4 Mengungguli Opus 4.6?
Saya harus mengakui — ada satu area di mana GPT-5.4 jelas mengalahkan Opus 4.6, dan ini bukan hal kecil.
Saya sedang membangun course video pipeline yang menyinkronkan fragment di slide dengan audio narasi. Masalah tersulitnya bukan timing — ElevenLabs sudah memberi saya word-level timestamp. Masalah tersulitnya adalah alignment: menentukan fragment mana di layar yang seharusnya muncul ketika narator mulai membicarakannya.
Speaker notes sering kali tidak mengulang teks di slide secara verbatim. Kadang narasinya memparafrase sebuah bullet. Kadang dua bullet digabung jadi satu ide. Kadang ada bullet yang muncul di slide tapi tidak pernah benar-benar disebutkan. Jadi sistem terus menebak lewat keyword. Pendekatan itu cukup sering berhasil sehingga terlihat menjanjikan, tapi pecah di slide-slide yang lebih sulit.
Opus 4.6 pada medium thinking kesulitan dengan masalah ini di beberapa sesi. Ia terus menghasilkan heuristic yang makin pintar — pembagian rata berdasarkan panjang teks, pencarian keyword di timestamp, sentence-level matching, dual-strategy matching — masing-masing sedikit lebih baik, tapi secara fundamental tetap terbatas.
GPT-5.4 pada high thinking menangkap masalah arsitekturnya: ini seharusnya tidak diperlakukan sebagai masalah keyword matching. Ini harus diperlakukan sebagai masalah data model. Renderer harus meng-emit fragment state yang benar-benar ada, assembler harus meng-align narasi ke state tersebut, dan validation harus memberi flag ke slide yang struktur visualnya tidak cocok dengan narasinya.
Itu insight yang benar. Pergeseran dari "menebak sync dari teks" ke "menjadikan sync sebagai bagian first-class yang eksplisit di pipeline" persis reframe arsitektural yang dibutuhkan masalah ini. Dan GPT-5.4 sampai ke sana lebih cepat daripada Opus.
Di Mana Claude Code Masih Menang?
Tapi ini poin pentingnya — insight arsitektural dan kualitas eksekusi sampai akhir itu bukan hal yang sama.
Kualitas Eksekusi
Contoh paling jelas: saya meminta kedua tool untuk mengaudit dan memperbaiki companion notes di tujuh modul course. Codex kembali dan bilang pekerjaannya sudah selesai.
Claude Code kembali dengan ini:
Audit Selesai — Semua 7 Modul
Tier 1: Perbaiki 15 companion notes yang masih tipis (naikkan ke standar — quick win)
Tier 2: Tambahkan companion notes untuk sekitar 25-30 slide prioritas tinggi (framework inti, daftar tool, proses multi-langkah, statistik padat)
Itu bukan sekadar "selesai". Itu gap analysis yang terstruktur, yang mengidentifikasi 40-45 slide yang perlu perhatian dan memprioritaskannya ke dalam beberapa tier. Perbedaan antara "Saya menyelesaikan task" dan "Saya menyelesaikan task dan ini temuan saya" sangat besar ketika kamu sedang benar-benar shipping produk.
QA Otomatis
Ini killer feature Claude Code, dan saya rasa orang belum cukup membicarakannya. Setelah menyelesaikan satu bagian implementasi, Claude Code otomatis dispatch QA agent — code review, narrative review, consistency check — tanpa perlu saya minta. Itu built-in di dalam Claude Code.
Codex belum punya ini. Ketika Codex bilang sudah selesai, kamu tetap harus verifikasi manual atau membangun review process sendiri. Dengan Claude Code, verifikasi itu sudah jadi bagian dari workflow. Brilliant.
Manajemen Agent Paralel
Orkestrasi agent Claude Code lebih matang. Ia dispatch banyak agent spesialis, mengelola hasilnya, mensintesis temuan, dan menyajikannya kembali sebagai summary yang koheren. Saya pernah punya sesi dengan 5-6 agent berjalan bersamaan — explorer, code reviewer, implementation agent, test runner — semuanya dikoordinasikan.
Support multi-agent di Codex menjanjikan, tapi masih lebih awal dalam perkembangannya. Ia bekerja, hanya saja koordinasinya belum se-seamless itu.
Konsistensi
Dalam sesi panjang dengan banyak moving parts — misalnya memproduksi slide di 7 modul dengan 18 jenis layout — Claude Code menjaga konsistensi lebih baik. Design token tetap benar. Naming convention tetap terjaga. Keputusan arsitektural yang diambil di jam pertama masih dihormati di jam keempat.
Bisa Tidak Workflow Kedua Tool Saling Menular?
Salah satu workflow yang tidak saya duga: memakai Codex untuk mempelajari ekosistem plugin Claude Code lalu mengadaptasinya.
Saya sangat suka beberapa plugin Claude Code: workflow pengembangan fitur (/feature-dev), sistem code review (/code-review), code simplifier (/code-simplifier), framework planning Superpowers (/superpowers), dan skill frontend design (/frontend-design). Itu workflow yang dirancang dengan baik dan mengemas best practice langsung ke dalam tool.
Jadi saya minta Codex mempelajarinya lalu membuat skill Codex yang setara:
"Saya sedang menulis user-level Codex skills di
~/.codex/skills, memakai workflow plugin Claude Code sebagai template dan mengadaptasinya ke model skill Codex di tempat-tempat di mana fitur khusus Claude seperti hooks atau plugin commands tidak ada."
Hasilnya berhasil. Tidak sempurna — ada beberapa konsep Claude Code yang tidak punya padanan langsung di Codex — tapi workflow intinya bisa diterjemahkan dengan baik. Sekarang saya punya proses pengembangan yang terstruktur di kedua tool, dibangun dari filosofi desain yang sama.
Apa yang Terjadi Saat Kedua Model Saling Mereview?
Menurut saya, ini temuan paling berharga dari minggu ini.
Kalau Opus 4.6 diminta mengkritisi plan dari GPT-5.4, lalu GPT-5.4 diminta mengkritisi plan revisi dari Opus — bolak-balik beberapa putaran — hasilnya jauh lebih baik daripada satu model bekerja sendirian.
Mereka menemukan kelemahan yang berbeda. Opus cenderung menangkap inkonsistensi arsitektur dan edge case dalam error handling. GPT-5.4 cenderung menangkap over-engineering dan menyarankan pendekatan yang lebih sederhana. Mereka saling menutup blind spot satu sama lain.
Saya mulai melakukan ini untuk setiap implementation plan yang tidak sepele: draft di satu tool, review di tool lain, revisi, review lagi. Dua atau tiga putaran. Plan akhirnya lebih rapat, lebih kuat, dan menangkap masalah yang tidak muncul ketika hanya memakai satu model.
Kalau kamu hanya memakai satu AI coding tool, menurut saya kamu sedang meninggalkan kualitas di meja. Bukan karena salah satu tool itu buruk — dua-duanya benar-benar bagus — tapi karena mereka berpikir berbeda, dan cara berpikir yang berbeda menangkap masalah yang berbeda juga.
Apa yang Terjadi Saat Salah Satu Tool Down?
Pada 11 Maret, Claude Code mengalami elevated errors — masalah login, performa lambat, kegagalan yang intermiten. Selama beberapa jam, tool itu praktis tidak bisa diandalkan.
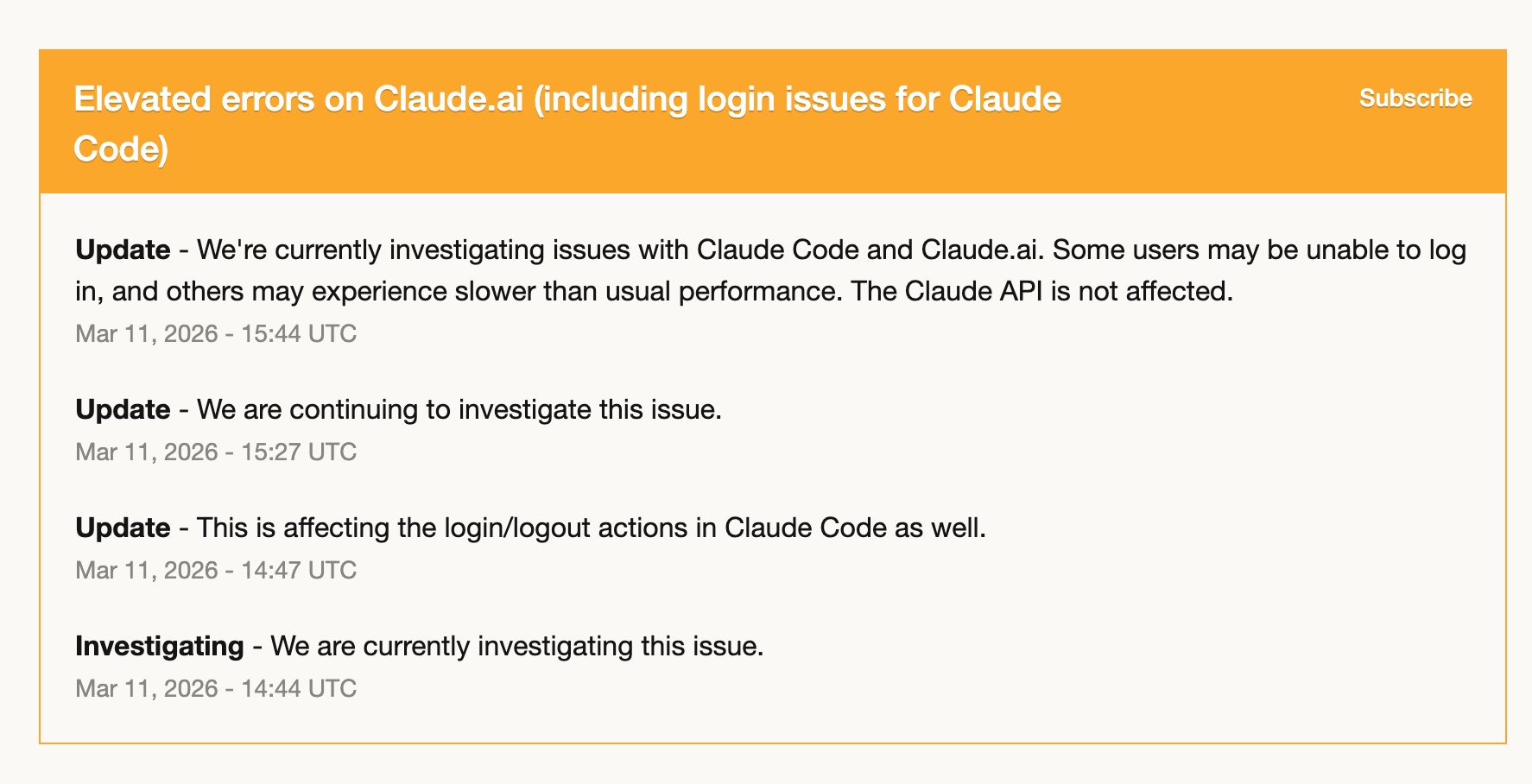
Karena saya sudah lebih dulu mulai ramping up dengan Codex, saya hampir sepenuhnya pindah ke sana. Dan saya baik-baik saja. Skill Codex saya sudah siap, workflow sudah saya adaptasi, dan GPT-5.4 menangani pekerjaannya dengan cukup baik.
Pengalaman itu mengkristalkan satu hal: bergantung sepenuhnya pada satu tool adalah risiko. Bukan karena tool itu tidak reliabel — Claude Code luar biasa stabil selama setahun saya memakainya — tapi karena layanan apa pun bisa saja mengalami hari yang buruk. Memiliki tool kedua yang benar-benar nyaman kamu pakai bukan kemewahan. Itu operational resilience.
Perbandingan Ringkas: Claude Code vs. Codex
| Dimensi | Claude Code (Opus 4.6) | Codex (GPT-5.4) |
|---|---|---|
| Kualitas eksekusi | Lebih dalam — menemukan gap, memprioritaskan pekerjaan | Bagus — menyelesaikan task, kurang proaktif menganalisis |
| QA otomatis | Built-in, otomatis dispatch review agent | Belum ada — butuh verifikasi manual |
| Agent paralel | Matang — 5-6 agent terkoordinasi | Menjanjikan — jalan, tapi belum semulus itu |
| Penalaran arsitektural | Kuat di medium thinking | Sangat bagus di high thinking — reframe lebih cepat |
| Eksekusi plan berkelanjutan | Bagus | Mengesankan — 46+ menit terus-menerus |
| Compaction context | Lebih lambat | Lebih cepat — berbeda, belum tentu lebih baik |
| Lokalisasi skala besar | Setara (Opus 4.6 medium) | Setara — saat ini lebih murah |
| Ekosistem plugin/skill | Matang (Superpowers, /feature-dev, dll.) | Bertumbuh — workflow Claude bisa diadaptasi |
| Cross-model review | Menangkap edge case, inkonsistensi | Menangkap over-engineering, menyederhanakan |
| Biaya | $100-200/bulan | Promo gratis satu bulan, lalu TBD |
Beberapa Observasi Lain
Manajemen context: Codex tampaknya memadatkan context lebih cepat setelah context window penuh. Saya belum memutuskan apakah itu lebih baik atau lebih buruk — saya hanya merasa perbedaannya cukup jelas dibanding cara Claude Code menangani hal yang sama.
Lokalisasi skala besar: Saya sudah menerjemahkan 3,9 juta kata ke 12 bahasa menggunakan Claude Code dengan Opus 4.6. Kualitas terjemahan GPT-5.4 setara dengan Opus 4.6 pada medium thinking — dan untuk sementara, lebih murah untuk saya jalankan dalam skala besar. Jadi saya mulai memindahkan bulk localization work saya ke GPT-5.4. Saya tidak tahu berapa lama keunggulan biaya itu akan bertahan, tapi selama masih ada, rasanya masuk akal untuk memakainya.
Biaya: Saya sedang memakai paket Max $200/bulan dari Claude Code. Karena sekarang Codex menangani porsi workload yang berarti — terutama lokalisasi — saya sedang mempertimbangkan turun ke tier $100. Bulan gratis dari OpenAI membantu transisi ini, tapi bahkan di harga penuh, membagi pekerjaan ke dua tool pada tier yang lebih rendah mungkin tetap lebih hemat daripada memaksimalkan satu tool saja.
Di Mana Posisi Saya Sekarang
Setelah seminggu benar-benar dual-wielding, ini working model saya:
Pakai Claude Code ketika: kamu butuh kualitas eksekusi dengan QA bawaan, orkestrasi multi-agent yang rumit, konsistensi jangka panjang di codebase besar, atau kamu sedang bekerja di project yang workflow Superpowers-nya sudah siap.
Pakai Codex ketika: kamu butuh perspektif arsitektur yang fresh, ingin high-thinking mode untuk masalah reasoning yang sulit, sedang mengeksekusi plan yang sudah jelas dan diuntungkan oleh kerja panjang tanpa putus, atau Claude Code sedang mengalami hari yang buruk.
Pakai keduanya untuk: implementation plan apa pun yang tidak sepele. Draft di satu tool, review di tool lain. Loop cross-model review ini sungguh workflow terbaik yang saya temukan sejauh ini.
Saya tidak meninggalkan Claude Code — ia tetap tool utama saya dan ekosistem yang paling saya kenal. Tapi sekarang saya juga bukan lagi developer satu-tool. GPT-5.4 sudah mendapatkan tempatnya di workflow saya lewat kapabilitas nyata, bukan sekadar sebagai backup.
Masa depan AI-assisted development bukan soal memilih siapa pemenangnya. Masalahnya adalah tahu kapan harus meraih tool yang mana, dan — yang lebih penting — tahu bahwa tool-tool ini bekerja lebih baik saat dipakai bersama daripada dipisah.
Pertanyaan yang Sering Muncul
Apakah GPT-5.4 lebih baik daripada Opus 4.6 untuk coding?
Tidak ada yang lebih baik secara mutlak. GPT-5.4 pada high thinking unggul untuk reasoning arsitektural dan eksekusi plan yang berkelanjutan. Opus 4.6 unggul untuk kualitas eksekusi, gap analysis yang proaktif, dan konsistensi selama sesi panjang. Hasil terbaik datang saat kedua model saling mereview pekerjaan masing-masing.
Apakah saya harus pindah dari Claude Code ke Codex?
Saya tidak akan menyarankan pindah total. Kedua tool punya kekuatan yang berbeda — QA otomatis dan orkestrasi agent paralel milik Claude Code benar-benar lebih maju, sementara sustained execution Codex dan reasoning GPT-5.4 pada masalah sulit juga sangat mengesankan. Pendekatan dual-wield memberi kamu yang terbaik dari keduanya.
Apakah workflow cross-model review sepadan dengan usaha tambahannya?
Untuk plan yang tidak sepele, jelas iya. Ketika Opus mereview output GPT-5.4 dan sebaliknya, mereka menangkap kategori masalah yang berbeda — Opus menemukan edge case dan inkonsistensi, GPT-5.4 menangkap over-engineering. Dua atau tiga putaran menghasilkan plan yang terasa jauh lebih rapat daripada memakai satu model saja.
Berapa biaya setup dual-tool?
Claude Code ada di kisaran $100-200/bulan tergantung paket. Harga Codex masih berubah — OpenAI saat ini sedang menawarkan promo gratis satu bulan. Bahkan di harga penuh, membagi workload ke dua tool pada tier yang lebih rendah bisa lebih hemat daripada memaksimalkan satu tool saja.
Bisa tidak plugin Claude Code dipakai di Codex?
Tidak secara langsung, tapi bisa diadaptasi. Saya memakai Codex untuk mempelajari workflow plugin Claude Code (/feature-dev, /code-review, /superpowers) lalu menerjemahkan logika intinya menjadi skill Codex di ~/.codex/skills. Beberapa fitur yang khusus Claude, seperti hooks, memang tidak bisa diterjemahkan, tapi workflow-nya bisa.
Itu dulu dari saya. Saya penasaran — adakah orang lain yang juga menjalankan workflow multi-model? Memakai Claude Code dan Codex bareng, atau kombinasi lain? Pola apa yang kalian temukan?
Salam, Chandler





