CodexとGPT-5.4 vs Claude CodeとOpus 4.6 — なぜ今は両方を使っているのか
ほぼ1年間、毎日 Claude Code と Opus 4.6 を使ってきたあとで、Codex と GPT-5.4 を1週間試してみた。結論は、どちらか一方が勝つわけではないということだ。クロスモデルレビュー、補完し合う強み、そして運用面のレジリエンスまで含めると、組み合わせた方が単独より強い。
ほぼ1年間、毎日 Claude Code を使ってきたあとで、Codex と GPT-5.4 を1週間試してみた。どちらか一方が完全勝利、という話ではなかった。むしろ、両方を使ってクロスモデルレビューを回した方が、単独より明らかに良い結果が出る。 実際に両方でプロダクトを出してきた立場から、ぼくが感じたことを書いてみます。
この1年近く、ぼくは Claude Code と Opus 4.6 を、ほぼすべての開発作業のメインツールとして使ってきました。このサイトの再構築、DIALØGUE(ダイアログ)を App Store に出すこと、STRAŦUM(ストラタム)の構築、12言語で390万語を翻訳したこと、それに18種類のレイアウトと単語レベルの音声同期を持つコース動画パイプラインの制作まで、全部です。
だから OpenAI が 3月5日に Codex と GPT-5.4 を発表したときも、乗り換え先を探していたわけではありません。ただ純粋に気になったんです。しかも OpenAI が無料1か月プロモーションをやっていたので、気軽に深く試せました。
正直、かなり驚きました。いや、「かなり」では足りないかもしれません。Codex と GPT-5.4 は、ぼくが想像していた以上にちゃんと戦えるツールでした。
1週間たって、ぼくは乗り換えていません。でも今は一本足打法でもない。両刀使いです。そして今のところ、その方が明らかに強いと感じています。
なぜ「ハーネス」と「モデル」を分けて考えるべきなのか
細かい話に入る前に、多くの比較で見落とされているニュアンスがあります。
Claude Code と Codex はハーネスです。CLIツールであり、エージェントのオーケストレーションであり、プラグインやスキルの仕組みであり、コンテキスト管理のやり方であり、ファイルシステムやターミナルとの付き合い方です。Opus 4.6 と GPT-5.4 は、その下で判断を下すモデルです。何をすべきか、どう考えるべきか、どんなコードを書くべきかを決めている知能の部分ですね。
これを分けて考える必要があるのは、ぼくの観察の中に「ハーネスの話」と「モデルの話」が混ざっているからです。Claude Code の自動QAディスパッチや並列エージェント管理はハーネスの強みです。GPT-5.4 がぼくのフラグメント同期問題に対して見せたアーキテクチャ視点はモデルの強みです。クロスモデルレビューで計画が良くなる、という話はまさにモデル同士の思考の違いの話であって、ハーネスはそれを届ける器にすぎません。
モデルが優秀でもハーネスが弱いと、体験としてはストレスになります。逆に、ハーネスが洗練されていてもモデルが浅いと、気持ちよく動くけれど中身が薄い、ということが起こる。 今のところ、この2つの組み合わせはどちらも強い。ただし、強さの種類が違います。
Codex と GPT-5.4 を初めて使ったときの印象
正直に言うと、最初は Codex が少し物足りなく感じるだろうと思っていました。ぼくはもう Claude Code のエコシステムにかなり深く入っています。構造化プランニングを支える Superpowers プラグイン、並列エージェントのディスパッチ、実装後に自動で走るコードレビューエージェント。ワークフローとしてかなり成熟しています。
ところが、Codex と GPT-5.4 は最初から十分に競争力がありました。モデルは強い。推論も堅い。計画にもよく従う。ちゃんと構造化した実装計画を渡すと、45分以上ほとんど流れを失わずに、コミットして、テストして、pushして、次のタスクに移る、という動きを続けられました。
早い段階でいくつかの実験的機能も有効にしました。
- Multi-agents — Claude Code のエージェントディスパッチに近い並列実行
- JavaScript REPL — インラインデバッグ用の永続 Node ランタイム
- Prevent sleep while running — 長時間セッション中にマシンを起こしておく機能
この3つは体験をかなり良くしました。とくに multi-agent は、ぼくが Claude Code で頼りきっていたワークフローに Codex がだいぶ近づいてきた感覚がありました。
GPT-5.4 が Opus 4.6 を上回ったのはどこか
ここは認めないといけません。GPT-5.4 が Opus 4.6 より明確に良かった場面が、少なくとも一つありました。しかも小さな差ではありませんでした。
ぼくは最近、コース動画パイプラインを作っています。スライドのフラグメントとナレーション音声を同期させる仕組みです。難しいのはタイミングではありません。ElevenLabs が単語レベルのタイムスタンプをくれるからです。難しいのはアラインメントです。話し手がある内容を話し始めたとき、どのフラグメントをその瞬間に画面へ出すべきかを決めることです。
スピーカーノートは、スライド上の文言をそのまま繰り返すわけではありません。箇条書きを言い換えることもあるし、2つの箇条書きを1つの文にまとめることもある。そもそもスライドにあるのにほとんど口に出されない項目もあります。だからシステムはキーワードから推測し続けるしかなくて、簡単なスライドではそれなりに見えるけれど、難しいスライドでは崩れる。
Opus 4.6 は medium thinking で何度かこの問題に向き合いましたが、だんだん巧妙になるヒューリスティックを積み上げる方向に進みました。テキスト量による等分割、タイムスタンプ内のキーワード検索、文単位マッチング、二重戦略マッチング。どれも前よりは良い。でも根本的には限界がありました。
一方で GPT-5.4 は high thinking で、この問題をそもそもキーワードマッチング問題として扱うべきではない、と見抜きました。これはデータモデルの問題だ、と。 レンダラーが実際のフラグメント状態を出力し、アセンブラーがその状態にナレーションを揃え、さらに視覚構造とナレーションがズレているスライドを検証で拾うべきだ、と。
まさにその通りでした。「テキストから同期を推測する」から「同期をパイプラインの第一級要素にする」への発想転換が必要だったんです。そして GPT-5.4 は、Opus より速くそこへ到達しました。
それでも Claude Code が勝っているところ
ただし、ここが大事です。アーキテクチャの洞察と、実行品質・詰め切る力は別物です。
実行品質
いちばんわかりやすい例があります。ぼくは両方のツールに、7つのコースモジュールにある companion notes を監査して改善してほしいと頼みました。Codex は「終わりました」と返してきました。
Claude Code はこう返してきました。
監査完了 — 全7モジュール
Tier 1: 既存の薄い companion notes 15件を基準まで引き上げる(すぐ取れる改善)
Tier 2: 優先度の高いスライド約25〜30枚に companion notes を追加する(主要フレームワーク、ツール一覧、複数ステップのプロセス、密度の高い統計)
これは「終わった」ではありません。40〜45枚のスライドに対する構造化されたギャップ分析で、しかも優先度つきです。「やりました」で終わるのと、「やりました。しかも見つかった課題はこれです」と返ってくるのとの差は、実際にプロダクトを出しているとかなり大きい。
自動QA
これは Claude Code のキラーフィーチャーだと思っています。もっと話題になっていい。ある程度の実装を終えたあと、Claude Code はぼくが指示しなくても QA エージェントを自動で走らせます。コードレビュー、ナラティブレビュー、一貫性チェック。Claude Code の中にワークフローとして組み込まれているんです。
Codex はまだそこまで来ていません。Codex が「終わった」と言ったら、自分で検証するか、自前でレビューの仕組みを作る必要があります。Claude Code では、検証がワークフローの一部になっている。ここは本当に見事です。
並列エージェント管理
Claude Code のエージェントオーケストレーションは、やはり成熟しています。複数の専門エージェントを投げて、結果を回収して、所見を統合して、まとまった形で返してくる。ぼく自身、5〜6個のエージェントが同時に動いているセッションを何度もやっています。explorer、code reviewer、implementation agent、test runner が全部並走する感じです。
Codex の multi-agent は有望です。でもまだ発展途上だと思う。動くことは動く。でも、連携のなめらかさはまだ Claude Code の方が上です。
一貫性
長時間セッションで、しかも可動部分が多い作業——たとえば7モジュール・18レイアウトをまたぐスライド制作のような作業——では、Claude Code の方が一貫性を保ちやすいです。デザイントークンが崩れにくい。命名規約も保たれやすい。最初の1時間で決めたアーキテクチャ上の前提が、4時間後にもちゃんと尊重されている。
ワークフローを相互移植できるか
今回ちょっと意外だったのは、Codex を使って Claude Code のプラグインエコシステムを観察し、それを Codex 向けに移植できたことです。
ぼくは Claude Code のプラグインの中でも、/feature-dev、/code-review、/code-simplifier、/superpowers、/frontend-design がかなり好きです。単に便利というより、良い開発の型をツール側に埋め込んでいるのがいい。
そこで Codex に、これらを調べて Codex 向けのスキルとして再設計してほしいと頼みました。
"I'm writing user-level Codex skills under
~/.codex/skills, using the Claude plugin workflows as the template and adapting them to Codex's skill model where Claude-only features like hooks or plugin commands don't exist."
結果はかなり良かった。完璧ではありません。Claude Code 特有の概念で、Codex にそのまま移せないものもある。でも、コアとなるワークフローはちゃんと翻訳できた。今は同じ設計思想をベースに、両方のツールで構造化された開発プロセスを回せています。
2つのモデルで互いをレビューさせると何が起きるか
この1週間でいちばん価値が大きかった発見は、たぶんこれです。
GPT-5.4 が書いた計画を Opus 4.6 に批判的にレビューさせ、その修正版を今度は GPT-5.4 に戻して再レビューさせる。これを2〜3往復やると、どちらか片方だけで作った計画より明らかに良くなる。
両者は違う種類の弱点を拾います。Opus はアーキテクチャ上の不整合や、エラーハンドリングのエッジケースを見つけやすい。GPT-5.4 は過剰設計を見抜いて、もっとシンプルな方針を提案してくることが多い。盲点の種類が違うんです。
ぼくは今、少しでも大きい実装計画ではこのやり方をしています。片方でドラフトし、もう片方でレビューし、直して、またレビューする。2〜3ラウンド。すると最終的な計画は締まりが良くなり、どちらか一方では出てこなかった問題まで見えるようになります。
もし今、AI コーディングツールを1つしか使っていないなら、品質面で取りこぼしているものがあると思います。どちらかが悪いからではありません。両方とも本当に優秀です。ただ、考え方が違う。違う思考は、違う問題を見つけます。
片方のツールが落ちたらどうなるか
3月11日、Claude Code でエラー増加が起きました。ログイン問題、レスポンス低下、断続的な失敗。数時間、実質的に使い物にならない状態でした。
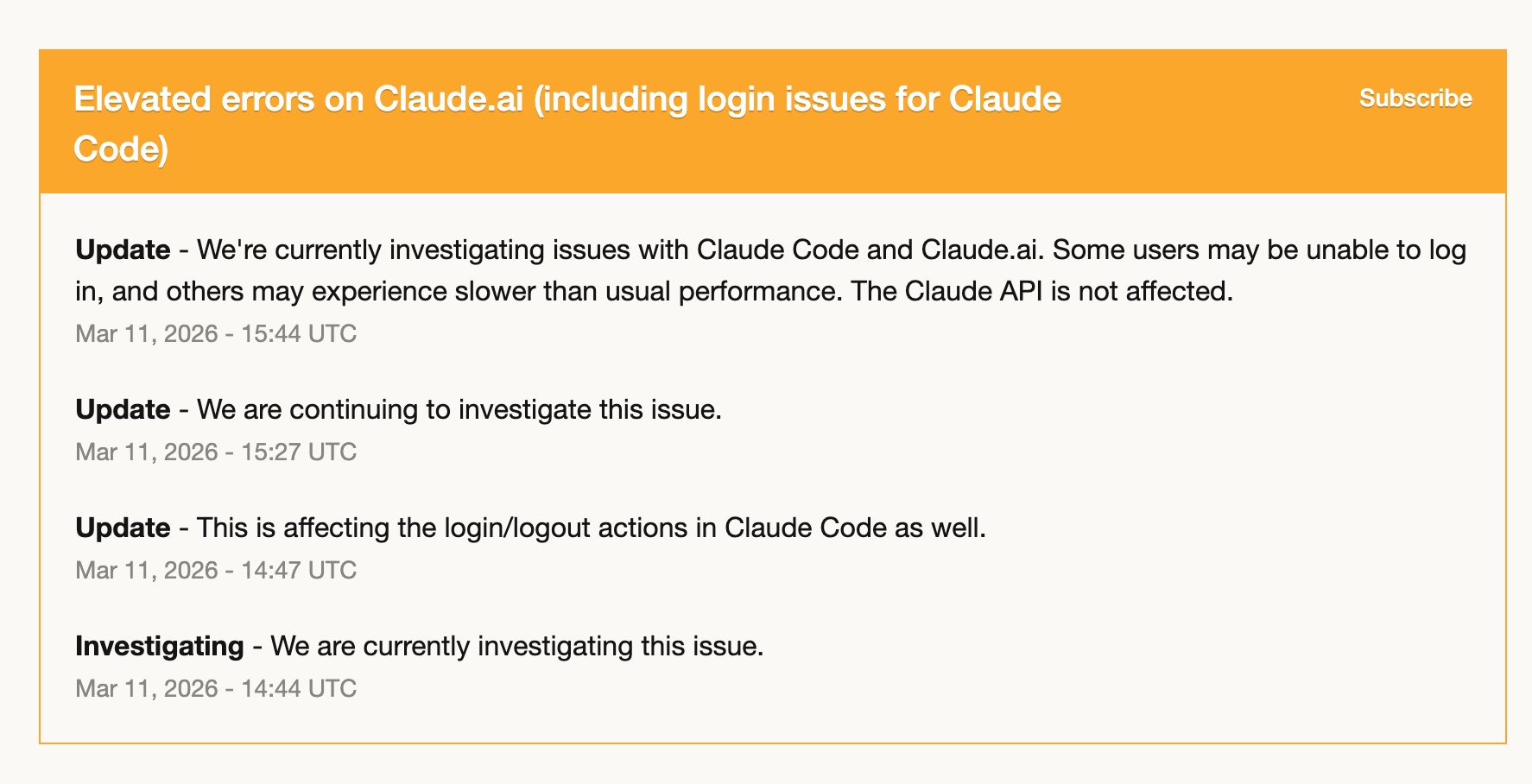
でも、ぼくはすでに Codex 側の習熟を始めていたので、ほぼそのまま切り替えられました。Codex 用のスキルも整っていたし、ワークフローも移植済みだった。GPT-5.4 は十分に仕事をこなしてくれました。
この経験で、はっきりしたことがあります。1つのツールだけに全面依存するのはリスクだということです。ツールが信用できないからではありません。Claude Code はこの1年かなり安定していました。でも、どんなサービスにも「悪い日」はある。ちゃんと使いこなせる2本目を持っていることは贅沢ではなく、運用上のレジリエンスです。
ひと目で見る Claude Code vs. Codex
| 項目 | Claude Code (Opus 4.6) | Codex (GPT-5.4) |
|---|---|---|
| 実行品質 | 深い — 抜け漏れを見つけ、優先順位も付ける | 良い — タスクはこなすが、能動的な分析はやや薄い |
| 自動QA | 組み込み済み、レビューエージェントを自動で走らせる | まだない — 手動検証が必要 |
| 並列エージェント | 成熟している — 5〜6個を協調運用できる | 有望 — 動くが連携はまだ粗い |
| アーキテクチャ推論 | medium thinking で堅い | high thinking でとても強い — リフレームが速い |
| 長時間の計画実行 | 良い | 印象的 — 46分以上連続で走れる |
| コンテキスト圧縮 | やや遅い | 速い — 良し悪しはまだ判断中 |
| 大規模ローカライズ | Opus 4.6 medium としては十分同等 | 同等 — 現時点ではコスト面で有利 |
| プラグイン/スキルの生態系 | 成熟している(Superpowers、/feature-dev など) | 成長中 — Claude のワークフローを移植しやすい |
| クロスモデルレビュー | エッジケースと不整合を拾いやすい | 過剰設計を削り、単純化を提案しやすい |
| コスト | 月額 $100〜200 | 無料1か月プロモ、その後は未定 |
そのほか、いくつか気づいたこと
コンテキスト管理: Codex の方が、コンテキストウィンドウが詰まってきたときの圧縮が速いように感じます。これが良いのか悪いのかはまだ判断していません。ただ、Claude Code の挙動とは明らかに違います。
大規模ローカライズ: ぼくは Claude Code と Opus 4.6 を使って 12言語・390万語を翻訳しました。GPT-5.4 の翻訳品質は Opus 4.6 の medium thinking と同等です。そして今のところ、ぼくにとっては大規模処理のコストが安い。だから最近は、ローカライズのバルク作業を GPT-5.4 側に少しずつ寄せています。このコスト優位がいつまで続くかはわかりません。でも続いている間は、それを使う方が合理的です。
コスト: ぼくは今 Claude Code の月額 $200 の Max プランに入っています。でも Codex がローカライズを含めて仕事をかなり引き受けるようになってきたので、$100 ティアへ下げることも考え始めています。OpenAI の無料1か月は移行を試すのにちょうどいい。仮にフル価格になっても、1本を最大プランで回すより、2本に分散した方が費用対効果がいい可能性はあります。
今の結論
1週間、本当に両方を使ってみたうえでの、今の自分の判断はこうです。
Claude Code に手を伸ばすのはこんなとき: 実行品質そのものが重要で、自動QAがほしいとき。複雑な並列エージェント運用が必要なとき。大きなコードベースで長時間一貫性を保ちたいとき。あるいは、そのプロジェクトですでに Superpowers ワークフローが整っているとき。
Codex に手を伸ばすのはこんなとき: 新しいアーキテクチャ視点がほしいとき。難しい推論問題に対して high thinking を使いたいとき。定義済みの計画を、集中を切らさず長く実行したいとき。もしくは Claude Code の調子が悪い日。
両方を使うべきなのはこんなとき: 少しでも非自明な実装計画を扱うとき。片方で叩き台を作り、もう片方でレビューする。クロスモデルレビューのループは、今のところぼくが見つけた中でいちばん強いワークフローです。
ぼくは Claude Code を捨てるつもりはありません。今でも主力ツールだし、もっとも慣れているエコシステムです。でも、もう「1つだけのツール」に頼る開発者でもありません。GPT-5.4 は、単なる保険ではなく、実力で自分のワークフローの席を勝ち取りました。
AI支援開発の未来は、勝者を1つ決めることではないと思っています。どの場面でどのツールを使うべきかを知ること。そしてもっと大事なのは、一緒に使う方が、別々に使うより強いと理解することです。
よくある質問
コーディング用途で GPT-5.4 は Opus 4.6 より優れているのか
どちらかが一方的に上、という感じではありません。GPT-5.4 の high thinking は、アーキテクチャ推論と長時間の計画実行で強い。一方、Opus 4.6 は実行品質、能動的なギャップ分析、長時間セッションでの一貫性に強い。最良の結果は、両方のモデルにお互いの成果物をレビューさせたときに出ます。
Claude Code から Codex へ乗り換えるべきか
完全移行はおすすめしません。両方に明確な強みがあります。Claude Code の自動QAと並列エージェント運用は本当に一歩先にいるし、Codex の継続実行能力と GPT-5.4 の難問に対する推論力もかなり印象的です。両刀使いの方が取りこぼしが少ないです。
クロスモデルレビューは、その手間に見合うのか
少しでも複雑な計画なら、間違いなく見合います。Opus が GPT-5.4 の出力を見てくれると、エッジケースや不整合を拾いやすい。逆に GPT-5.4 は過剰設計を削ってくれる。2〜3往復するだけで、どちらか一方だけの計画より明らかに引き締まります。
2つのツールを使うと、コストはどれくらいかかるのか
Claude Code はプランによって月額 $100〜200。Codex の価格は変動しますが、今は無料1か月プロモがあります。フル価格になっても、1本を最大プランで回すより、2本に分散して下位ティアで運用した方が安く済む可能性はあります。
Claude Code のプラグインは Codex でも使えるのか
そのままでは使えません。でも移植はできます。ぼくは Claude Code のプラグインワークフロー(/feature-dev、/code-review、/superpowers など)を Codex に調べさせて、~/.codex/skills 配下の Codex スキルへ変換しました。hooks のような Claude 固有機能は置き換えが必要ですが、ワークフローの思想自体は移せます。
そんなわけで、今のところの結論はこれです。ぼくは結構気になっています。ほかにも multi-model ワークフローを回している人はいるんでしょうか。Claude Code と Codex の組み合わせでも、別の組み合わせでも。どんなパターンがうまくいっていますか?
ではまた、 Chandler





