Codex 搭配 GPT-5.4 vs Claude Code 搭配 Opus 4.6——为什么我现在两个都用
在几乎整整一年里,我每天都在用 Claude Code 配 Opus 4.6。然后我花了一周试用 Codex 和 GPT-5.4。我的结论是:没有哪一个能彻底胜出。真正更好的做法,是把两者结合起来——做跨模型审查、利用互补优势、建立操作层面的韧性。
在几乎整整一年里,我每天都在用 Claude Code。后来我花了一周试用 Codex 和 GPT-5.4。没有哪一个能彻底赢下这场比较——但把它们放在一起,让它们彼此审查,最后出来的结果确实比单独用任何一个都更好。 这是我作为一个同时用它们真正交付过产品的人,得出的结论。
过去这段时间,我几乎所有开发工作都靠 Claude Code 配 Opus 4.6 完成:重建这个网站、把 DIALØGUE(对话)送上 App Store、构建 STRAŦUM、在 12 种语言中翻译 390 万词,以及做出一整套课程视频流水线,里面有 18 种布局和按词级别做音频同步。
所以当 OpenAI 在 3 月 5 日推出 搭配 GPT-5.4 的 Codex 的时候,我并不是在找替代品。我只是好奇。再加上 OpenAI 当时有一个免费试用月,这让我几乎没有心理负担就跳进去试了。
结果我挺惊讶的。不只是“还不错”那种惊讶——而是真的觉得,Codex 配 GPT-5.4 的能力比我原本预期的强不少。
一周之后,我没有打算切换阵营。我现在是双持。而且我觉得,组合起来就是比单独用任何一个更好。
为什么 “harness” 和 “model” 的区别很重要?
在展开细讲之前,我想先说一个我觉得大多数比较文章都忽略了的细节。
Claude Code 和 Codex 是 harness。 也就是 CLI 工具、agent 编排方式、插件生态、上下文管理机制,以及它们如何与文件系统和终端交互。Opus 4.6 和 GPT-5.4 才是底层模型。 真正负责判断该做什么、怎么推理、写什么代码的,是模型。
这一点很重要,因为我下面很多观察,有些是在说 harness,有些是在说 model。Claude Code 自动派发 QA agent、管理并行 agent,这属于 harness。GPT-5.4 在我那个碎片同步问题上提出架构性洞察,这属于 model。至于我说跨模型审查会让计划更好,那说的是 模型之间 的推理方式不同,而 harness 只是把结果交到你手上。
一个更强的模型,放进一个更差的 harness 里,依然可能让人用得很痛苦。一个很好的 harness,搭配较弱的模型,也可能显得精致却不够深入。 现在这两个组合都很强,只是它们强在不同的地方。
Codex 配 GPT-5.4 第一次上手是什么感觉?
老实讲——我原本以为 Codex 会让我明显觉得“降级”了。因为我已经在 Claude Code 的生态里待得很深:Superpowers 插件、并行 agent 派发、实现完成后自动跑起来的 code review agent。那是一套已经很成熟的工作流。
但 Codex 配 GPT-5.4 一上手就让我觉得,它是能打的。模型很强,推理很稳,跟计划的能力也很好。当我给它一个结构清晰的实现计划时,它可以连续工作 45 分钟以上还不掉线——提交、测试、推送,然后继续做下一个任务。
我很早就打开了 Codex 的几个实验功能:
- Multi-agents —— 并行处理任务,感觉上有点接近 Claude Code 的 agent 派发
- JavaScript REPL —— 持久化的 Node 运行时,适合做内联调试
- Prevent sleep while running —— 长任务执行时防止机器休眠
这些功能都挺有帮助。尤其是 multi-agent,让我第一次觉得 Codex 正在追上我已经习惯依赖的一种工作方式。
GPT-5.4 在哪里明显强过 Opus 4.6?
我得承认——有一个领域,GPT-5.4 的确明显赢过了 Opus 4.6,而且不是小胜。
我最近一直在做一套课程视频流水线,要把带旁白的音频和 slide fragment 同步起来。难点其实不是时间戳——ElevenLabs 能给出按词级别的时间信息。真正难的是 对齐:也就是,当讲者开始说某个点的时候,屏幕上到底该出现哪个 fragment。
问题在于,speaker notes 往往不会逐字重复 slide 上的文字。有时旁白是在改写 bullet,有时会把两个 bullet 合成一句话,有时某个 bullet 虽然出现在 slide 上,却几乎没有被真正讲到。所以系统只能一直靠关键词去猜。猜得准的时候看起来还挺像回事,但一到复杂的 slide,就会开始崩。
Opus 4.6 用 medium thinking 连着试了好几轮。它不停提出越来越聪明的启发式方案:按文本长度平均切分、在时间戳里查关键词、按句子匹配、双策略匹配……每一版都比上一版好一点,但本质上还是局限在同一个框架里。
而 GPT-5.4 在 high thinking 下抓到了真正的问题:这根本不该被当成关键词匹配问题处理,它应该被当成数据模型问题。 renderer 应该输出真实的 fragment state;assembler 应该按这些 state 去对齐旁白;validation 则应该标记出“视觉结构”和“旁白结构”不匹配的 slide。
这就是正确的洞察。从“根据文本猜同步”切换到“把同步当成流水线中的一等公民”,正是这个问题真正需要的架构重构。而 GPT-5.4 比 Opus 更快抵达了这一层。
Claude Code 依然赢在哪里?
但问题在于——架构洞察,和执行质量与收尾能力,并不是一回事。
执行质量
最典型的例子是:我让两个工具都去审查并改进 7 个课程模块的 companion notes。Codex 回来告诉我,这项工作已经做完了。
Claude Code 回来给我的是这个:
审查完成——全部 7 个模块
第一层:修好现有的 15 条内容偏薄的 companion notes(先把它们补到合格线,这是最快的收益)
第二层:给约 25-30 张高优先级 slide 补 companion notes(核心框架、工具清单、多步骤流程、密集数据页)
这就不是“做完了”。这是一个有层次的差距分析,把 40-45 张需要处理的 slide 按优先级拆开了。“我把任务完成了”和“我把任务完成了,而且这是我发现的问题”之间,差距非常大。 真正在交付产品时,这个差距很关键。
自动 QA
这是 Claude Code 的 killer feature,我觉得大家讨论得远远不够。完成一段实现之后,Claude Code 会自动派出 QA agent——做代码审查、叙事审查、一致性检查——而且不需要我自己再额外开口。这是工具本身内建的。
Codex 现在还没有这一层。Codex 说“做完了”,你就得自己验证,或者自己再搭一层审查流程。Claude Code 则把验证直接并进了工作流里。这个设计真的很聪明。
并行智能体管理
Claude Code 的 agent 编排也更成熟。它会派多个专门 agent,管理它们的结果,再把结论综合成一个清晰的摘要。我有过不少 session,同步跑 5-6 个 agent——explorer、code reviewer、implementation agent、test runner——最后都能被统一协调起来。
Codex 的 multi-agent 很有希望,但还明显更早期一些。它能用,但协调感还没那么顺滑。
一致性
在那种时间拉得很长、要处理很多移动部件的任务里——例如跨 7 个模块做 18 种课程布局——Claude Code 对一致性的维持更好。设计 token 不会乱,命名约定能守住,第一小时做的架构决定,到第四小时通常还会被遵守。
能不能把一个工具的工作流,移植到另一个工具里?
这是我这周一个意外的发现:你完全可以用 Codex 去研究 Claude Code 的插件生态,然后把它们改造成适用于 Codex 的东西。
我自己尤其喜欢几个 Claude Code 插件:功能开发工作流(/feature-dev)、代码评审系统(/code-review)、代码简化器(/code-simplifier)、Superpowers 规划框架(/superpowers),以及前端设计 skill(/frontend-design)。这些其实都不是“功能堆砌”,而是在把最佳实践编码进工具里。
所以我就让 Codex 去研究它们,然后为 Codex 写出等价的 skills:
“I'm writing user-level Codex skills under
~/.codex/skills, using the Claude plugin workflows as the template and adapting them to Codex's skill model where Claude-only features like hooks or plugin commands don't exist.”
结果是能跑通的。不算完美——毕竟有些 Claude Code 的概念在 Codex 里没有直接对应物——但核心工作流是能迁移过来的。现在我在两个工具里,都能用到基于同一套设计哲学的结构化开发流程。
当你让两个模型互相审计划,会发生什么?
我觉得这可能是这周最有价值的发现。
先让 Opus 4.6 严格审 GPT-5.4 写的计划,再让 GPT-5.4 去审 Opus 修订过的版本——这样来回跑几轮,出来的结果明显比单独用任何一个模型都更好。
它们擅长发现的弱点不一样。Opus 往往更容易抓到架构不一致和错误处理上的边角问题。GPT-5.4 往往更容易指出过度设计,并提出更简洁的做法。它们刚好补彼此的盲区。
现在只要是稍微复杂一点的实现计划,我都会这么做:先在一个工具里起草,再让另一个来审,再改,再审。来回两三轮。最后出来的计划会更紧、更稳,也会抓到很多单独一个模型没冒出来的问题。
如果你现在只用一个 AI coding tool,我觉得你等于把一部分质量留在了桌上。不是因为单个工具不好——它们两个都已经很好了——而是因为它们的推理方式真的不一样,而不同的推理方式会抓到不同的问题。
当其中一个工具挂掉时,会发生什么?
3 月 11 日,Claude Code 出现了一段时间的高错误率——登录问题、性能变慢、间歇性失败。那几个小时里,它基本上是没法正常用的。
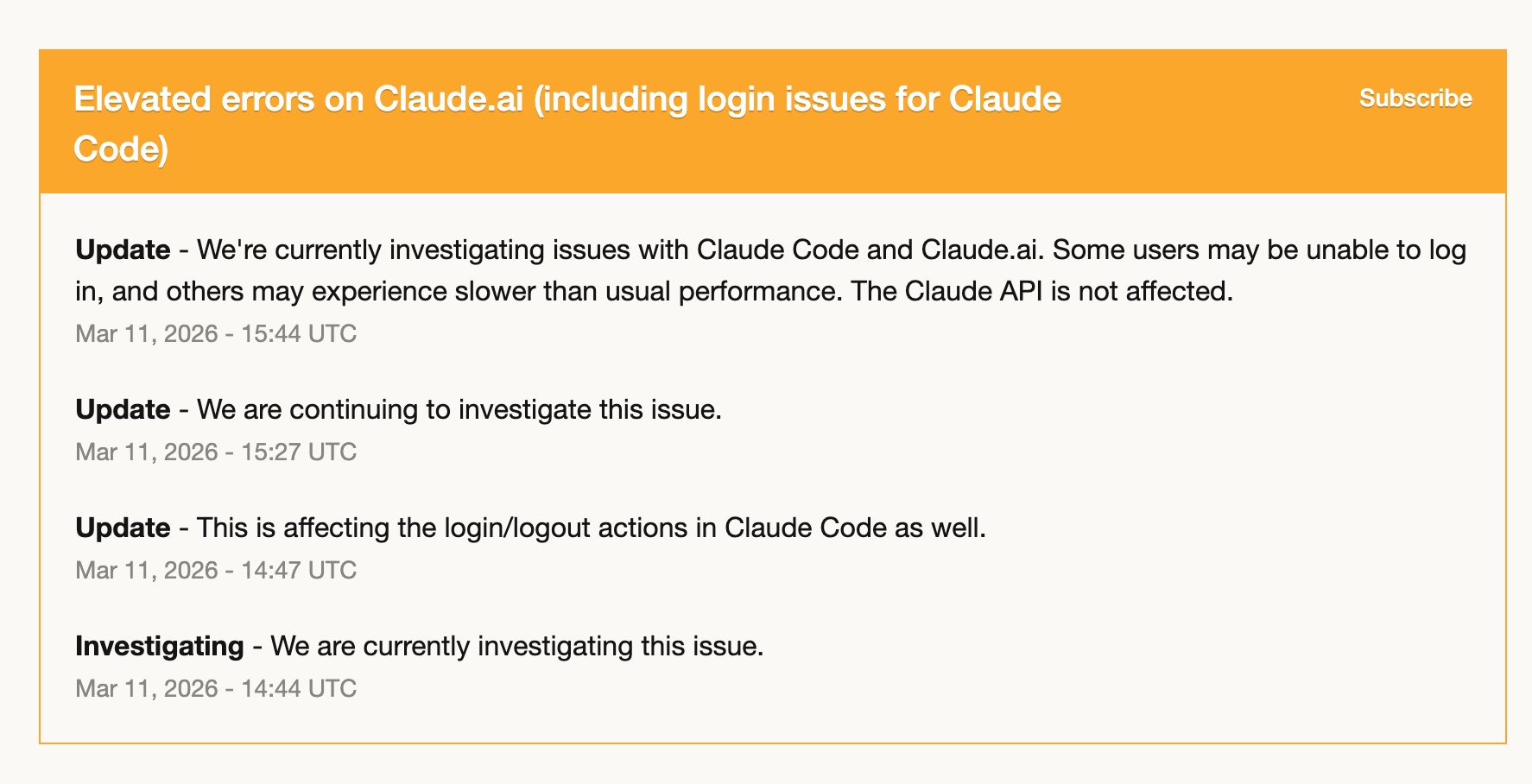
因为那时我已经在逐步把 Codex 的工作流搭起来了,所以我几乎整段时间都切过去用了 Codex。而且我完全能继续工作。我已经把 Codex skills 配起来了,常用工作流也迁过去了,GPT-5.4 足够稳地接住了手上的任务。
那次经历让我更清楚一件事:把自己完全绑在一个工具上,是有风险的。 不是因为那个工具不可靠——我这一年用下来,Claude Code 其实已经相当稳定——而是任何服务都有可能哪天状态不对。真正熟练地掌握第二个工具,不是奢侈品,而是一种操作层面的韧性。
Claude Code vs. Codex:快速对比
| 维度 | Claude Code(Opus 4.6) | Codex(GPT-5.4) |
|---|---|---|
| 执行质量 | 更深——会主动发现缺口、帮你排优先级 | 不错——能完成任务,但主动分析较少 |
| 自动 QA | 内建,会自动派 review agent | 目前还没有——需要手动验证 |
| 并行 agents | 成熟——能协调 5-6 个 agent | 很有前景——能用,但没那么顺 |
| 架构推理 | medium thinking 下也很强 | high thinking 下尤其强——更快完成重构式思考 |
| 持续执行计划 | 好 | 很强——能稳定连续跑很久 |
| 上下文压缩 | 较慢 | 更快——只是不同,不一定更好 |
| 大规模本地化 | 很强(Opus 4.6 medium) | 同样强——目前对我来说更便宜 |
| 插件 / skill 生态 | 更成熟(Superpowers、/feature-dev 等) | 正在成长——但可以吸收 Claude 的工作流 |
| 跨模型审查 | 擅长抓边角问题和不一致 | 擅长抓过度设计并提出简化 |
| 成本 | $100-200/月 | 现在有免费试用月,之后待定 |
还有几点补充观察
上下文管理:Codex 在上下文窗口满了之后,压缩上下文的速度明显更快。这个到底是优点还是缺点,我还没完全下结论——只是它和 Claude Code 的处理方式确实不一样。
大规模本地化:我之前用 Claude Code 配 Opus 4.6 在 12 种语言中翻译了 390 万词。而 GPT-5.4 的翻译质量,大致和 Opus 4.6 的 medium thinking 在同一个档位上——但至少现在,对我来说它大规模跑起来更便宜。所以最近我已经开始把批量本地化工作逐步转到 GPT-5.4 上。这个成本优势能持续多久我不知道,但只要还在,我觉得就值得用。
成本:我现在在用 Claude Code 的 $200/月 Max 套餐。既然 Codex 已经开始承担我相当一部分工作量——尤其是本地化——我正在考虑是不是可以降回 $100 那档。OpenAI 这次免费试用月让切换过程轻松很多,但就算恢复原价,把工作分到两个工具上,可能依然比在一个工具上冲满配更划算。
我现在的结论
在真正双持用了一周之后,我现在的工作模型大概是这样:
优先用 Claude Code 的场景:你需要高执行质量并且最好自带 QA;你需要复杂的多 agent 编排;你需要在一个大项目里长时间维持一致性;或者你正在一个已经搭好 Superpowers 工作流的项目里工作。
优先用 Codex 的场景:你需要一个新的架构视角;你在一个很难的推理问题上想开 high thinking;你要执行的是一份定义清楚、适合持续推进的计划;或者刚好 Claude Code 今天状态不太好。
两个一起用的场景:任何稍微复杂一点的实现计划。先在一个工具里起草,再让另一个来审。这个跨模型审查循环,真的是我这周找到的最好工作流。
我并没有放弃 Claude Code——它依然是我的主工具,也是我最熟悉的生态。但我已经不是一个“单工具开发者”了。GPT-5.4 靠的是真实能力,不是靠“备胎工具”这个身份,才在我的工作流里拿到了自己的位置。
AI 辅助开发的未来,我觉得不是“选出唯一赢家”。而是知道什么时候该用哪个工具。更重要的是,承认一件事:这些工具放在一起,真的比单独用其中一个更强。
常见问题
GPT-5.4 在编码上比 Opus 4.6 更强吗?
不能简单说谁绝对更强。GPT-5.4 在 high thinking 下,架构推理和持续执行计划的能力很突出。Opus 4.6 在执行质量、主动发现缺口、以及长 session 中维持一致性方面依然更强。真正最好的结果,通常来自让两个模型互相审对方的工作。
我应该从 Claude Code 切到 Codex 吗?
我不建议彻底切换。两边都有很明显、而且互不相同的优势——Claude Code 的自动 QA 和并行 agent 编排确实领先,而 Codex 的持续执行能力,以及 GPT-5.4 在难题上的推理,也确实很强。双持才是我现在觉得最合理的用法。
跨模型审查值得多花这点力气吗?
如果计划稍微复杂一点,我觉得绝对值得。让 Opus 去审 GPT-5.4 的输出,再让 GPT-5.4 去审 Opus 修过的版本,会抓到不同类型的问题——Opus 会抓边角和不一致,GPT-5.4 会抓过度设计。两三轮之后出来的计划,明显比只靠一个模型更紧更稳。
双工具组合一个月大概要多少钱?
Claude Code 视套餐不同,大概是 $100-200/月。Codex 的价格现在还在变化——OpenAI 目前提供了一个免费试用月。就算回到正常价格,把工作负载拆到两个工具的较低档位上,可能依然比在一个工具上冲满配更划算。
Claude Code 的插件能直接拿到 Codex 里用吗?
不能直接用,但可以改造。我就是让 Codex 去研究 Claude Code 的插件工作流(像 /feature-dev、/code-review、/superpowers),再把核心逻辑翻成 Codex skills,放到 ~/.codex/skills 里。像 hooks 这类 Claude 专属的东西不一定能照搬,但工作流本身是可以迁过去的。
差不多就这些。我倒是挺好奇——现在有没有其他人也在跑多模型工作流?会一起用 Claude Code 和 Codex,或者别的组合吗?你们目前摸索出什么模式了?
回头聊, Chandler





