Bersiap untuk Pengalaman Pencarian yang Lebih Baik dengan Integrasi ChatGPT Microsoft?
Integrasi ChatGPT-Bing Microsoft menyelesaikan masalah data, tapi tantangan sebenarnya adalah merancang antarmuka yang tahu kapan harus memberikan satu jawaban vs. banyak.
Posting ini ditulis pada tahun 2023. Beberapa detail mungkin sudah berubah sejak saat itu.
Minggu ini, beberapa media memberitakan bahwa Microsoft sedang mengupayakan integrasi fitur ChatGPT ke Bing Search. Karena saya menulis tentang "akankah ChatGPT menggantikan Google?" sebelumnya, saya ingin memberikan pemikiran tambahan di sini.
Mengindeks konten web bukan lagi penghalang.
Microsoft dilaporkan menginvestasikan $1 miliar ke OpenAI pada tahun 2019. Jadi artinya kemitraan antara kedua perusahaan telah berlangsung setidaknya tiga tahun. Bing Search jelas bisa mengindeks web, jadi kita harus berasumsi bahwa pengindeksan konten web bukan masalah jika OpenAI ingin memperluas dataset chatGPT melampaui 2021. Mengingat skala Microsoft, kita bisa berasumsi bahwa kemampuan indexing/crawling real-time-nya seharusnya cukup bagus juga dibandingkan Google.
Bing sudah memiliki konten gambar, video, dll... sebagai bagian dari datasetnya jadi lagi-lagi ini tidak akan menjadi penghalang untuk chatGPT OpenAI.
Bing Search bisa menilai kepercayaan konten dengan cukup baik
Meskipun saya belum melihat perbandingan terbaru antara hasil Google Search dan Bing Search, aman untuk mengatakan bahwa kesenjangan antara kemampuan kedua perusahaan dalam menentukan kepercayaan sebuah konten seharusnya tidak terlalu besar. Jadi lagi, dengan bantuan Microsoft, menemukan jawaban paling akurat mungkin bukan penghalang besar untuk OpenAI/chatGPT.
Satu contoh spesifik adalah chatGPT tidak memiliki data rating layanan terbaru, jadi tidak bisa menjawab pertanyaan tentang layanan lokal seperti "tukang pipa terbaik dekat saya" atau "restoran Cina terbaik dekat saya." Di sinilah dataset Microsoft berperan membantu.
Masalah antarmuka pengguna
Meskipun ada argumen valid tentang betapa user-friendly pengalaman ChatGPT, ini bukan pengalaman satu-ukuran-untuk-semua untuk semua pertanyaan/query. Di banyak kasus, pengguna ingin memiliki beberapa jawaban. Misalnya, dengan layanan lokal yang sama di atas, pengguna sering ingin melihat daftar pilihan yang cocok. Bisa diargumentasikan bahwa dalam kasus tersebut, pengguna kemudian perlu memodifikasi prompt untuk ChatGPT menjadi "berikan saya 5 pilihan layanan xyz terbaik dekat saya" vs. "layanan xyz terbaik dekat saya."
Saya akan berargumen, bagaimanapun, bahwa melakukan ini saja tidak cukup. Mesin pencari harus cukup pintar untuk mengetahui bahwa di banyak kasus, tidak ada satu jawaban terbaik atau daftar pendek jawaban terbaik. Jawaban terbaik tergantung pada situasi/konteks.
Selain itu, kita punya fakta dan kita punya opini. Keduanya sangat berbeda satu sama lain.
Jadi bagaimana merancang antarmuka pengguna yang bisa terbaik untuk berbagai skenario adalah kuncinya. Misalnya, bahkan untuk sesuatu sesederhana "resep baguette Vietnam" :D, inilah yang saya dapatkan dari Google, Bing, dan ChatGPT per Januari 2023. Tidak jelas mana yang lebih baik atau jawaban chatGPT lebih baik.
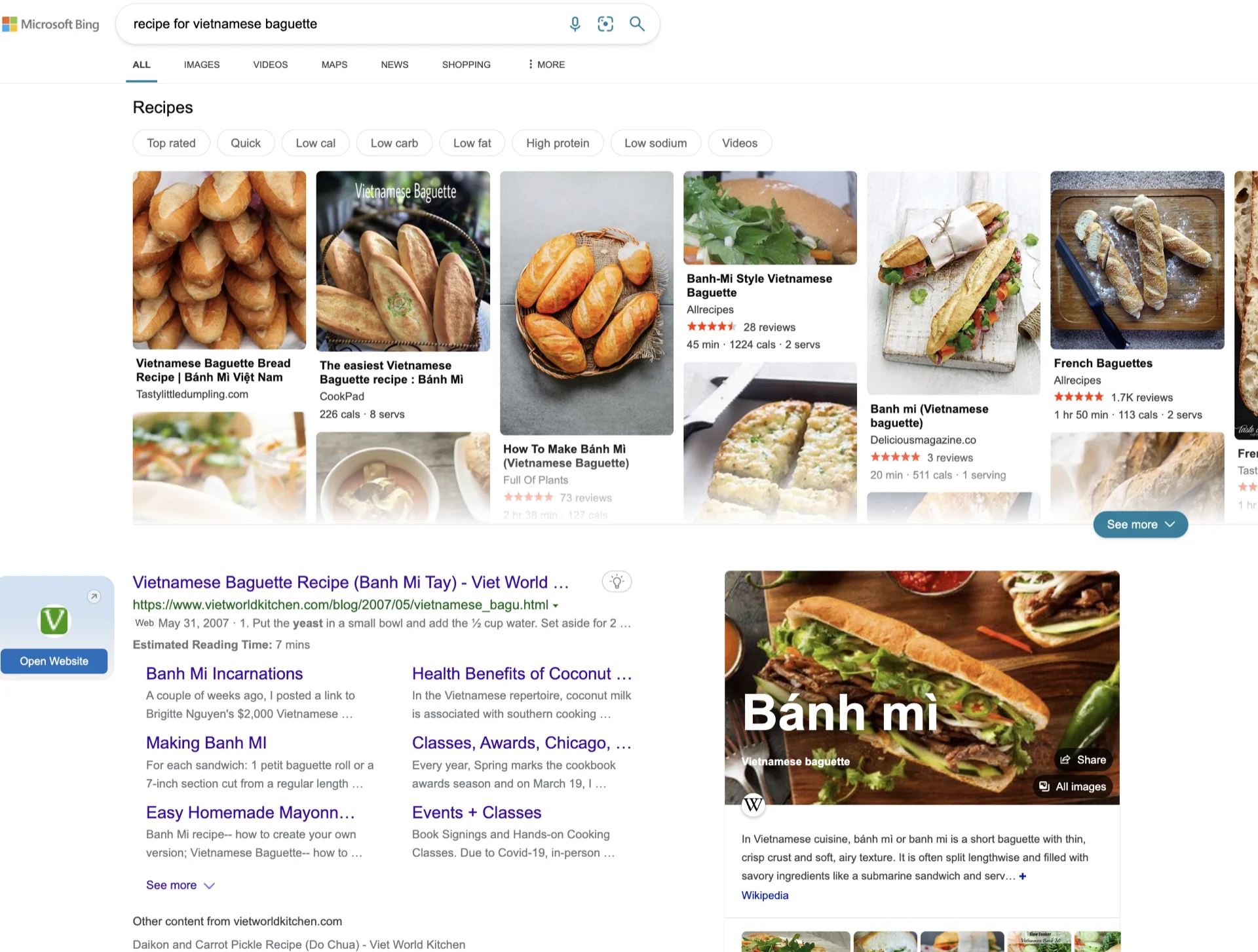
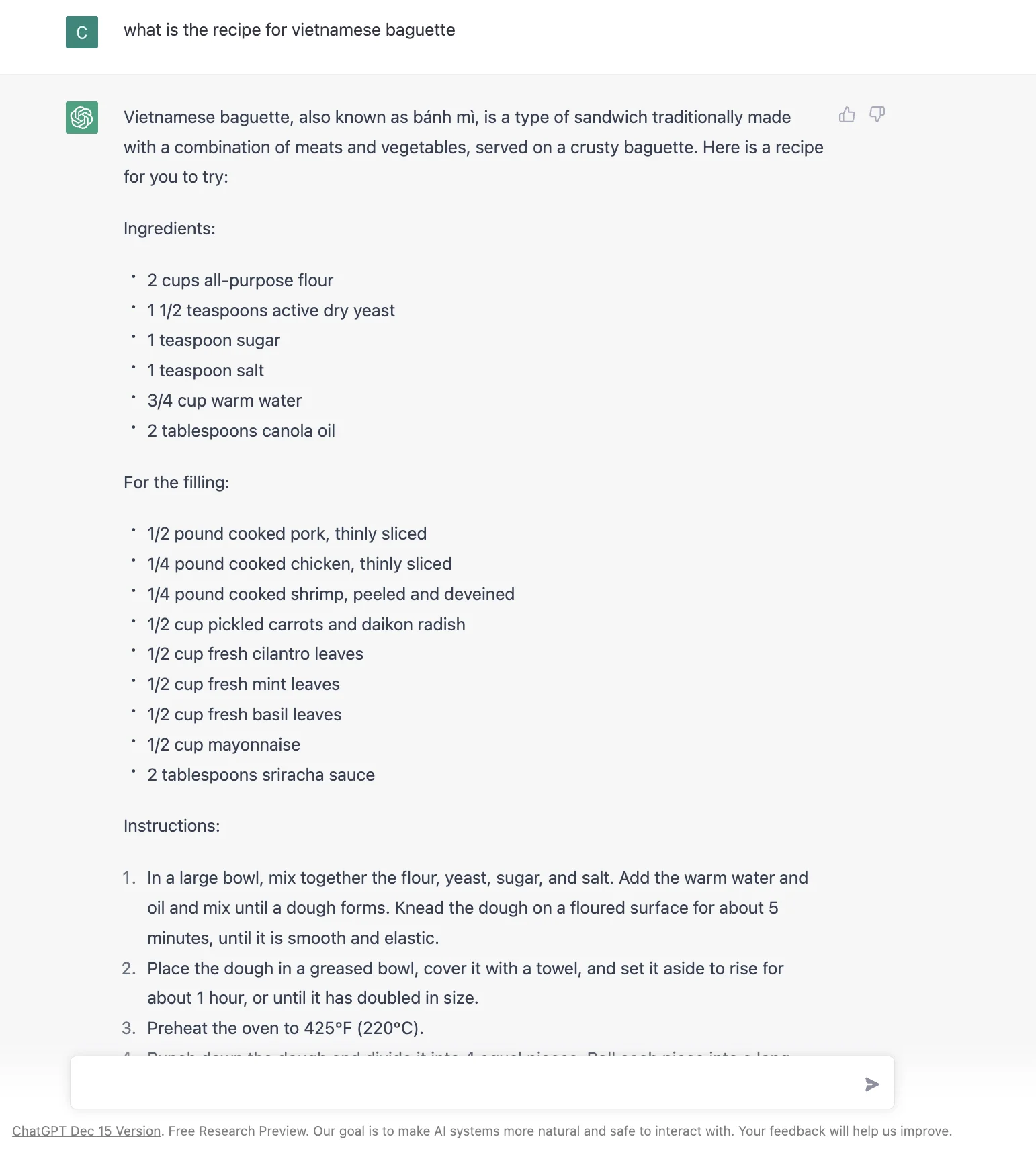
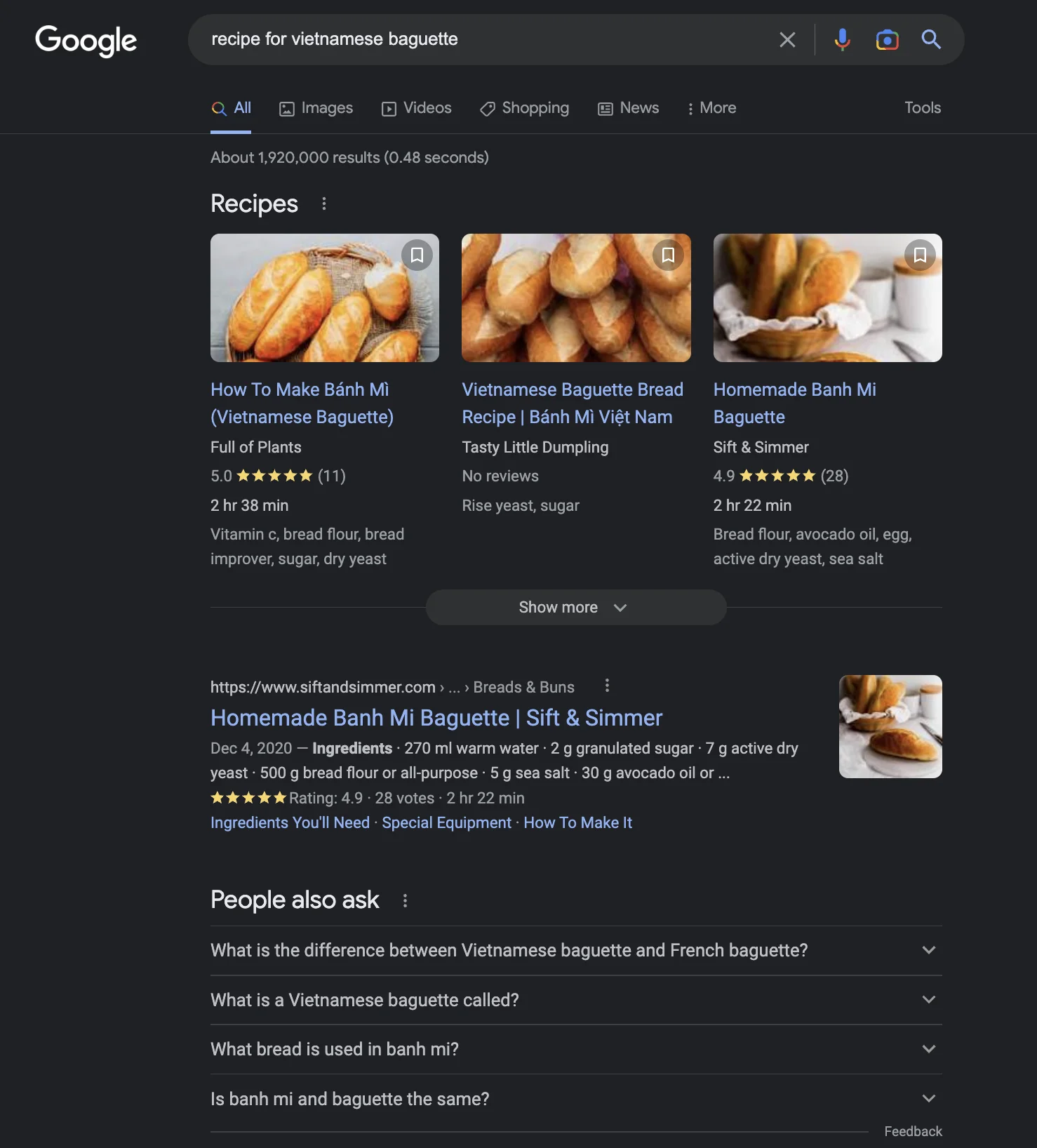
Kuncinya kemudian adalah mengubah antarmuka hasil pencarian secara dinamis berdasarkan niat pengguna, menggunakan machine learning. Saya tidak yakin seberapa mudah atau sulit untuk melakukan ini. Tapi sepertinya langkah logis untuk menggabungkan kekuatan gaya jawaban tunggal dari ChatGPT dan mesin pencari.
Asisten bahasa
Saya akan berargumen bahwa memberikan jawaban dari perspektif pencarian informasi murni bukan alasan orang menyukai ChatGPT, melainkan kemampuan untuk memberikan konteks pada chatGPT dan kemudian memintanya menyelesaikan tugas terkait bahasa seperti menulis puisi, pendahuluan, esai, dll...
Kasus penggunaan ini sangat berbeda dari mesin pencari dan lebih erat terkait dengan kemampuan untuk menghasilkan narasi PowerPoint atau menulis di Microsoft Word. Jadi saya sebenarnya berpikir bahwa berita tentang Microsoft yang mengintegrasikan berbagai kemampuan OpenAI ke dalam suite Office 365 adalah berita yang lebih baik.
Batas-batas bahasa
Jacob Browning dan Yann Lecun menulis artikel yang sangat bagus tentang AI dan batas-batas bahasa pada Agustus 2022, sebelum ChatGPT dibuka untuk publik. Meskipun artikel mereka merujuk pada LaMDA, kontennya pada dasarnya berlaku untuk chatGPT juga atau Large Language Model lainnya. Artikelnya panjang jadi jika kamu ingin poin-poin utamanya, ini dia:
Seorang insinyur Google baru-baru ini menyatakan chatbot AI Google, LaMDA, sebagai manusia, yang menimbulkan berbagai reaksi. Chatbot, LaMDA, adalah large language model (LLM) yang dirancang untuk memprediksi kata-kata berikutnya yang paling mungkin untuk baris teks apa pun yang diberikan.
Beberapa orang mencemooh ide itu, sementara yang lain menyarankan bahwa AI berikutnya mungkin benar-benar manusia. Keberagaman reaksi menyoroti masalah yang lebih dalam: seiring LLM ini menjadi lebih umum dan kuat, semakin sedikit kesepakatan tentang cara memahaminya. Masalah mendasarnya adalah sifat bahasa yang terbatas. Jelas bahwa sistem-sistem ini ditakdirkan untuk pemahaman dangkal yang tidak akan pernah mendekati pemikiran penuh yang kita lihat pada manusia. Ini karena bahasa hanyalah jenis representasi pengetahuan yang spesifik dan terbatas. Bahasa unggul dalam mengekspresikan objek dan properti diskrit serta hubungan di antaranya, tapi kesulitan untuk merepresentasikan informasi yang lebih konkret, seperti mendeskripsikan bentuk tidak beraturan atau gerakan objek. Ada skema representasi lain, seperti pengetahuan ikonik dan pengetahuan terdistribusi, yang bisa mengekspresikan informasi ini dengan cara yang mudah diakses.
Bahasa adalah metode bandwidth rendah untuk mengirimkan informasi, dan sering ambigu karena homonim dan kata ganti. Manusia tidak membutuhkan kendaraan sempurna untuk komunikasi karena kita berbagi pemahaman non-linguistik. Large Language Model (LLM) dilatih untuk menangkap pengetahuan latar belakang untuk setiap kalimat, melihat kata-kata dan kalimat di sekitarnya untuk menyusun apa yang sedang terjadi. LLM telah memperoleh pemahaman dangkal tentang bahasa, tapi pemahaman ini terbatas dan tidak mencakup know-how untuk percakapan yang lebih kompleks. Akibatnya, mudah untuk mengelabui mereka dengan menjadi tidak konsisten atau mengganti bahasa. LLM kekurangan pemahaman yang diperlukan untuk mengembangkan pandangan yang koheren tentang dunia.
Meskipun bahasa bisa menyampaikan banyak informasi dalam format kecil, banyak pengetahuan manusia yang bersifat non-linguistik dan bisa disampaikan melalui cara lain seperti diagram, peta, artefak, dan kebiasaan sosial. Ini menunjukkan bahwa mesin yang dilatih hanya pada bahasa tidak akan mampu sepenuhnya mendekati kecerdasan manusia karena hanya memiliki akses ke sebagian kecil pengetahuan manusia melalui saluran sempit dan bahwa pemahaman non-linguistik yang mendalam tentang dunia diperlukan agar bahasa menjadi berguna. Ini juga menyiratkan bahwa ada batas seberapa pintar mesin jika hanya dilatih pada bahasa.
Itu dari saya. Bagaimana menurutmu? Apakah kamu melihat dirimu beralih dari Google ke Bing yang bertenaga ChatGPT, atau kebiasaan membuatmu tetap di Google? :)
Salam,
Chandler