Reaksi terhadap "Bing AI Can't Be Trusted"
Saya memverifikasi klaim si fact-checker tentang Bing AI yang memalsukan data keuangan—ternyata masalah angka-angka karangan ini nyata dan lebih parah dari yang saya harapkan.
Posting ini ditulis pada tahun 2023. Beberapa detail mungkin sudah berubah sejak saat itu.
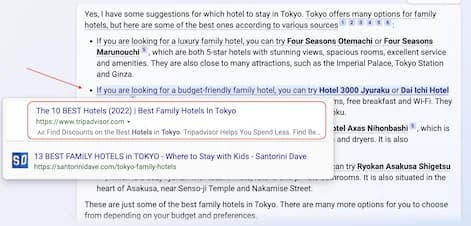
Saya menemukan artikel ini hari ini Bing AI can't be trusted, dan tentu saja, ini memicu ketertarikan saya. Ini adalah artikel bagus yang penuh dengan fact-check untuk menunjukkan bahwa Bing chat yang baru menyertakan banyak fakta karangan tentang informasi faktual. Postingannya relatif pendek, jadi silakan baca langsung.
Jadi beberapa reaksi cepat dari saya:
Kaget dan tidak kaget pada saat bersamaan
Saya secara umum mengetahui keterbatasan large language model (LLM) yang mana chatGPT adalah salah satunya. Tiga keterbatasan utamanya adalah:
- Model ini tidak mengindeks web di luar data teks (seperti video, audio, gambar, dll…)
- Dataset chatGPT sudah sangat lama (2021)
- Model-model ini mengarang kata-kata karena mereka tidak tahu sumber informasi mana yang lebih otoritatif/terpercaya dari yang lain.
Jadi saya berharap bahwa dengan integrasi Bing & OpenAI, mesin pencari Bing bisa mengatasi semua keterbatasan di atas. Yah, sepertinya berdasarkan artikel Dmitri, Bing belum menyelesaikannya. Masih jauh dari itu.
Fact-check artikel itu lagi
Tidak bagus juga kalau apa yang disebutkan Dmitri ternyata tidak akurat secara faktual. Jadi saya melanjutkan dan melakukan beberapa fact-check sendiri. Saya mulai dengan laporan keuangan Gap karena sepertinya paling mudah untuk diperiksa. Saya menyertakan sumber dan screenshot di bawah supaya kamu tidak perlu mengulangi latihan ini:
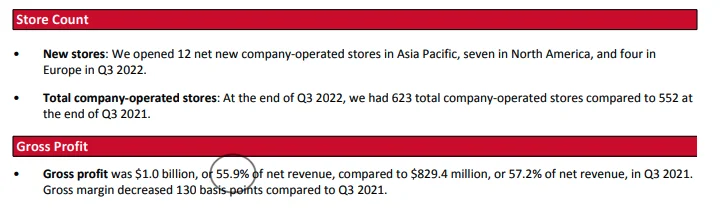
- Ini adalah rilis pendapatan Q3 2022 Gap.
- Saya mengambil screenshot di bawah dari laporan Gap dan meng-highlight angka-angka kunci dengan warna merah. Dmitri benar, Bing chat mengarang angka-angka seperti adjusted gross margin, operating margin, dll…

Bagaimana dengan angka-angka Lululemon?
- Ini adalah laporan keuangan Q3 2022 Lululemon. Sama, saya meng-highlight angka-angka kunci yang disebutkan dalam artikel Dmitri di screenshot di bawah. Dia benar, Bing search mengarang angka-angka.

Mengenai itinerary Mexico City, saya bukan ahli di topik ini, jadi saya tidak bisa melakukan fact-check dengan cermat. Misalnya, ketika saya mencari "Primer Nivel Night Club - Antro", saya menemukan halaman Facebook ini. Tapi saya tidak punya cara untuk memverifikasi dengan kepastian 100% apakah saran dari Bing Search valid atau tidak.
Lalu apa selanjutnya?
Tampak jelas bahwa pada saat ini, integrasi Bing & OpenAI belum mampu memperbaiki masalah large language model (LLM) yang suka mengarang seenaknya.
Saya tidak cukup teknis untuk memahami seberapa sulit menyelesaikan masalah ini. Kalau sudah seakurat ini salahnya dengan data faktual, kita perlu berhati-hati dengan topik yang lebih subjektif seperti restoran/tukang ledeng/layanan lokal terbaik, keuangan pribadi, kesehatan, hubungan, dll.
Sekarang untuk bersikap adil terhadap Bing dan OpenAI, mereka memang mengatakan selama presentasi bahwa mereka memahami bahwa teknologi baru ini bisa salah dalam banyak hal, jadi mereka mendesain antarmuka "thumb up/thumb down" supaya pengguna bisa memberikan feedback dengan mudah. Semoga, dengan lebih banyak feedback pengguna, mesinnya akan menjadi lebih baik.
Algoritma untuk fact-check output LLM?
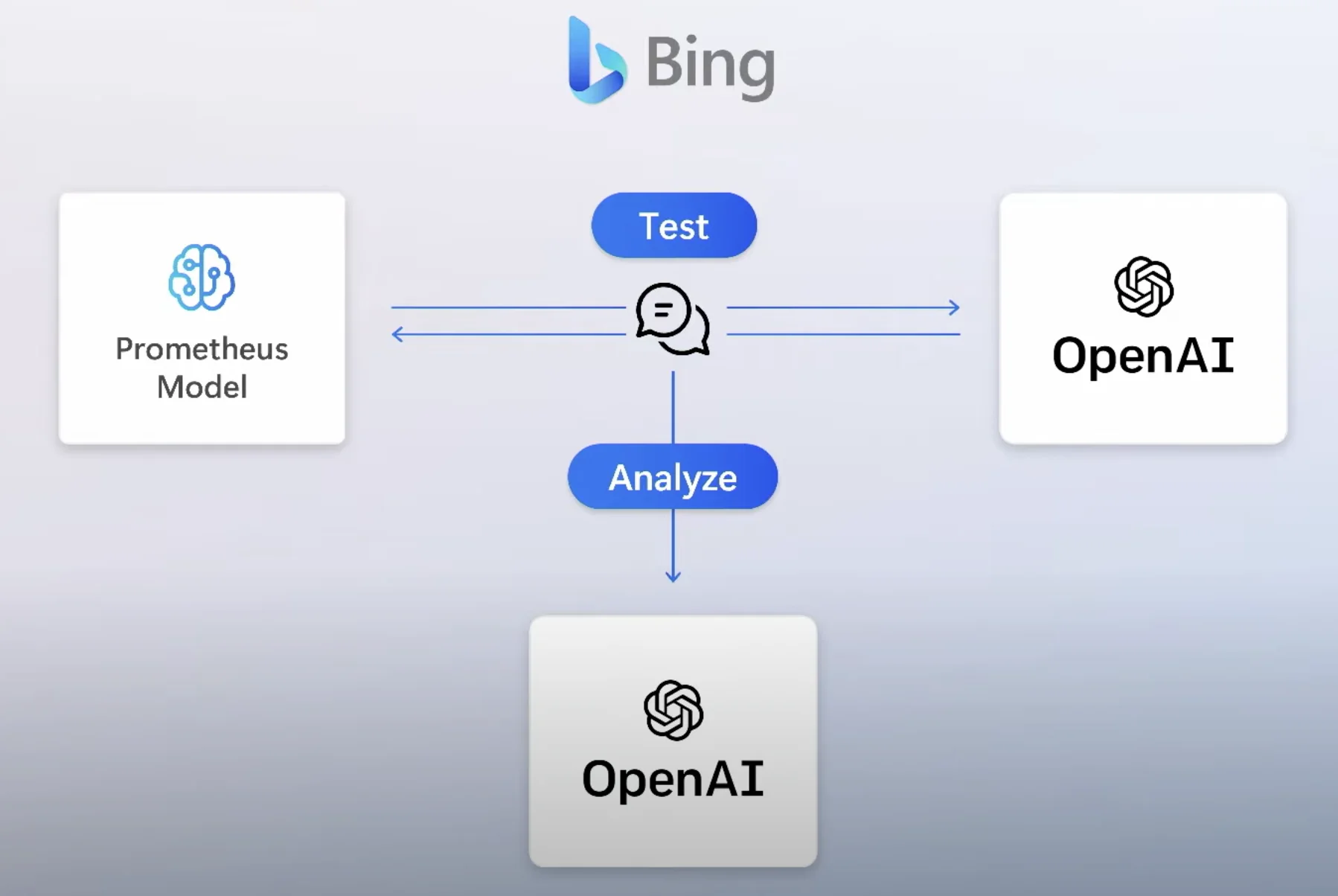
Karena LLM sering menghasilkan output yang salah, bagaimana kalau membuat algoritma untuk fact-check output tersebut secara terus-menerus? Ini mirip dengan apa yang Microsoft bicarakan tentang algoritma keamanan yang mereka bangun ke dalam Prometheus, mensimulasikan prompt dari aktor jahat ke mesin.
Peran manusia
Teknologi ini sepertinya masih di tahap awal, dan meskipun kemajuannya eksponensial, peran manusia sangat kritis. Kita belum bisa mempercayai outputnya, bahkan dengan integrasi Bing & OpenAI. Mesin bisa membantu kita dengan 50% dari hasil yang diinginkan (kurang lebih), tapi kita perlu memasukkan 50% sisanya.
Sepertinya ada cukup waktu bagi kita untuk menyesuaikan diri, mempelajari kelebihan dan keterbatasan teknologi ini, dan menggunakannya secara efektif.
Bagi para engineer yang mendesain sistem ini, kalian mungkin perlu melakukan pekerjaan yang lebih baik dalam menyorot kepada pengguna akhir titik data dan kalimat yang mesin tidak yakin tentangnya. Otak manusia kita suka jalan pintas jadi saya yakin banyak dari kita (termasuk saya sendiri) akan mengambil jalan malas dan menerima apa yang dikatakan mesin sebagai kebenaran :P Sulit bagi kita untuk selalu waspada 100% sepanjang waktu.
Pernahkah kamu menemukan jawaban yang dihasilkan AI yang salah tapi penuh percaya diri? Saya ingin mendengar contohmu — semakin spesifik, semakin baik.
Salam,
Chandler