Codex와 GPT-5.4 vs Claude Code와 Opus 4.6 — 이제는 왜 둘 다 쓰는가
거의 1년 동안 매일 Claude Code와 Opus 4.6을 쓰다가, Codex와 GPT-5.4를 1주일 동안 써봤습니다. 결론은 어느 한쪽이 완승하는 그림이 아니라는 거예요. 크로스 모델 리뷰, 서로 다른 강점, 운영 레질리언스까지 생각하면 둘을 함께 쓰는 편이 하나만 쓰는 것보다 낫습니다.
거의 1년 동안 매일 Claude Code를 쓰다가, Codex와 GPT-5.4를 1주일 정도 깊게 써봤습니다. 결론은 간단했어요. 둘 중 하나가 완전히 이기는 게임이 아니었습니다. 오히려 두 도구를 함께 써서 서로의 결과를 리뷰시키는 편이, 하나만 쓸 때보다 더 좋은 결과를 내줬어요. 실제로 둘 다로 제품을 만들어 본 사람 입장에서, 제가 느낀 걸 정리해보겠습니다.
저는 거의 1년 동안 Claude Code와 Opus 4.6을 제 주력 개발 도구로 써왔어요. 이 사이트를 다시 만드는 일, DIALØGUE(다이얼로그)를 App Store에 올리는 일, STRAŦUM(스트라텀)을 만드는 일, 12개 언어로 390만 단어를 번역한 일, 그리고 18개 레이아웃 타입과 단어 단위 오디오 싱크를 가진 코스 비디오 파이프라인을 만드는 일까지요.
그래서 OpenAI가 3월 5일 Codex와 GPT-5.4를 출시했을 때, 저는 대체재를 찾고 있었던 게 아니었어요. 그냥 궁금했습니다. 게다가 OpenAI가 무료 1개월 프로모션까지 하고 있었으니, 부담 없이 깊게 써보기에 딱 좋았고요.
생각보다 꽤 놀랐어요. 아니, "꽤"보다 더 놀랐다고 해야 할 것 같아요. Codex와 GPT-5.4는 제가 예상했던 것보다 훨씬 더 제대로 된 도구였습니다.
1주일이 지난 지금, 저는 갈아타지 않았습니다. 하지만 이제는 한 도구만 쓰는 개발자도 아니에요. 지금은 두 손에 하나씩 들고 쓰고 있고, 적어도 현재로서는 그 편이 더 강하다고 느낍니다.
왜 하네스와 모델을 구분해서 봐야 할까
본론으로 들어가기 전에, 대부분의 비교에서 빠지는 뉘앙스가 하나 있습니다.
Claude Code와 Codex는 하네스입니다. CLI 도구이자, 에이전트 오케스트레이션 방식이고, 플러그인/스킬 생태계이며, 컨텍스트를 관리하는 방법이고, 파일 시스템과 터미널을 다루는 방식이에요. 반면 Opus 4.6과 GPT-5.4는 그 아래에서 실제 결정을 내리는 모델입니다. 무엇을 해야 하는지, 어떻게 문제를 풀어야 하는지, 어떤 코드를 써야 하는지를 판단하는 쪽이죠.
이걸 구분해야 하는 이유는, 제 관찰 중 일부는 하네스에 대한 이야기이고 일부는 모델에 대한 이야기이기 때문입니다. Claude Code의 자동 QA 디스패치와 병렬 에이전트 관리 능력은 하네스의 강점이에요. GPT-5.4가 제 프래그먼트 싱크 문제를 바라본 아키텍처 관점은 모델의 강점이고요. 크로스 모델 리뷰가 계획을 더 좋게 만든다는 이야기는, 본질적으로 모델들이 다르게 사고한다는 이야기입니다. 하네스는 그 결과를 전달하는 방식일 뿐이에요.
모델이 더 좋아도 하네스가 별로면 경험은 답답해질 수 있어요. 반대로 하네스가 훌륭해도 모델이 얕으면, 매끈하긴 한데 속이 빈 느낌이 날 수 있습니다. 지금은 두 조합 모두 강해요. 다만 강한 방식이 다릅니다.
Codex와 GPT-5.4를 처음 써봤을 때의 인상
솔직히 말하면, 처음에는 Codex가 조금 약하게 느껴질 거라고 생각했어요. 저는 이미 Claude Code 생태계에 꽤 깊이 들어와 있었거든요. 구조화된 계획 수립을 돕는 Superpowers 플러그인, 병렬 에이전트 디스패치, 구현 후 자동으로 돌아가는 코드 리뷰 에이전트. 워크플로우 자체가 꽤 성숙해져 있습니다.
그런데 Codex와 GPT-5.4는 첫인상부터 꽤 경쟁력이 있었어요. 모델은 강했고, 추론은 안정적이었고, 계획도 잘 따랐습니다. 잘 짜인 구현 계획을 주면 45분 넘게 흐름을 잃지 않고, 커밋하고, 테스트하고, push하고, 다음 작업으로 넘어가는 식으로 계속 일을 진행할 수 있었어요.
초반에는 Codex의 실험적 기능 몇 가지도 켰습니다.
- Multi-agents — Claude Code의 에이전트 디스패치와 비슷한 병렬 작업 실행
- JavaScript REPL — 인라인 디버깅용 지속형 Node 런타임
- Prevent sleep while running — 긴 세션 동안 머신이 잠들지 않게 유지
이 세 가지가 체감상 꽤 차이를 만들었어요. 특히 multi-agent 지원은, 제가 Claude Code에서 이미 의존하고 있던 작업 방식에 Codex가 꽤 가까워지고 있다는 느낌을 줬습니다.
GPT-5.4가 Opus 4.6보다 더 좋았던 지점
여긴 인정해야 합니다. GPT-5.4가 Opus 4.6보다 분명히 나았던 구간이 있었어요. 그리고 그 차이는 작지 않았습니다.
저는 요즘 코스 비디오 파이프라인을 만들고 있습니다. 슬라이드 프래그먼트와 내레이션 오디오를 동기화하는 작업이죠. 어려운 부분은 타이밍 자체가 아니에요. ElevenLabs가 단어 단위 타임스탬프를 주니까요. 진짜 어려운 건 정렬(alignment) 입니다. 발표자가 어떤 내용을 말하기 시작할 때, 화면에 어떤 프래그먼트를 보여줘야 하는지를 결정하는 문제예요.
스피커 노트는 슬라이드의 문구를 그대로 반복하지 않습니다. 어떤 때는 불릿을 바꿔 말하고, 어떤 때는 두 개를 하나의 생각으로 묶고, 어떤 때는 슬라이드에는 있지만 거의 입 밖으로 나오지 않는 항목도 있어요. 그래서 시스템은 키워드로 추측할 수밖에 없는데, 쉬운 슬라이드에선 그럭저럭 맞아 보이지만 어려운 슬라이드에선 무너집니다.
Opus 4.6은 medium thinking으로 이 문제를 여러 번 다뤘지만, 점점 더 영리한 휴리스틱을 쌓는 방향으로 갔어요. 텍스트 길이에 따른 균등 분할, 타임스탬프 안 키워드 검색, 문장 단위 매칭, 이중 전략 매칭. 하나하나 이전보다 낫긴 했지만, 근본적인 한계는 남아 있었습니다.
반면 GPT-5.4는 high thinking으로 이걸 키워드 매칭 문제로 보면 안 된다고 봤어요. 이건 데이터 모델 문제라고요. 렌더러가 실제 프래그먼트 상태를 내보내고, 어셈블러가 그 상태에 맞춰 내레이션을 정렬하고, 시각 구조와 내레이션이 안 맞는 슬라이드는 검증 단계에서 플래그를 세워야 한다고 했습니다.
정확한 통찰이었어요. "텍스트에서 동기화를 억지로 추측한다"에서 "동기화 자체를 파이프라인의 1급 개념으로 만든다"로 관점을 바꾸는 게 핵심이었거든요. 그리고 GPT-5.4는 Opus보다 더 빨리 거기에 도달했습니다.
그래도 Claude Code가 여전히 앞서는 부분
다만 여기서 중요한 건, 아키텍처 통찰과 실행 품질, 그리고 끝까지 밀어붙이는 능력은 서로 다른 문제라는 점입니다.
실행 품질
가장 명확한 예가 있어요. 저는 두 도구 모두에게 7개 코스 모듈의 companion notes를 감사하고 개선해 달라고 요청했습니다. Codex는 작업이 끝났다고 알려왔어요.
Claude Code는 이렇게 돌아왔습니다.
감사 완료 — 7개 모듈 전체
Tier 1: 기존의 얇은 companion notes 15개를 기준 수준까지 끌어올리기 (빠른 성과)
Tier 2: 우선순위가 높은 슬라이드 약 25~30장에 companion notes 추가하기 (핵심 프레임워크, 도구 목록, 다단계 프로세스, 밀도 높은 통계)
이건 "끝났다"가 아니에요. 40~45개 슬라이드에 대한 구조화된 갭 분석이고, 우선순위까지 붙어 있습니다. "해냈습니다"와 "해냈고, 그 과정에서 이런 갭이 보였습니다"의 차이는 실제 제품을 만드는 입장에서는 꽤 큽니다.
자동 QA
이건 Claude Code의 킬러 기능이라고 생각해요. 더 많이 이야기돼야 한다고 봅니다. 어느 정도 구현을 끝내면 Claude Code는 제가 따로 시키지 않아도 QA 에이전트를 자동으로 돌려요. 코드 리뷰, 내러티브 리뷰, 일관성 점검. Claude Code 자체 워크플로우 안에 들어가 있습니다.
Codex는 아직 여기까지 오지 않았어요. Codex가 "끝났다"고 하면, 직접 검증하거나 별도 리뷰 프로세스를 짜야 합니다. Claude Code는 검증이 워크플로우 일부예요. 이건 정말 훌륭합니다.
병렬 에이전트 관리
Claude Code의 에이전트 오케스트레이션은 더 성숙합니다. 여러 전문 에이전트를 던지고, 결과를 관리하고, 발견사항을 종합해서, 하나의 일관된 요약으로 돌려줘요. 실제로 저는 5~6개 에이전트가 동시에 도는 세션을 여러 번 해봤습니다. explorer, code reviewer, implementation agent, test runner가 함께 움직이는 식이죠.
Codex의 multi-agent는 충분히 유망합니다. 작동은 해요. 다만 협업과 조율의 매끄러움은 아직 Claude Code 쪽이 더 낫습니다.
일관성
긴 세션에서 움직이는 부분이 많을수록 — 예를 들어 7개 모듈, 18개 레이아웃 타입을 넘나드는 슬라이드 제작 같은 작업 — Claude Code가 일관성을 더 잘 유지합니다. 디자인 토큰이 틀어지지 않고, 네이밍 규칙도 버텨주고, 첫 시간에 세운 아키텍처 결정이 네 번째 시간에도 존중돼요.
두 도구의 워크플로우를 서로 이식할 수 있을까
이번에 의외였던 건, Codex를 이용해 Claude Code의 플러그인 생태계를 살펴보고, 그걸 Codex 쪽으로 옮기는 작업이 가능했다는 점이에요.
저는 Claude Code 플러그인 중에서도 /feature-dev, /code-review, /code-simplifier, /superpowers, /frontend-design를 꽤 좋아합니다. 단순히 편한 수준이 아니라, 좋은 개발 습관과 구조를 도구 안에 녹여놨거든요.
그래서 Codex에게 이걸 분석해서, 비슷한 워크플로우를 Codex 스킬로 만들어 달라고 했습니다.
"I'm writing user-level Codex skills under
~/.codex/skills, using the Claude plugin workflows as the template and adapting them to Codex's skill model where Claude-only features like hooks or plugin commands don't exist."
결과는 꽤 괜찮았어요. 완벽하지는 않았습니다. Claude Code 특유의 개념 중에는 Codex에 그대로 대응되는 게 없는 것도 있었으니까요. 그래도 핵심 워크플로우는 충분히 번역됐습니다. 지금은 같은 설계 철학을 기반으로, 두 도구 모두에서 구조화된 개발 프로세스를 돌리고 있어요.
두 모델이 서로를 리뷰하게 하면 무슨 일이 벌어질까
이번 주에 얻은 가장 값진 발견은 아마 이거예요.
GPT-5.4가 만든 계획을 Opus 4.6이 비판적으로 리뷰하고, 그 수정본을 다시 GPT-5.4가 리뷰하게 하는 식으로 몇 차례 왕복시키면, 어느 한 모델이 혼자 만든 계획보다 훨씬 더 좋아집니다.
두 모델은 서로 다른 약점을 찾아요. Opus는 아키텍처 불일치와 에러 핸들링의 엣지 케이스를 잘 잡는 편이고, GPT-5.4는 과도한 설계를 줄이고 더 단순한 접근을 제안하는 편입니다. 서로의 블라인드 스팟이 달라요.
그래서 저는 이제 조금이라도 비중 있는 구현 계획이라면 이렇게 합니다. 한 도구로 초안을 만들고, 다른 도구로 리뷰하고, 다시 수정하고, 또 리뷰하는 식으로요. 두세 번만 왕복해도 최종 계획이 훨씬 더 탄탄해지고, 어느 한 모델만 썼다면 놓쳤을 문제까지 잡힙니다.
지금 AI 코딩 도구를 하나만 쓰고 있다면, 품질 면에서 놓치고 있는 게 있다고 생각해요. 어느 쪽이 나빠서가 아닙니다. 둘 다 정말 훌륭해요. 다만 사고 방식이 다르고, 다른 사고 방식은 다른 문제를 잡아냅니다.
한 도구가 다운되면 어떻게 될까
3월 11일, Claude Code에는 오류가 증가하는 구간이 있었습니다. 로그인 문제, 느린 성능, 간헐적 실패. 몇 시간 동안은 사실상 쓰기 어려운 상태였어요.
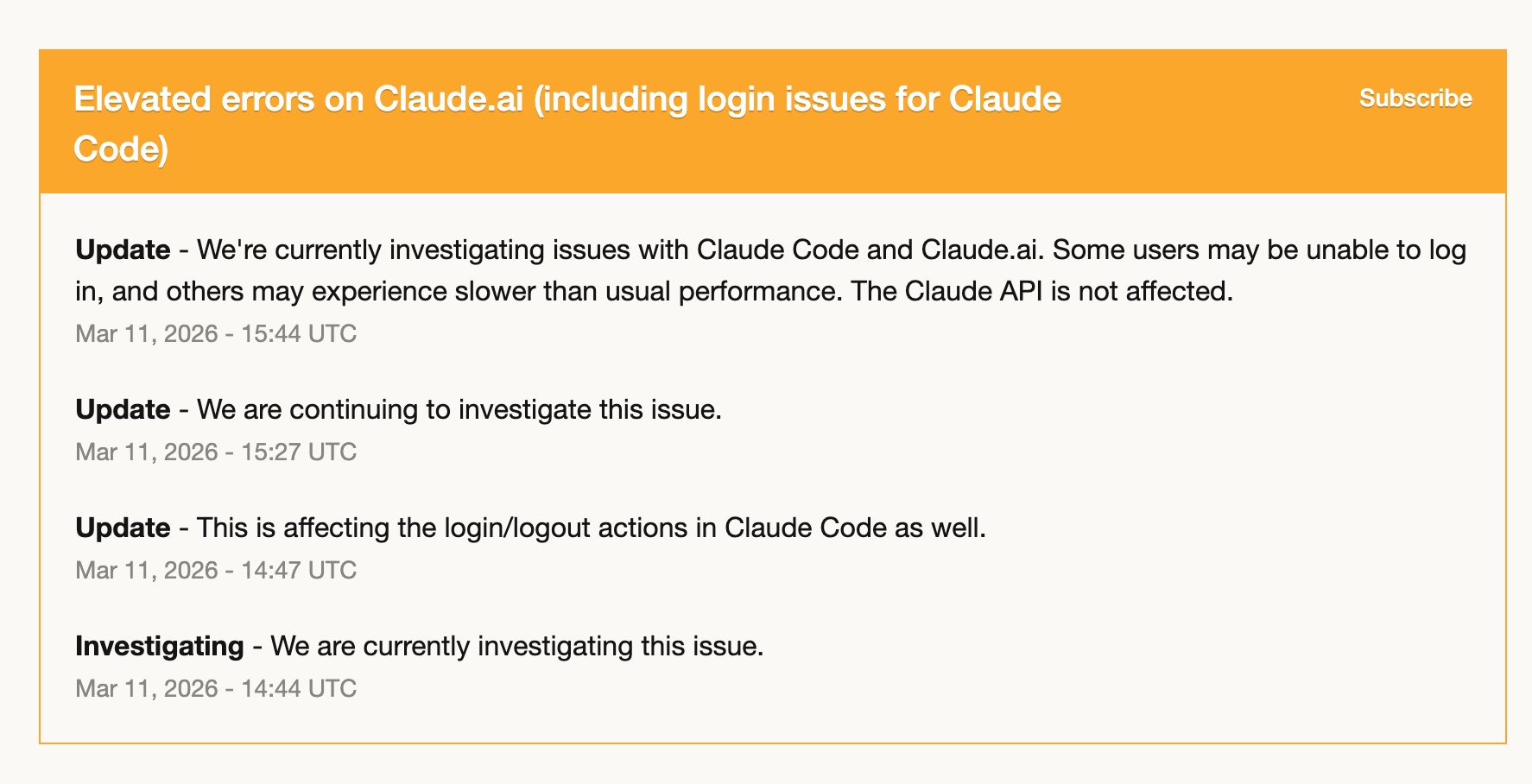
그런데 저는 이미 Codex 쪽 준비를 어느 정도 해둔 상태였어요. 그래서 거의 바로 전환할 수 있었습니다. Codex 스킬도 있었고, 워크플로우도 옮겨둔 상태였고, GPT-5.4는 충분히 일을 해냈어요.
이 경험이 하나를 분명하게 해줬습니다. 하나의 도구에만 전적으로 의존하는 건 리스크다라는 점이에요. 도구가 불안정해서가 아닙니다. Claude Code는 지난 1년 동안 꽤 안정적이었어요. 다만 어떤 서비스든 안 좋은 날은 있을 수 있습니다. 진짜로 익숙하게 쓸 수 있는 두 번째 도구를 갖고 있다는 건 사치가 아니라, 운영 레질리언스입니다.
한눈에 보는 Claude Code vs. Codex
| 항목 | Claude Code (Opus 4.6) | Codex (GPT-5.4) |
|---|---|---|
| 실행 품질 | 더 깊다 — 빈틈을 찾고 우선순위를 잡아준다 | 좋다 — 작업은 끝내지만 선제적 분석은 덜하다 |
| 자동 QA | 내장되어 있고 리뷰 에이전트를 자동 디스패치한다 | 아직 없다 — 수동 검증이 필요하다 |
| 병렬 에이전트 | 성숙했다 — 5~6개를 조율해 돌릴 수 있다 | 유망하다 — 작동은 하지만 덜 매끄럽다 |
| 아키텍처 추론 | medium thinking에서 강하다 | high thinking에서 매우 강하다 — 리프레이밍이 빠르다 |
| 지속적인 계획 실행 | 좋다 | 인상적이다 — 46분 이상 연속 실행 가능 |
| 컨텍스트 압축 | 더 느리다 | 더 빠르다 — 좋고 나쁨은 아직 판단 중 |
| 대규모 현지화 | Opus 4.6 medium과 동급 | 동급 — 현재는 비용 면에서 유리 |
| 플러그인/스킬 생태계 | 성숙했다 (Superpowers, /feature-dev 등) | 성장 중 — Claude 워크플로우를 이식할 수 있다 |
| 크로스 모델 리뷰 | 엣지 케이스와 불일치를 잘 잡는다 | 과한 설계를 줄이고 단순화를 제안한다 |
| 비용 | 월 $100~200 | 무료 1개월 프로모, 이후는 미정 |
몇 가지 추가 관찰
컨텍스트 관리: Codex는 컨텍스트 윈도우가 차기 시작하면 더 빨리 압축하는 것처럼 보입니다. 이게 더 좋은지 나쁜지는 아직 결론을 못 내렸어요. 다만 Claude Code와는 분명히 다르게 느껴집니다.
대규모 현지화: 저는 Claude Code와 Opus 4.6으로 12개 언어, 390만 단어를 번역했습니다. GPT-5.4의 번역 품질은 Opus 4.6 medium thinking과 거의 동급입니다. 그리고 적어도 지금은, 대규모 작업을 돌리기에 제겐 더 저렴합니다. 그래서 최근에는 대량 현지화 작업을 GPT-5.4 쪽으로 조금씩 옮기고 있어요. 이 비용 우위가 얼마나 오래 갈지는 모르겠지만, 유지되는 동안엔 그걸 활용하는 게 맞다고 봅니다.
비용: 저는 지금 Claude Code의 월 $200 Max 플랜을 쓰고 있습니다. 그런데 Codex가 특히 현지화 작업에서 꽤 많은 비중을 가져가기 시작하면서, $100 티어로 낮추는 것도 고민 중이에요. OpenAI의 무료 1개월은 이 전환을 시험하기에 좋습니다. 정가 기준으로 가더라도, 하나를 최대치로 돌리는 것보다 둘을 나눠 쓰는 편이 더 효율적일 수 있어요.
지금 제 결론
일주일 동안 진짜로 두 도구를 함께 써본 뒤, 제 현재 모델은 이렇습니다.
Claude Code를 꺼내야 할 때: 구현 품질 그 자체가 중요하고, 자동 QA가 필요할 때. 복잡한 병렬 에이전트 조율이 필요할 때. 큰 코드베이스에서 긴 시간 동안 일관성을 유지해야 할 때. 또는 그 프로젝트가 이미 Superpowers 워크플로우를 갖춘 경우.
Codex를 꺼내야 할 때: 새로운 아키텍처 관점이 필요할 때. 어려운 추론 문제에 high thinking을 쓰고 싶을 때. 잘 정의된 계획을 끊기지 않고 오래 실행해야 할 때. 혹은 Claude Code가 상태가 안 좋은 날.
둘 다 써야 할 때: 조금이라도 비자명한 구현 계획일 때. 한 도구로 초안을 만들고, 다른 도구로 리뷰하세요. 크로스 모델 리뷰 루프는 지금까지 제가 찾은 것 중 가장 강력한 워크플로우입니다.
저는 Claude Code를 버릴 생각이 없습니다. 여전히 제 주력 도구고, 가장 익숙한 생태계예요. 하지만 이제는 단일 도구 개발자도 아닙니다. GPT-5.4는 단순한 백업이 아니라, 실제 능력으로 제 워크플로우 안에 자리를 얻었습니다.
AI 보조 개발의 미래는 승자를 하나 고르는 데 있지 않다고 생각해요. 어떤 상황에서 어떤 도구를 꺼내야 하는지 아는 것. 그리고 더 중요하게는, 둘을 함께 쓸 때가 따로 쓸 때보다 더 강하다는 걸 이해하는 데 있다고 봅니다.
자주 받는 질문
코딩에서 GPT-5.4가 Opus 4.6보다 더 좋은가
어느 한쪽이 절대적으로 더 낫다고 보긴 어렵습니다. GPT-5.4의 high thinking은 아키텍처 추론과 긴 계획 실행에서 강해요. 반면 Opus 4.6은 실행 품질, 선제적 갭 분석, 긴 세션에서의 일관성에서 강합니다. 가장 좋은 결과는 두 모델이 서로의 작업을 리뷰하게 할 때 나옵니다.
Claude Code에서 Codex로 갈아타야 하나
완전한 전환은 추천하지 않습니다. 두 도구 모두 분명한 강점이 있어요. Claude Code의 자동 QA와 병렬 에이전트 오케스트레이션은 실제로 한 단계 앞서 있고, Codex의 지속 실행 능력과 GPT-5.4의 어려운 문제에 대한 추론도 꽤 인상적입니다. 둘을 함께 쓰는 쪽이 제일 좋았습니다.
크로스 모델 리뷰는 추가 노력의 가치가 있나
비자명한 계획이라면 확실히 있습니다. Opus는 GPT-5.4의 결과에서 엣지 케이스와 불일치를 잘 잡고, GPT-5.4는 과잉 설계를 줄여줍니다. 두세 번만 왕복해도 어느 한 모델만 쓴 계획보다 훨씬 더 탄탄해집니다.
두 도구를 같이 쓰면 비용은 얼마나 드나
Claude Code는 플랜에 따라 월 $100~200입니다. Codex 가격은 변동이 있지만, OpenAI가 지금 무료 1개월 프로모를 제공하고 있습니다. 정가로 가더라도, 하나를 최대치로 돌리는 것보다 두 도구를 나눠 쓰는 편이 더 비용 효율적일 수 있습니다.
Claude Code 플러그인을 Codex에서 그대로 쓸 수 있나
그대로는 안 됩니다. 하지만 적응시킬 수는 있어요. 저는 Claude Code의 플러그인 워크플로우(/feature-dev, /code-review, /superpowers)를 Codex에게 분석시키고, 그 핵심 로직을 ~/.codex/skills 아래 Codex 스킬로 옮겼습니다. hooks 같은 Claude 전용 기능은 그대로 옮길 수 없지만, 워크플로우 자체는 충분히 번역됩니다.
여기까지가 제 현재 결론입니다. 솔직히 좀 궁금해요. 다른 분들도 멀티 모델 워크플로우를 돌리고 계신가요? Claude Code와 Codex를 같이 쓰든, 다른 조합이든요. 어떤 패턴이 잘 먹히고 있나요?
그럼 이만, Chandler





