Codex 配搭 GPT-5.4 vs Claude Code 配搭 Opus 4.6——點解我而家兩個都用
我幾乎用咗成一年 Claude Code 配 Opus 4.6,之後再花一個星期試 Codex 同 GPT-5.4。結論係:冇邊個可以完全勝出。真正更好嘅做法,係將兩個一齊用——做跨模型 review、食盡互補優勢,同埋建立操作層面嘅韌性。
我幾乎成一年每日都用 Claude Code。之後我花咗一個星期試 Codex 同 GPT-5.4。冇邊個可以徹底贏晒——但將佢哋兩個一齊用,互相 review,出嚟嘅結果的確比單獨用任何一個都更好。 呢個就係我作為一個真係用佢哋 ship 過產品嘅人,最後落到嘅判斷。
過去一段時間,我基本上所有開發工作都係用 Claude Code 配 Opus 4.6 去做:重建呢個網站、將 DIALØGUE(對話)推上 App Store、build STRAŦUM、喺 12 種語言翻譯 390 萬個字,同埋整一套完整課程影片 pipeline,入面有 18 種 layout 同按字級別做 audio sync。
所以當 OpenAI 喺 3 月 5 日推出 配搭 GPT-5.4 嘅 Codex 嘅時候,我唔係想搵替代品。我純粹係好奇。再加上 OpenAI 嗰陣有一個免費試用月,令我幾乎零成本咁跳入去試。
結果我有啲意外。唔止係「原來都唔錯喎」嗰種意外——而係真心覺得,Codex 配 GPT-5.4 嘅能力比我原本預期強好多。
一個星期之後,我冇打算轉陣營。我而家係雙持。而且我覺得,兩個夾埋就真係比單獨用任何一個都更好。
點解 “harness” 同 “model” 嘅分別咁重要?
未入正題之前,我想先講一個我覺得大部分比較文都忽略咗嘅細節。
Claude Code 同 Codex 係 harness。 即係 CLI 工具、agent 編排方式、plugin 生態、context 管理,同埋佢哋點樣同檔案系統同 terminal 互動。Opus 4.6 同 GPT-5.4 先係底層 model。 真正負責判斷做乜、點推理、寫乜 code 嘅,係 model。
呢點好重要,因為我下面好多觀察,有啲係講 harness,有啲係講 model。Claude Code 會自動派 QA agent、管理平行 agent,呢啲係 harness。GPT-5.4 喺我嗰個 fragment sync 問題上畀到架構層面嘅洞察,呢啲係 model。至於我話跨模型 review 會令計劃更好,嗰個其實係講 模型之間 推理方式唔同,而 harness 只係將結果送到你面前。
一個更強嘅 model,放喺一個較差嘅 harness 入面,依然可能令人用得好痛苦。相反,一個好好嘅 harness 配上一個較弱嘅 model,又可能睇落好 polished,但唔夠深。 而家呢兩個組合都好強,只係強喺唔同地方。
Codex 配 GPT-5.4 第一次上手係咩感覺?
老實講——我原本以為 Codex 會令我明顯覺得係「降級」。因為我已經喺 Claude Code 生態入面浸得好深:Superpowers plugin、平行 agent 派發、實作完之後自動跑 code review agent。嗰套 workflow 已經相當成熟。
但 Codex 配 GPT-5.4 一上手就令我覺得,佢真係有料。Model 好強,推理好穩,跟計劃嘅能力都好好。當我畀佢一份結構清晰嘅 implementation plan,佢可以連續做 45 分鐘以上都唔散——commit、test、push,然後再做下一步。
我好早就開咗 Codex 幾個 experimental feature:
- Multi-agents —— 平行處理任務,感覺上有啲似 Claude Code 嘅 agent dispatch
- JavaScript REPL —— 持久化 Node runtime,適合做 inline debugging
- Prevent sleep while running —— 長任務執行期間唔畀部機瞓覺
呢幾樣都幾有幫助。尤其係 multi-agent,第一次令我覺得 Codex 正喺追近我已經好習慣依賴嘅一種工作方式。
GPT-5.4 喺邊度明顯贏過 Opus 4.6?
我都要承認——有一個領域,GPT-5.4 的確明顯贏過 Opus 4.6,而且唔係小勝。
我最近一直喺做一套課程影片 pipeline,要將有旁白嘅音頻同 slide fragment 同步。難點其實唔係時間戳——ElevenLabs 會俾到按字級別嘅時間資訊。真正難嘅地方係 對齊:即係當講者開始講某個點嘅時候,畫面上究竟應該出現邊個 fragment。
問題係,speaker notes 通常唔會逐字重複 slide 上面嘅文字。有時旁白係改寫 bullet,有時會將兩個 bullet 合成一句,有時某個 bullet 雖然喺 slide 上,但其實唔算真係講過。所以系統一直都只可以靠 keyword 去估。估得準嗰陣睇落都幾似模似樣,但一遇到複雜啲嘅 slide,就會開始散。
Opus 4.6 用 medium thinking 連續試咗幾輪。佢不停提出越嚟越聰明嘅 heuristic:按文字長度平均切、喺時間戳搵 keyword、按句子做 matching、雙策略 matching……每一版都比上一版好啲,但本質上都仲困喺同一個框架。
而 GPT-5.4 喺 high thinking 底下一眼睇中真正問題:呢件事根本唔應該當 keyword matching 問題處理,而係應該當作 data model 問題。 renderer 應該輸出真正嘅 fragment state;assembler 應該按呢啲 state 去對齊旁白;validation 則應該標示出「視覺結構」同「旁白結構」唔匹配嘅 slide。
呢個就係正確嘅洞察。由「靠文字去估同步」轉成「將同步變成 pipeline 入面嘅一等公民」,正正係呢個問題真正需要嘅架構重構。而 GPT-5.4 比 Opus 更快行到呢一步。
Claude Code 依然贏喺邊?
不過問題就係——架構洞察,同埋執行質量同收尾能力,根本唔係同一回事。
執行質量
最典型嘅例子係:我叫兩個工具都去 audit 同改進 7 個課程模組嘅 companion notes。Codex 返嚟話我知,個任務已經做完。
Claude Code 返嚟畀我嘅係呢個:
審核完成——全部 7 個模組
第一層:修好而家 15 條偏薄嘅 companion notes(先補到合格線,係最快見效嘅 quick win)
第二層:為大約 25-30 張高優先次序 slide 補 companion notes(核心 framework、工具清單、多步驟流程、密集數據頁)
呢個就唔係「做完咗」咁簡單。呢個係一份有層次嘅 gap analysis,將大約 40-45 張需要處理嘅 slide 按優先次序拆開。「我做完個任務」同「我做完個任務,而且呢啲係我發現嘅問題」之間,差距其實好大。 真正要 ship 產品嗰陣,呢個差距好關鍵。
自動 QA
呢個係 Claude Code 嘅 killer feature,我真心覺得大家講得太少。完成一段 implementation 之後,Claude Code 會自動派 QA agent——做 code review、narrative review、一致性檢查——而且唔使我再額外開口。呢個係工具本身 built-in 嘅。
Codex 而家仲未有呢一層。Codex 話「做完」,你就要自己驗,或者自己額外搭一層 review 流程。Claude Code 就直接將 verification 併入 workflow 入面。呢個設計真係好聰明。
平行代理管理
Claude Code 嘅 agent 編排都成熟得多。佢會派多個專門 agent,管理佢哋嘅結果,再將結論綜合成一份清晰摘要。我試過唔少 session 同時跑 5-6 個 agent——explorer、code reviewer、implementation agent、test runner——最後都可以被統一協調起嚟。
Codex 嘅 multi-agent 好有前景,但明顯仲早期啲。係用到,但協調感仲未去到咁順。
一致性
喺嗰啲時間拉得好長、要處理好多移動部件嘅任務入面——例如跨 7 個模組整 18 種課程 layout——Claude Code 喺維持一致性方面做得更好。設計 token 唔會亂、命名慣例守得住、第一個鐘做咗嘅架構決定,到第四個鐘通常仲會被尊重。
可唔可以將一個工具嘅 workflow,搬去另一個工具?
呢個係我今個星期一個好意外嘅發現:你完全可以用 Codex 去研究 Claude Code 嘅 plugin 生態,再將佢哋改造成適用於 Codex 嘅嘢。
我自己尤其鍾意幾個 Claude Code plugin:功能開發 workflow(/feature-dev)、code review 系統(/code-review)、code simplifier(/code-simplifier)、Superpowers 規劃框架(/superpowers),同埋前端設計 skill(/frontend-design)。呢啲唔係「功能堆砌」,而係將最佳實踐編進工具入面。
所以我就叫 Codex 去研究佢哋,再為 Codex 寫出等價嘅 skills:
“I'm writing user-level Codex skills under
~/.codex/skills, using the Claude plugin workflows as the template and adapting them to Codex's skill model where Claude-only features like hooks or plugin commands don't exist.”
結果係做得到。唔算完美——畢竟有啲 Claude Code 概念喺 Codex 入面冇直接對應——但核心 workflow 係搬得過去嘅。而家我喺兩個工具入面,都可以用到基於同一套設計哲學嘅結構化開發流程。
當你用兩個 model 互相審對方嘅 plan,會發生咩事?
我覺得呢個可能係今個星期最有價值嘅發現。
先叫 Opus 4.6 嚴格 review GPT-5.4 寫嘅 plan,再叫 GPT-5.4 去 review Opus 修過嘅版本——咁樣來回跑幾輪,最後出嚟嘅結果明顯比單獨用任何一個 model 都更好。
因為佢哋擅長發現嘅弱點唔一樣。Opus 往往比較容易捉到架構唔一致同 error handling 嘅邊角位。GPT-5.4 往往更容易指出 over-engineering,然後提出更簡單嘅做法。兩邊正正互補彼此嘅盲點。
而家只要係稍微複雜啲嘅 implementation plan,我基本上都會咁做:先喺一個工具入面起草,再俾另一個去 review,再改,再 review。來回兩三輪。最後出嚟嘅 plan 會更緊、更穩,仲會捉到好多單靠一個 model 根本冇冒出嚟嘅問題。
如果你而家淨係用一個 AI coding tool,我覺得你其實係將一部分質量留喺枱面。唔係因為單個工具唔好——佢哋兩個其實都已經好好——而係因為佢哋嘅推理方式真係唔一樣,而唔同嘅推理方式就會捉到唔同問題。
當其中一個工具掛咗,會發生咩事?
3 月 11 日,Claude Code 出現咗一段時間高錯誤率——登入問題、效能變慢、間歇性失敗。嗰幾個鐘入面,基本上係用唔到。
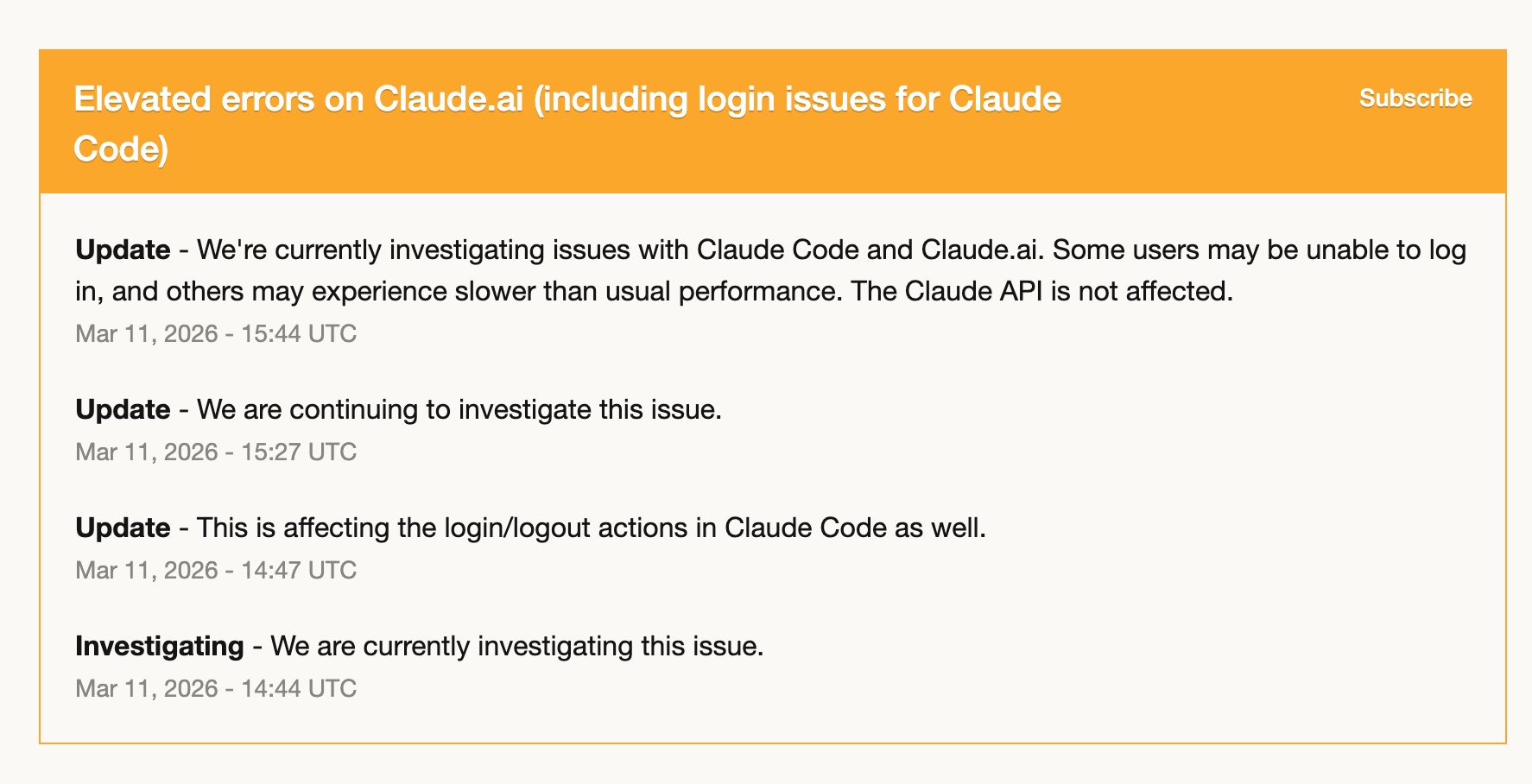
因為嗰時我已經開始逐步將 Codex workflow 搭起嚟,所以嗰段時間我幾乎完全切咗去用 Codex。而且我完全可以繼續工作。我已經將 Codex skills 配好,常用 workflow 亦都搬咗過去,GPT-5.4 足夠穩定咁接住我手上嘅工作。
嗰次經歷令我更肯定一件事:將自己完全綁死喺一個工具上,其實係有風險。 唔係因為個工具唔可靠——我呢一年用落嚟,Claude Code 其實已經相當穩定——而係任何服務都可能有一日狀態唔對。真正熟練掌握第二個工具,唔係奢侈品,而係一種操作層面嘅韌性。
Claude Code vs. Codex:快速比較
| 維度 | Claude Code(Opus 4.6) | Codex(GPT-5.4) |
|---|---|---|
| 執行質量 | 更深——會主動發現缺口、幫你排優先次序 | 唔錯——做得完任務,但主動分析較少 |
| 自動 QA | 內建,會自動派 review agent | 目前未有——需要手動驗證 |
| 平行 agents | 成熟——可以協調 5-6 個 agent | 好有前景——用到,但未算好順 |
| 架構推理 | medium thinking 已經好強 | high thinking 特別強——更快完成重構式思考 |
| 持續執行計劃 | 好 | 好勁——可以穩定連續跑好耐 |
| context 壓縮 | 較慢 | 更快——只係唔同,未必一定更好 |
| 大規模 localization | 好強(Opus 4.6 medium) | 一樣好強——目前對我嚟講仲更平 |
| plugin / skill 生態 | 更成熟(Superpowers、/feature-dev 等) | 正喺成長——但可以吸收 Claude workflow |
| 跨模型 review | 擅長捉邊角問題同不一致 | 擅長捉 over-engineering 同提出簡化 |
| 成本 | $100-200/月 | 而家有免費試用月,之後待定 |
仲有幾點補充觀察
context 管理:Codex 喺 context window 滿咗之後,壓縮 context 嘅速度明顯快啲。呢樣到底係優點定缺點,我仲未完全有結論——只係佢同 Claude Code 嘅處理方式真係唔同。
大規模 localization:我之前用 Claude Code 配 Opus 4.6 喺 12 種語言翻譯咗 390 萬個字。而 GPT-5.4 嘅翻譯質量,大致同 Opus 4.6 medium thinking 差唔多——但至少而家,對我嚟講大規模跑起上嚟更平。所以最近我已經開始將批量 localization 工作逐步轉去 GPT-5.4。呢個成本優勢會維持幾耐我唔知,但只要仲喺度,我覺得就值得用。
成本:我而家用緊 Claude Code 嘅 $200/月 Max plan。既然 Codex 已經開始接走我相當一部分工作量——尤其係 localization——我正喺考慮係咪可以降返去 $100 嗰個 tier。OpenAI 呢次免費試用月令過渡輕鬆咗好多,但就算恢復原價,將 workload 分散喺兩個工具嘅較低 tier 上,可能依然比喺一個工具上沖到最盡更划算。
我而家嘅結論
真真正正雙持用咗一個星期之後,我而家個工作模型大概係咁:
優先用 Claude Code 嘅情況:你需要高執行質量,而且最好自帶 QA;你需要複雜嘅多 agent 編排;你需要喺大型項目入面長時間維持一致性;或者你正喺一個已經搭好 Superpowers workflow 嘅 project 入面工作。
優先用 Codex 嘅情況:你需要一個新嘅架構視角;你喺一個好難嘅推理問題上想開 high thinking;你要執行一份定義清楚、適合持續推進嘅計劃;或者啱啱好 Claude Code 今日狀態麻麻。
兩個一齊用嘅情況:任何稍為複雜啲嘅 implementation plan。先喺一個工具入面起草,再交俾另一個去 review。呢個跨模型 review loop,真係我今個星期搵到最好嘅 workflow。
我冇放棄 Claude Code——佢依然係我嘅主工具,亦都係我最熟悉嘅生態。但我已經唔再係一個「單工具開發者」。GPT-5.4 係靠真實能力,而唔係靠「後備工具」呢個身份,先喺我嘅 workflow 入面攞到一個正式位置。
AI 輔助開發嘅未來,我覺得唔係「揀出唯一贏家」。而係知道邊個時候應該攞邊個工具出嚟。更重要嘅係,承認一件事:呢啲工具擺埋一齊,真係比單獨用其中一個更勁。
常見問題
GPT-5.4 喺寫 code 上比 Opus 4.6 更強?
我唔會咁簡單咁講邊個絕對更強。GPT-5.4 喺 high thinking 底下,架構推理同持續執行計劃嘅能力好突出。Opus 4.6 喺執行質量、主動發現缺口、同埋長 session 入面維持一致性方面依然更強。真正最好嘅結果,通常係靠兩個 model 互相 review 對方嘅工作。
我應唔應該由 Claude Code 轉去 Codex?
我唔建議徹底轉。兩邊都有好明顯、而且互補嘅優勢——Claude Code 嘅自動 QA 同平行 agent 編排的確領先,而 Codex 嘅持續執行能力,以及 GPT-5.4 喺難題上嘅推理能力,亦都真係好強。雙持先係我而家覺得最合理嘅做法。
跨模型 review 值唔值得多花啲工夫?
如果計劃稍微複雜啲,我覺得絕對值。叫 Opus 去 review GPT-5.4 嘅輸出,再叫 GPT-5.4 去 review Opus 修過嘅版本,會捉到完全唔同類型嘅問題——Opus 會捉邊角位同不一致,GPT-5.4 會捉過度設計。兩三輪之後出嚟嘅 plan,明顯比只靠一個 model 更緊更穩。
雙工具組合一個月大概要幾錢?
Claude Code 視乎 plan,大概係 $100-200/月。Codex 嘅價格而家仲變動中——OpenAI 目前提供咗一個免費試用月。就算恢復正常價格,將 workload 拆落兩個工具嘅較低 tier 上,可能依然比喺一個工具上開滿配更划算。
Claude Code 嘅 plugin 可以直接喺 Codex 用?
唔可以直接用,但可以改。我就係叫 Codex 去研究 Claude Code 嘅 plugin workflow(例如 /feature-dev、/code-review、/superpowers),再將核心邏輯翻譯成 Codex skills,放喺 ~/.codex/skills 入面。好似 hooks 呢類 Claude 專屬功能,未必可以照搬,但 workflow 本身係搬得到。
差唔多就係咁。我反而幾好奇——而家有冇其他人都喺跑多模型 workflow?會一齊用 Claude Code 同 Codex,或者其他組合?你哋目前摸索到啲咩 pattern?
下次再傾, Chandler





